 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanGu-$π$: Enhancing Language Model Architectures via Nonlinearity Compensation
Dec 27, 2023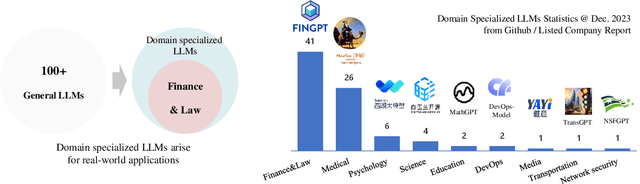

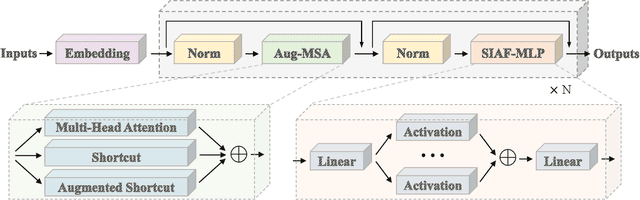

The recent trend of large language models (LLMs) is to increase the scale of both model size (\aka the number of parameters) and dataset to achieve better generative ability, which is definitely proved by a lot of work such as the famous GPT and Llama. However, large models often involve massive computational costs, and practical applications cannot afford such high prices. However, the method of constructing a strong model architecture for LLMs is rarely discussed. We first analyze the state-of-the-art language model architectures and observe the feature collapse problem. Based on the theoretical analysis, we propose that the nonlinearity is also very important for language models, which is usually studied in convolutional neural networks for vision tasks. The series informed activation function is then introduced with tiny calculations that can be ignored, and an augmented shortcut is further used to enhance the model nonlinearity. We then demonstrate that the proposed approach is significantly effective for enhancing the model nonlinearity through carefully designed ablations; thus, we present a new efficient model architecture for establishing modern, namely, PanGu-$\pi$. Experiments are then conducted using the same dataset and training strategy to compare PanGu-$\pi$ with state-of-the-art LLMs. The results show that PanGu-$\pi$-7B can achieve a comparable performance to that of benchmarks with about 10\% inference speed-up, and PanGu-$\pi$-1B can achieve state-of-the-art performance in terms of accuracy and efficiency. In addition, we have deployed PanGu-$\pi$-7B in the high-value domains of finance and law, developing an LLM named YunShan for practical application. The results show that YunShan can surpass other models with similar scales on benchmarks.
Digital Twin-based Anomaly Detection with Curriculum Learning in Cyber-physical Systems
Sep 27, 2023Anomaly detection is critical to ensure the security of cyber-physical systems (CPS). However, due to the increasing complexity of attacks and CPS themselves, anomaly detection in CPS is becoming more and more challenging. In our previous work, we proposed a digital twin-based anomaly detection method, called ATTAIN, which takes advantage of both historical and real-time data of CPS. However, such data vary significantly in terms of difficulty. Therefore, similar to human learning processes, deep learning models (e.g., ATTAIN) can benefit from an easy-to-difficult curriculum. To this end, in this paper, we present a novel approach, named digitaL twin-based Anomaly deTecTion wIth Curriculum lEarning (LATTICE), which extends ATTAIN by introducing curriculum learning to optimize its learning paradigm. LATTICE attributes each sample with a difficulty score, before being fed into a training scheduler. The training scheduler samples batches of training data based on these difficulty scores such that learning from easy to difficult data can be performed. To evaluate LATTICE, we use five publicly available datasets collected from five real-world CPS testbeds. We compare LATTICE with ATTAIN and two other state-of-the-art anomaly detectors. Evaluation results show that LATTICE outperforms the three baselines and ATTAIN by 0.906%-2.367% in terms of the F1 score. LATTICE also, on average, reduces the training time of ATTAIN by 4.2% on the five datasets and is on par with the baselines in terms of detection delay time.
Knowledge Distillation-Empowered Digital Twin for Anomaly Detection
Sep 12, 2023



Cyber-physical systems (CPSs), like train control and management systems (TCMS), are becoming ubiquitous in critical infrastructures. As safety-critical systems, ensuring their dependability during operation is crucial. Digital twins (DTs) have been increasingly studied for this purpose owing to their capability of runtime monitoring and warning, prediction and detection of anomalies, etc. However, constructing a DT for anomaly detection in TCMS necessitates sufficient training data and extracting both chronological and context features with high quality. Hence, in this paper, we propose a novel method named KDDT for TCMS anomaly detection. KDDT harnesses a language model (LM) and a long short-term memory (LSTM) network to extract contexts and chronological features, respectively. To enrich data volume, KDDT benefits from out-of-domain data with knowledge distillation (KD). We evaluated KDDT with two datasets from our industry partner Alstom and obtained the F1 scores of 0.931 and 0.915, respectively, demonstrating the effectiveness of KDDT. We also explored individual contributions of the DT model, LM, and KD to the overall performance of KDDT, via a comprehensive empirical study, and observed average F1 score improvements of 12.4%, 3%, and 6.05%, respectively.
EvoCLINICAL: Evolving Cyber-Cyber Digital Twin with Active Transfer Learning for Automated Cancer Registry System
Sep 06, 2023



The Cancer Registry of Norway (CRN) collects information on cancer patients by receiving cancer messages from different medical entities (e.g., medical labs, and hospitals) in Norway. Such messages are validated by an automated cancer registry system: GURI. Its correct operation is crucial since it lays the foundation for cancer research and provides critical cancer-related statistics to its stakeholders. Constructing a cyber-cyber digital twin (CCDT) for GURI can facilitate various experiments and advanced analyses of the operational state of GURI without requiring intensive interactions with the real system. However, GURI constantly evolves due to novel medical diagnostics and treatment, technological advances, etc. Accordingly, CCDT should evolve as well to synchronize with GURI. A key challenge of achieving such synchronization is that evolving CCDT needs abundant data labelled by the new GURI. To tackle this challenge, we propose EvoCLINICAL, which considers the CCDT developed for the previous version of GURI as the pretrained model and fine-tunes it with the dataset labelled by querying a new GURI version. EvoCLINICAL employs a genetic algorithm to select an optimal subset of cancer messages from a candidate dataset and query GURI with it. We evaluate EvoCLINICAL on three evolution processes. The precision, recall, and F1 score are all greater than 91%, demonstrating the effectiveness of EvoCLINICAL. Furthermore, we replace the active learning part of EvoCLINICAL with random selection to study the contribution of transfer learning to the overall performance of EvoCLINICAL. Results show that employing active learning in EvoCLINICAL increases its performances consistently.