 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLTX-2: Efficient Joint Audio-Visual Foundation Model
Jan 06, 2026Recent text-to-video diffusion models can generate compelling video sequences, yet they remain silent -- missing the semantic, emotional, and atmospheric cues that audio provides. We introduce LTX-2, an open-source foundational model capable of generating high-quality, temporally synchronized audiovisual content in a unified manner. LTX-2 consists of an asymmetric dual-stream transformer with a 14B-parameter video stream and a 5B-parameter audio stream, coupled through bidirectional audio-video cross-attention layers with temporal positional embeddings and cross-modality AdaLN for shared timestep conditioning. This architecture enables efficient training and inference of a unified audiovisual model while allocating more capacity for video generation than audio generation. We employ a multilingual text encoder for broader prompt understanding and introduce a modality-aware classifier-free guidance (modality-CFG) mechanism for improved audiovisual alignment and controllability. Beyond generating speech, LTX-2 produces rich, coherent audio tracks that follow the characters, environment, style, and emotion of each scene -- complete with natural background and foley elements. In our evaluations, the model achieves state-of-the-art audiovisual quality and prompt adherence among open-source systems, while delivering results comparable to proprietary models at a fraction of their computational cost and inference time. All model weights and code are publicly released.
Dodging Attack Using Carefully Crafted Natural Makeup
Sep 14, 2021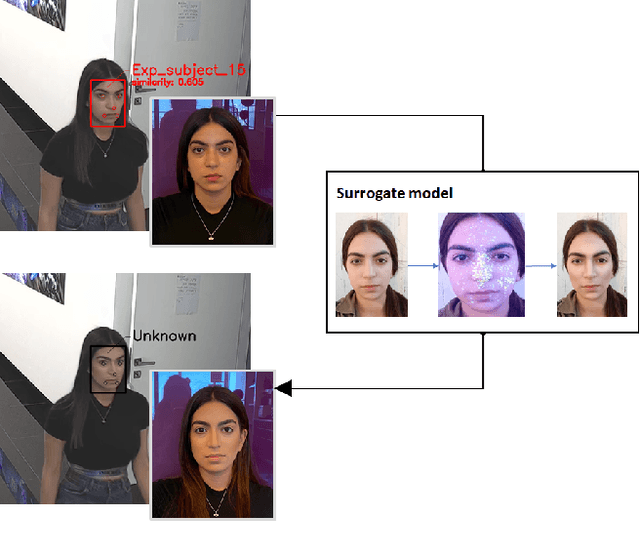

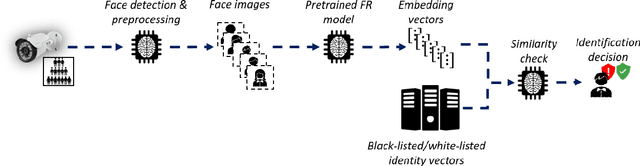
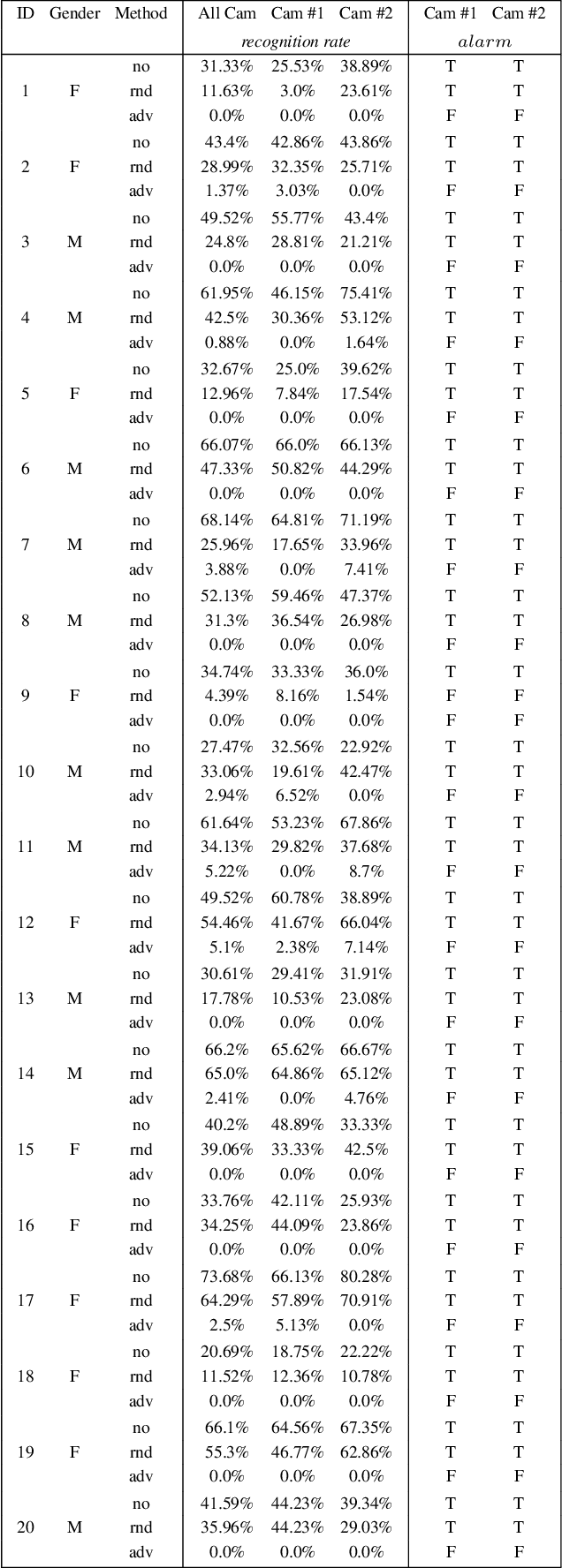
Deep learning face recognition models are used by state-of-the-art surveillance systems to identify individuals passing through public areas (e.g., airports). Previous studies have demonstrated the use of adversarial machine learning (AML) attacks to successfully evade identification by such systems, both in the digital and physical domains. Attacks in the physical domain, however, require significant manipulation to the human participant's face, which can raise suspicion by human observers (e.g. airport security officers). In this study, we present a novel black-box AML attack which carefully crafts natural makeup, which, when applied on a human participant, prevents the participant from being identified by facial recognition models. We evaluated our proposed attack against the ArcFace face recognition model, with 20 participants in a real-world setup that includes two cameras, different shooting angles, and different lighting conditions. The evaluation results show that in the digital domain, the face recognition system was unable to identify all of the participants, while in the physical domain, the face recognition system was able to identify the participants in only 1.22% of the frames (compared to 47.57% without makeup and 33.73% with random natural makeup), which is below a reasonable threshold of a realistic operational environment.