 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut of Distribution Detection in Self-adaptive Robots with AI-powered Digital Twins
Sep 16, 2025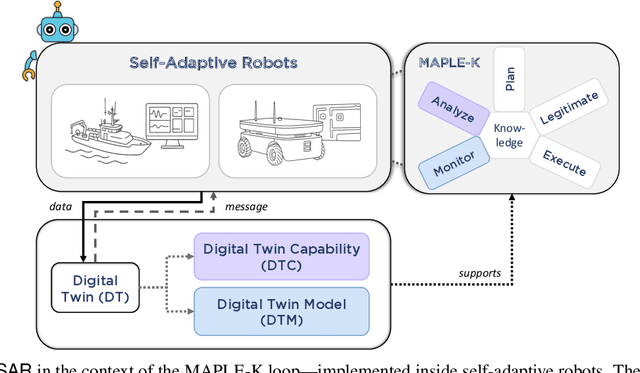



Self-adaptive robots (SARs) in complex, uncertain environments must proactively detect and address abnormal behaviors, including out-of-distribution (OOD) cases. To this end, digital twins offer a valuable solution for OOD detection. Thus, we present a digital twin-based approach for OOD detection (ODiSAR) in SARs. ODiSAR uses a Transformer-based digital twin to forecast SAR states and employs reconstruction error and Monte Carlo dropout for uncertainty quantification. By combining reconstruction error with predictive variance, the digital twin effectively detects OOD behaviors, even in previously unseen conditions. The digital twin also includes an explainability layer that links potential OOD to specific SAR states, offering insights for self-adaptation. We evaluated ODiSAR by creating digital twins of two industrial robots: one navigating an office environment, and another performing maritime ship navigation. In both cases, ODiSAR forecasts SAR behaviors (i.e., robot trajectories and vessel motion) and proactively detects OOD events. Our results showed that ODiSAR achieved high detection performance -- up to 98\% AUROC, 96\% TNR@TPR95, and 95\% F1-score -- while providing interpretable insights to support self-adaptation.
Evaluating Uncertainty and Quality of Visual Language Action-enabled Robots
Jul 22, 2025Visual Language Action (VLA) models are a multi-modal class of Artificial Intelligence (AI) systems that integrate visual perception, natural language understanding, and action planning to enable agents to interpret their environment, comprehend instructions, and perform embodied tasks autonomously. Recently, significant progress has been made to advance this field. These kinds of models are typically evaluated through task success rates, which fail to capture the quality of task execution and the mode's confidence in its decisions. In this paper, we propose eight uncertainty metrics and five quality metrics specifically designed for VLA models for robotic manipulation tasks. We assess their effectiveness through a large-scale empirical study involving 908 successful task executions from three state-of-the-art VLA models across four representative robotic manipulation tasks. Human domain experts manually labeled task quality, allowing us to analyze the correlation between our proposed metrics and expert judgments. The results reveal that several metrics show moderate to strong correlation with human assessments, highlighting their utility for evaluating task quality and model confidence. Furthermore, we found that some of the metrics can discriminate between high-, medium-, and low-quality executions from unsuccessful tasks, which can be interesting when test oracles are not available. Our findings challenge the adequacy of current evaluation practices that rely solely on binary success rates and pave the way for improved real-time monitoring and adaptive enhancement of VLA-enabled robotic systems.
Software Engineering for Self-Adaptive Robotics: A Research Agenda
May 26, 2025Self-adaptive robotic systems are designed to operate autonomously in dynamic and uncertain environments, requiring robust mechanisms to monitor, analyse, and adapt their behaviour in real-time. Unlike traditional robotic software, which follows predefined logic, self-adaptive robots leverage artificial intelligence, machine learning, and model-driven engineering to continuously adjust to changing operational conditions while ensuring reliability, safety, and performance. This paper presents a research agenda for software engineering in self-adaptive robotics, addressing critical challenges across two key dimensions: (1) the development phase, including requirements engineering, software design, co-simulation, and testing methodologies tailored to adaptive robotic systems, and (2) key enabling technologies, such as digital twins, model-driven engineering, and AI-driven adaptation, which facilitate runtime monitoring, fault detection, and automated decision-making. We discuss open research challenges, including verifying adaptive behaviours under uncertainty, balancing trade-offs between adaptability, performance, and safety, and integrating self-adaptation frameworks like MAPE-K. By providing a structured roadmap, this work aims to advance the software engineering foundations for self-adaptive robotic systems, ensuring they remain trustworthy, efficient, and capable of handling real-world complexities.
Search-Based Software Engineering in the Landscape of AI Foundation Models
May 26, 2025Search-based software engineering (SBSE), at the intersection of artificial intelligence (AI) and software engineering, has been an active area of research for about 25 years. It has been applied to solve numerous problems across the entire software engineering lifecycle and has demonstrated its versatility in multiple domains. With the recent advancements in AI, particularly the emergence of foundation models (FMs), the evolution of SBSE alongside FMs remains undetermined. In this window of opportunity, we propose a research roadmap that articulates the current landscape of SBSE in relation to foundation models (FMs), highlights open challenges, and outlines potential research directions for advancing SBSE through its interplay with FMs. This roadmap aims to establish a forward-thinking and innovative perspective for the future of SBSE in the era of FMs.
Identifying Uncertainty in Self-Adaptive Robotics with Large Language Models
Apr 29, 2025Future self-adaptive robots are expected to operate in highly dynamic environments while effectively managing uncertainties. However, identifying the sources and impacts of uncertainties in such robotic systems and defining appropriate mitigation strategies is challenging due to the inherent complexity of self-adaptive robots and the lack of comprehensive knowledge about the various factors influencing uncertainty. Hence, practitioners often rely on intuition and past experiences from similar systems to address uncertainties. In this article, we evaluate the potential of large language models (LLMs) in enabling a systematic and automated approach to identify uncertainties in self-adaptive robotics throughout the software engineering lifecycle. For this evaluation, we analyzed 10 advanced LLMs with varying capabilities across four industrial-sized robotics case studies, gathering the practitioners' perspectives on the LLM-generated responses related to uncertainties. Results showed that practitioners agreed with 63-88% of the LLM responses and expressed strong interest in the practicality of LLMs for this purpose.
Digital Twin-based Out-of-Distribution Detection in Autonomous Vessels
Apr 28, 2025An autonomous vessel (AV) is a complex cyber-physical system (CPS) with software enabling many key functionalities, e.g., navigation software enables an AV to autonomously or semi-autonomously follow a path to its destination. Digital twins of such AVs enable advanced functionalities such as running what-if scenarios, performing predictive maintenance, and enabling fault diagnosis. Due to technological improvements, real-time analyses using continuous data from vessels' real-time operations have become increasingly possible. However, the literature has little explored developing advanced analyses in real-time data in AVs with digital twins built with machine learning techniques. To this end, we present a novel digital twin-based approach (ODDIT) to detect future out-of-distribution (OOD) states of an AV before reaching them, enabling proactive intervention. Such states may indicate anomalies requiring attention (e.g., manual correction by the ship master) and assist testers in scenario-centered testing. The digital twin consists of two machine-learning models predicting future vessel states and whether the predicted state will be OOD. We evaluated ODDIT with five vessels across waypoint and zigzag maneuvering under simulated conditions, including sensor and actuator noise and environmental disturbances i.e., ocean current. ODDIT achieved high accuracy in detecting OOD states, with AUROC and TNR@TPR95 scores reaching 99\% across multiple vessels.
A Machine Learning-Based Error Mitigation Approach For Reliable Software Development On IBM'S Quantum Computers
Apr 19, 2024



Quantum computers have the potential to outperform classical computers for some complex computational problems. However, current quantum computers (e.g., from IBM and Google) have inherent noise that results in errors in the outputs of quantum software executing on the quantum computers, affecting the reliability of quantum software development. The industry is increasingly interested in machine learning (ML)--based error mitigation techniques, given their scalability and practicality. However, existing ML-based techniques have limitations, such as only targeting specific noise types or specific quantum circuits. This paper proposes a practical ML-based approach, called Q-LEAR, with a novel feature set, to mitigate noise errors in quantum software outputs. We evaluated Q-LEAR on eight quantum computers and their corresponding noisy simulators, all from IBM, and compared Q-LEAR with a state-of-the-art ML-based approach taken as baseline. Results show that, compared to the baseline, Q-LEAR achieved a 25% average improvement in error mitigation on both real quantum computers and simulators. We also discuss the implications and practicality of Q-LEAR, which, we believe, is valuable for practitioners.
EpiTESTER: Testing Autonomous Vehicles with Epigenetic Algorithm and Attention Mechanism
Nov 30, 2023Testing autonomous vehicles (AVs) under various environmental scenarios that lead the vehicles to unsafe situations is known to be challenging. Given the infinite possible environmental scenarios, it is essential to find critical scenarios efficiently. To this end, we propose a novel testing method, named EpiTESTER, by taking inspiration from epigenetics, which enables species to adapt to sudden environmental changes. In particular, EpiTESTER adopts gene silencing as its epigenetic mechanism, which regulates gene expression to prevent the expression of a certain gene, and the probability of gene expression is dynamically computed as the environment changes. Given different data modalities (e.g., images, lidar point clouds) in the context of AV, EpiTESTER benefits from a multi-model fusion transformer to extract high-level feature representations from environmental factors and then calculates probabilities based on these features with the attention mechanism. To assess the cost-effectiveness of EpiTESTER, we compare it with a classical genetic algorithm (GA) (i.e., without any epigenetic mechanism implemented) and EpiTESTER with equal probability for each gene. We evaluate EpiTESTER with four initial environments from CARLA, an open-source simulator for autonomous driving research, and an end-to-end AV controller, Interfuser. Our results show that EpiTESTER achieved a promising performance in identifying critical scenarios compared to the baselines, showing that applying epigenetic mechanisms is a good option for solving practical problems.
DeepQTest: Testing Autonomous Driving Systems with Reinforcement Learning and Real-world Weather Data
Oct 08, 2023Autonomous driving systems (ADSs) are capable of sensing the environment and making driving decisions autonomously. These systems are safety-critical, and testing them is one of the important approaches to ensure their safety. However, due to the inherent complexity of ADSs and the high dimensionality of their operating environment, the number of possible test scenarios for ADSs is infinite. Besides, the operating environment of ADSs is dynamic, continuously evolving, and full of uncertainties, which requires a testing approach adaptive to the environment. In addition, existing ADS testing techniques have limited effectiveness in ensuring the realism of test scenarios, especially the realism of weather conditions and their changes over time. Recently, reinforcement learning (RL) has demonstrated great potential in addressing challenging problems, especially those requiring constant adaptations to dynamic environments. To this end, we present DeepQTest, a novel ADS testing approach that uses RL to learn environment configurations with a high chance of revealing abnormal ADS behaviors. Specifically, DeepQTest employs Deep Q-Learning and adopts three safety and comfort measures to construct the reward functions. To ensure the realism of generated scenarios, DeepQTest defines a set of realistic constraints and introduces real-world weather conditions into the simulated environment. We employed three comparison baselines, i.e., random, greedy, and a state-of-the-art RL-based approach DeepCOllision, for evaluating DeepQTest on an industrial-scale ADS. Evaluation results show that DeepQTest demonstrated significantly better effectiveness in terms of generating scenarios leading to collisions and ensuring scenario realism compared with the baselines. In addition, among the three reward functions implemented in DeepQTest, Time-To-Collision is recommended as the best design according to our study.
Digital Twin-based Anomaly Detection with Curriculum Learning in Cyber-physical Systems
Sep 27, 2023Anomaly detection is critical to ensure the security of cyber-physical systems (CPS). However, due to the increasing complexity of attacks and CPS themselves, anomaly detection in CPS is becoming more and more challenging. In our previous work, we proposed a digital twin-based anomaly detection method, called ATTAIN, which takes advantage of both historical and real-time data of CPS. However, such data vary significantly in terms of difficulty. Therefore, similar to human learning processes, deep learning models (e.g., ATTAIN) can benefit from an easy-to-difficult curriculum. To this end, in this paper, we present a novel approach, named digitaL twin-based Anomaly deTecTion wIth Curriculum lEarning (LATTICE), which extends ATTAIN by introducing curriculum learning to optimize its learning paradigm. LATTICE attributes each sample with a difficulty score, before being fed into a training scheduler. The training scheduler samples batches of training data based on these difficulty scores such that learning from easy to difficult data can be performed. To evaluate LATTICE, we use five publicly available datasets collected from five real-world CPS testbeds. We compare LATTICE with ATTAIN and two other state-of-the-art anomaly detectors. Evaluation results show that LATTICE outperforms the three baselines and ATTAIN by 0.906%-2.367% in terms of the F1 score. LATTICE also, on average, reduces the training time of ATTAIN by 4.2% on the five datasets and is on par with the baselines in terms of detection delay time.