 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generic Hybrid Framework for 2D Visual Reconstruction
Jan 31, 2025



This paper presents a versatile hybrid framework for addressing 2D real-world reconstruction tasks formulated as jigsaw puzzle problems (JPPs) with square, non-overlapping pieces. Our approach integrates a deep learning (DL)-based compatibility measure (CM) model that evaluates pairs of puzzle pieces holistically, rather than focusing solely on their adjacent edges as traditionally done. This DL-based CM is paired with an optimized genetic algorithm (GA)-based solver, which iteratively searches for a global optimal arrangement using the pairwise CM scores of the puzzle pieces. Extensive experimental results highlight the framework's adaptability and robustness across multiple real-world domains. Notably, our unique hybrid methodology achieves state-of-the-art (SOTA) results in reconstructing Portuguese tile panels and large degraded puzzles with eroded boundaries.
PathRTM: Real-time prediction of KI-67 and tumor-infiltrated lymphocytes
Apr 23, 2023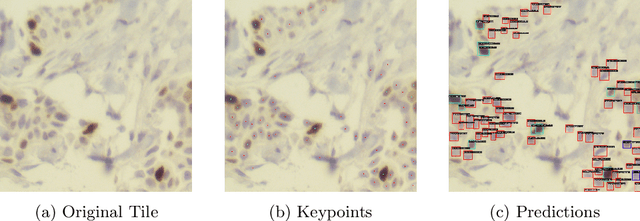
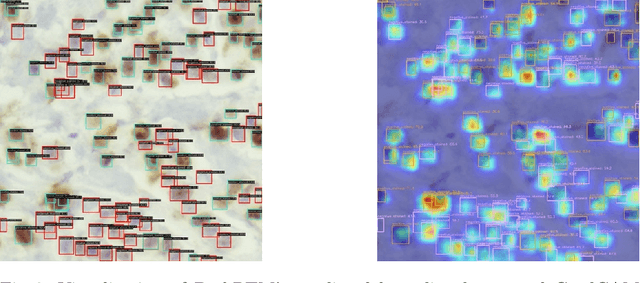

In this paper, we introduce PathRTM, a novel deep neural network detector based on RTMDet, for automated KI-67 proliferation and tumor-infiltrated lymphocyte estimation. KI-67 proliferation and tumor-infiltrated lymphocyte estimation play a crucial role in cancer diagnosis and treatment. PathRTM is an extension of the PathoNet work, which uses single pixel keypoints for within each cell. We demonstrate that PathRTM, with higher-level supervision in the form of bounding box labels generated automatically from the keypoints using NuClick, can significantly improve KI-67 proliferation and tumorinfiltrated lymphocyte estimation. Experiments on our custom dataset show that PathRTM achieves state-of-the-art performance in KI-67 immunopositive, immunonegative, and lymphocyte detection, with an average precision (AP) of 41.3%. Our results suggest that PathRTM is a promising approach for accurate KI-67 proliferation and tumor-infiltrated lymphocyte estimation, offering annotation efficiency, accurate predictive capabilities, and improved runtime. The method also enables estimation of cell sizes of interest, which was previously unavailable, through the bounding box predictions.
Edge2Vec: A High Quality Embedding for the Jigsaw Puzzle Problem
Nov 14, 2022Pairwise compatibility measure (CM) is a key component in solving the jigsaw puzzle problem (JPP) and many of its recently proposed variants. With the rapid rise of deep neural networks (DNNs), a trade-off between performance (i.e., accuracy) and computational efficiency has become a very significant issue. Whereas an end-to-end DNN-based CM model exhibits high performance, it becomes virtually infeasible on very large puzzles, due to its highly intensive computation. On the other hand, exploiting the concept of embeddings to alleviate significantly the computational efficiency, has resulted in degraded performance, according to recent studies. This paper derives an advanced CM model (based on modified embeddings and a new loss function, called hard batch triplet loss) for closing the above gap between speed and accuracy; namely a CM model that achieves SOTA results in terms of performance and efficiency combined. We evaluated our newly derived CM on three commonly used datasets, and obtained a reconstruction improvement of 5.8% and 19.5% for so-called Type-1 and Type-2 problem variants, respectively, compared to best known results due to previous CMs.
Gator: Customizable Channel Pruning of Neural Networks with Gating
Jun 01, 2022The rise of neural network (NN) applications has prompted an increased interest in compression, with a particular focus on channel pruning, which does not require any additional hardware. Most pruning methods employ either single-layer operations or global schemes to determine which channels to remove followed by fine-tuning of the network. In this paper we present Gator, a channel-pruning method which temporarily adds learned gating mechanisms for pruning of individual channels, and which is trained with an additional auxiliary loss, aimed at reducing the computational cost due to memory, (theoretical) speedup (in terms of FLOPs), and practical, hardware-specific speedup. Gator introduces a new formulation of dependencies between NN layers which, in contrast to most previous methods, enables pruning of non-sequential parts, such as layers on ResNet's highway, and even removing entire ResNet blocks. Gator's pruning for ResNet-50 trained on ImageNet produces state-of-the-art (SOTA) results, such as 50% FLOPs reduction with only 0.4%-drop in top-5 accuracy. Also, Gator outperforms previous pruning models, in terms of GPU latency by running 1.4 times faster. Furthermore, Gator achieves improved top-5 accuracy results, compared to MobileNetV2 and SqueezeNet, for similar runtimes. The source code of this work is available at: https://github.com/EliPassov/gator.
* 14 pages, 3 figures. The version that appeared in ICANN is an earlier version
TEN: Twin Embedding Networks for the Jigsaw Puzzle Problem with Eroded Boundaries
Mar 12, 2022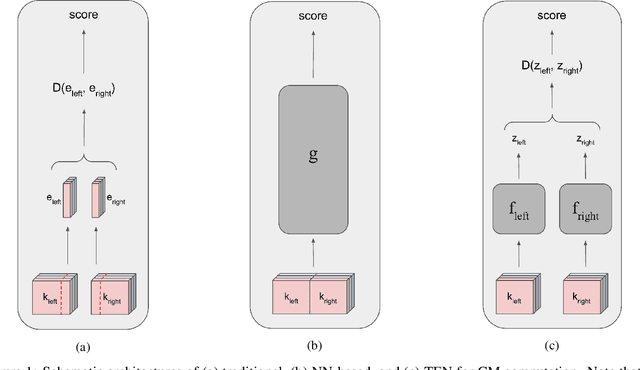
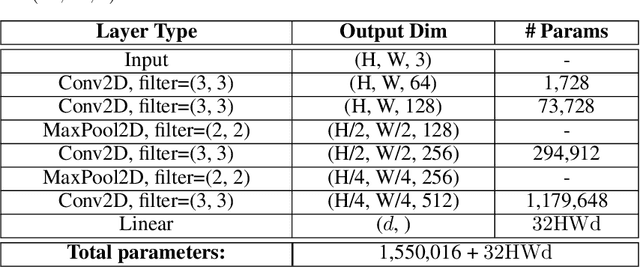


The jigsaw puzzle problem (JPP) is a well-known research problem, which has been studied for many years. Solving this problem typically involves a two-stage scheme, consisting of the computation of a pairwise piece compatibility measure (CM), coupled with a subsequent puzzle reconstruction algorithm. Many effective CMs, which apply a simple distance measure, based merely on the information along the piece edges, have been proposed. However, the practicality of these classical methods is rather doubtful for problem instances harder than pure synthetic images. Specifically, these methods tend to break down in more realistic scenarios involving, e.g., monochromatic puzzles, eroded boundaries due to piece degradation over long time periods, missing pieces, etc. To overcome this significant deficiency, a few deep convolutional neural network (CNN)-based CMs have been recently introduced. Despite their promising accuracy, these models are very computationally intensive. Twin Embedding Networks (TEN), to represent a piece with respect to its boundary in a latent embedding space. Combining this latent representation with a simple distance measure, we then demonstrate a superior performance, in terms of accuracy, of our newly proposed pairwise CM, compared to that of various classical methods, for the problem domain of eroded tile boundaries, a testbed for a number of real-world JPP variants. Furthermore, we also demonstrate that TEN is faster by a few orders of magnitude, on average, than the recent NN models, i.e., it is as fast as the classical methods. In this regard, the paper makes a significant first attempt at bridging the gap between the relatively low accuracy (of classical methods) and the intensive computational complexity (of NN models), for practical, real-world puzzle-like problems.
Stealing Knowledge from Protected Deep Neural Networks Using Composite Unlabeled Data
Dec 09, 2019
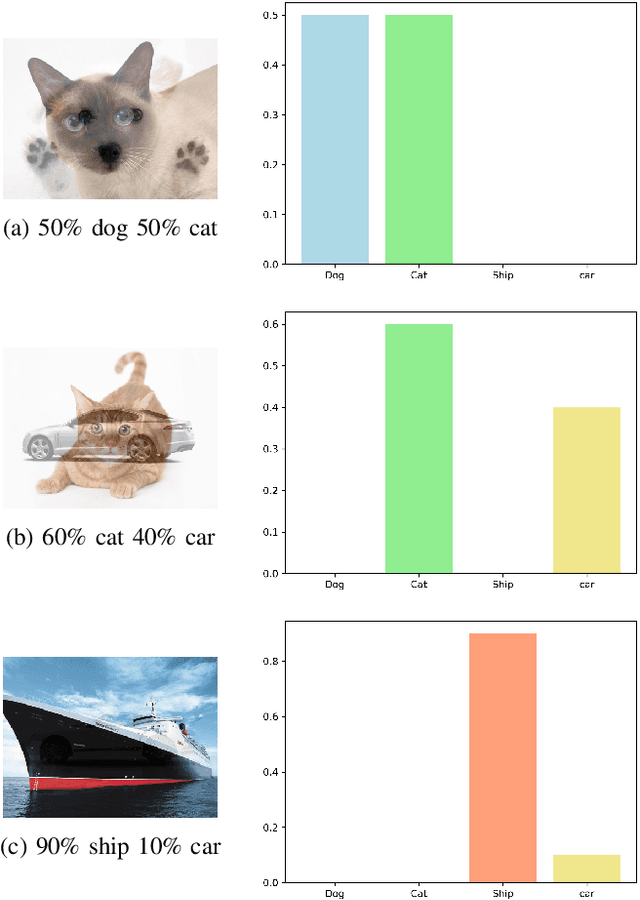
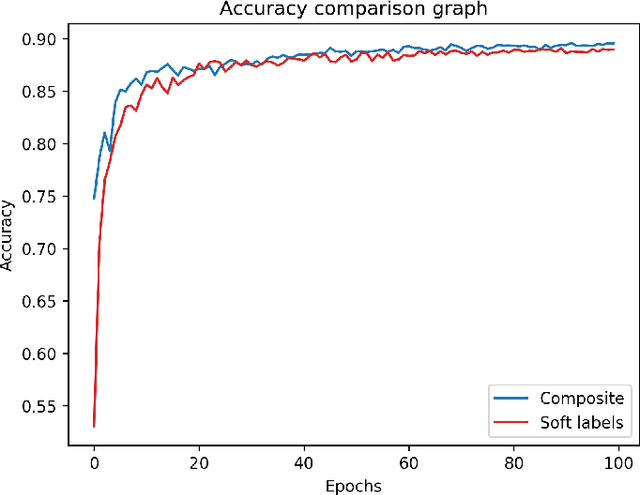

As state-of-the-art deep neural networks are deployed at the core of more advanced Al-based products and services, the incentive for copying them (i.e., their intellectual properties) by rival adversaries is expected to increase considerably over time. The best way to extract or steal knowledge from such networks is by querying them using a large dataset of random samples and recording their output, followed by training a student network to mimic these outputs, without making any assumption about the original networks. The most effective way to protect against such a mimicking attack is to provide only the classification result, without confidence values associated with the softmax layer.In this paper, we present a novel method for generating composite images for attacking a mentor neural network using a student model. Our method assumes no information regarding the mentor's training dataset, architecture, or weights. Further assuming no information regarding the mentor's softmax output values, our method successfully mimics the given neural network and steals all of its knowledge. We also demonstrate that our student network (which copies the mentor) is impervious to watermarking protection methods, and thus would not be detected as a stolen model.Our results imply, essentially, that all current neural networks are vulnerable to mimicking attacks, even if they do not divulge anything but the most basic required output, and that the student model which mimics them cannot be easily detected and singled out as a stolen copy using currently available techniques.
DeepEthnic: Multi-Label Ethnic Classification from Face Images
Dec 06, 2019

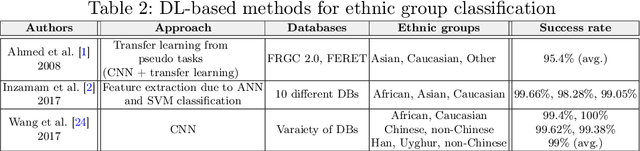
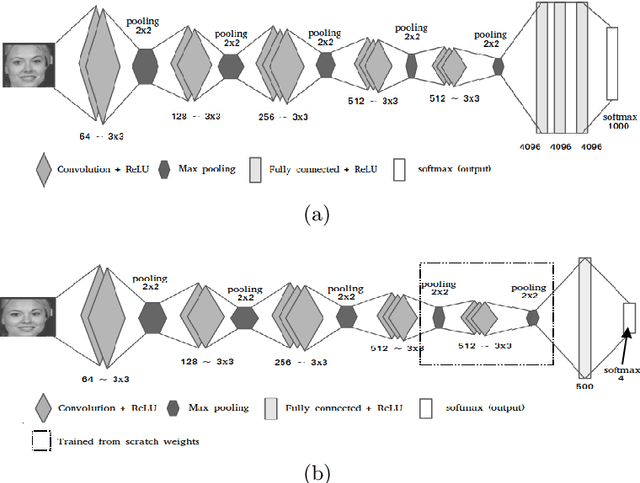
Ethnic group classification is a well-researched problem, which has been pursued mainly during the past two decades via traditional approaches of image processing and machine learning. In this paper, we propose a method of classifying an image face into an ethnic group by applying transfer learning from a previously trained classification network for large-scale data recognition. Our proposed method yields state-of-the-art success rates of 99.02%, 99.76%, 99.2%, and 96.7%, respectively, for the four ethnic groups: African, Asian, Caucasian, and Indian.
Handwriting-Based Gender Classification Using End-to-End Deep Neural Networks
Dec 04, 2019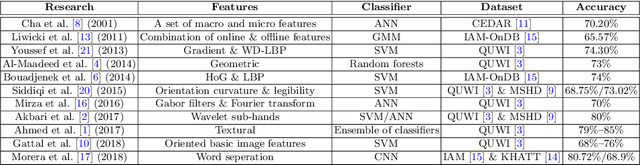
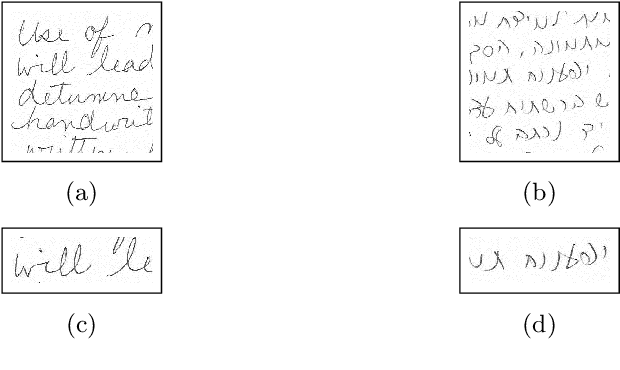
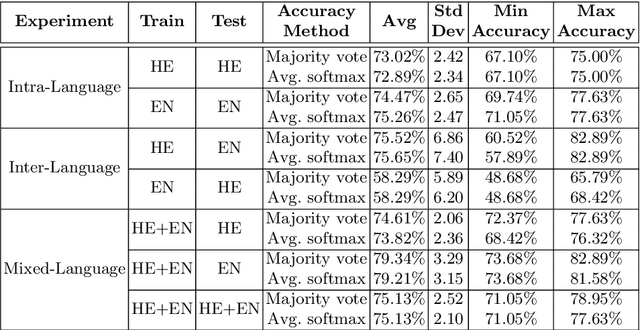
Handwriting-based gender classification is a well-researched problem that has been approached mainly by traditional machine learning techniques. In this paper, we propose a novel deep learning-based approach for this task. Specifically, we present a convolutional neural network (CNN), which performs automatic feature extraction from a given handwritten image, followed by classification of the writer's gender. Also, we introduce a new dataset of labeled handwritten samples, in Hebrew and English, of 405 participants. Comparing the gender classification accuracy on this dataset against human examiners, our results show that the proposed deep learning-based approach is substantially more accurate than that of humans.
A Novel Hybrid Scheme Using Genetic Algorithms and Deep Learning for the Reconstruction of Portuguese Tile Panels
Dec 04, 2019

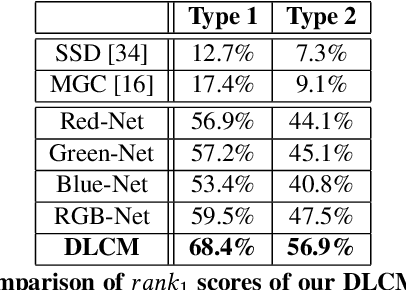
This paper presents a novel scheme, based on a unique combination of genetic algorithms (GAs) and deep learning (DL), for the automatic reconstruction of Portuguese tile panels, a challenging real-world variant of the jigsaw puzzle problem (JPP) with important national heritage implications. Specifically, we introduce an enhanced GA-based puzzle solver, whose integration with a novel DL-based compatibility measure (DLCM) yields state-of-the-art performance, regarding the above application. Current compatibility measures consider typically (the chromatic information of) edge pixels (between adjacent tiles), and help achieve high accuracy for the synthetic JPP variant. However, such measures exhibit rather poor performance when applied to the Portuguese tile panels, which are susceptible to various real-world effects, e.g., monochromatic panels, non-squared tiles, edge degradation, etc. To overcome such difficulties, we have developed a novel DLCM to extract high-level texture/color statistics from the entire tile information. Integrating this measure with our enhanced GA-based puzzle solver, we have demonstrated, for the first time, how to deal most effectively with large-scale real-world problems, such as the Portuguese tile problem. Specifically, we have achieved 82% accuracy for the reconstruction of Portuguese tile panels with unknown piece rotation and puzzle dimension (compared to merely 3.5% average accuracy achieved by the best method known for solving this problem variant). The proposed method outperforms even human experts in several cases, correcting their mistakes in the manual tile assembly.
End-to-End Deep Neural Networks and Transfer Learning for Automatic Analysis of Nation-State Malware
Nov 30, 2019

Malware allegedly developed by nation-states, also known as advanced persistent threats (APT), are becoming more common. The task of attributing an APT to a specific nation-state or classifying it to the correct APT family is challenging for several reasons. First, each nation-state has more than a single cyber unit that develops such malware, rendering traditional authorship attribution algorithms useless. Furthermore, the dataset of such available APTs is still extremely small. Finally, those APTs use state-of-the-art evasion techniques, making feature extraction challenging. In this paper, we use a deep neural network (DNN) as a classifier for nation-state APT attribution. We record the dynamic behavior of the APT when run in a sandbox and use it as raw input for the neural network, allowing the DNN to learn high level feature abstractions of the APTs itself. We also use the same raw features for APT family classification. Finally, we use the feature abstractions learned by the APT family classifier to solve the attribution problem. Using a test set of 1000 Chinese and Russian developed APTs, we achieved an accuracy rate of 98.6%.
* arXiv admin note: substantial text overlap with arXiv:1711.09666