 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeing Single Has Benefits. Instance Poisoning to Deceive Malware Classifiers
Oct 30, 2020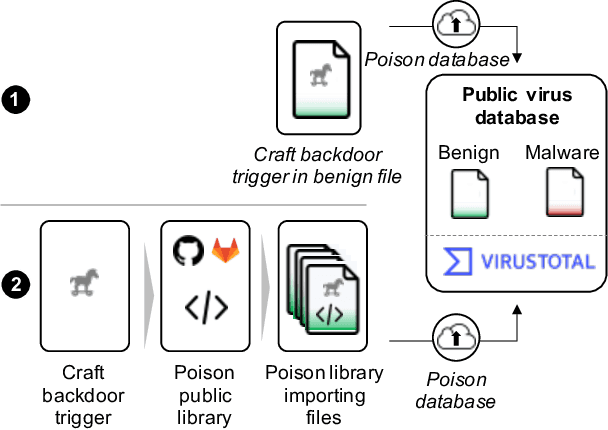
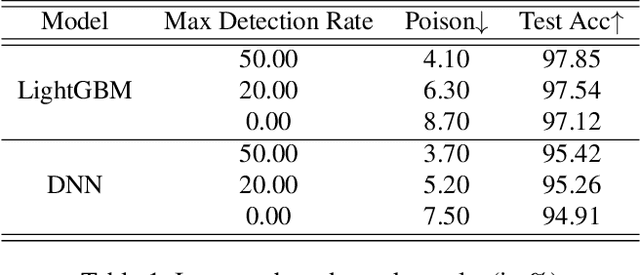
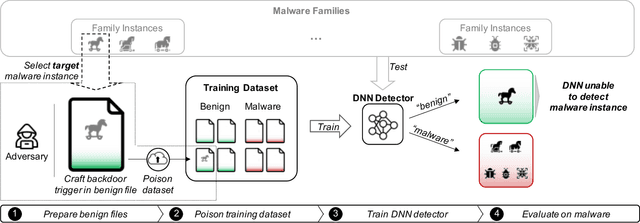
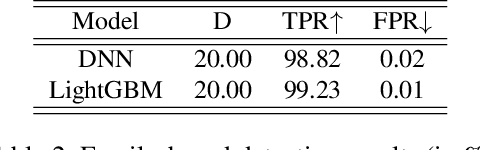
The performance of a machine learning-based malware classifier depends on the large and updated training set used to induce its model. In order to maintain an up-to-date training set, there is a need to continuously collect benign and malicious files from a wide range of sources, providing an exploitable target to attackers. In this study, we show how an attacker can launch a sophisticated and efficient poisoning attack targeting the dataset used to train a malware classifier. The attacker's ultimate goal is to ensure that the model induced by the poisoned dataset will be unable to detect the attacker's malware yet capable of detecting other malware. As opposed to other poisoning attacks in the malware detection domain, our attack does not focus on malware families but rather on specific malware instances that contain an implanted trigger, reducing the detection rate from 99.23% to 0% depending on the amount of poisoning. We evaluate our attack on the EMBER dataset with a state-of-the-art classifier and malware samples from VirusTotal for end-to-end validation of our work. We propose a comprehensive detection approach that could serve as a future sophisticated defense against this newly discovered severe threat.
GLOD: Gaussian Likelihood Out of Distribution Detector
Aug 21, 2020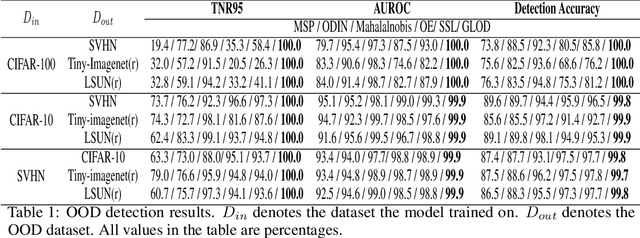
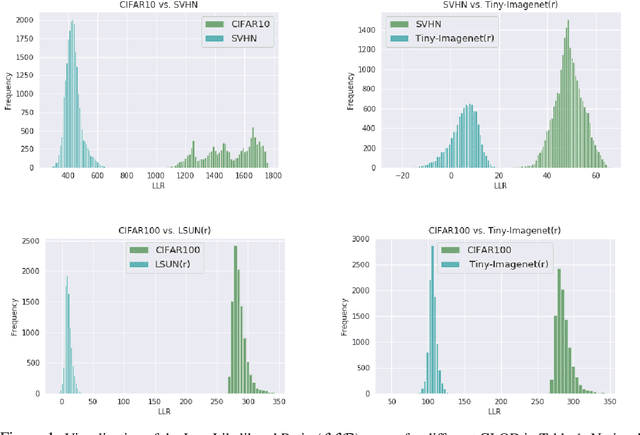
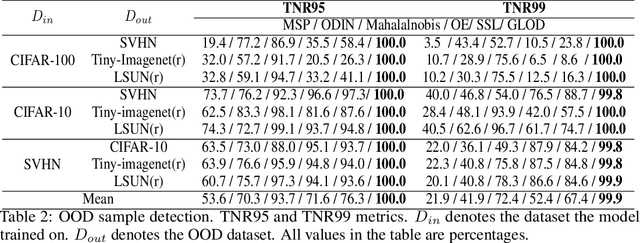
Discriminative deep neural networks (DNNs) do well at classifying input associated with the classes they have been trained on. However, out-of-distribution (OOD) input poses a great challenge to such models and consequently represents a major risk when these models are used in safety-critical systems. In the last two years, extensive research has been performed in the domain of OOD detection. This research has relied mainly on training the model with OOD data or using an auxiliary (external) model for OOD detection. Such methods have limited capability in detecting OOD samples and may not be applicable in many real world use cases. In this paper, we propose GLOD - Gaussian likelihood out of distribution detector - an extended DNN classifier capable of efficiently detecting OOD samples without relying on OOD training data or an external detection model. GLOD uses a layer that models the Gaussian density function of the trained classes. The layer outputs are used to estimate a Log-Likelihood Ratio which is employed to detect OOD samples. We evaluate GLOD's detection performance on three datasets: SVHN, CIFAR-10, and CIFAR-100. Our results show that GLOD surpasses state-of-the-art OOD detection techniques in detection performance by a large margin.
Neural Network Representation Control: Gaussian Isolation Machines and CVC Regularization
Feb 06, 2020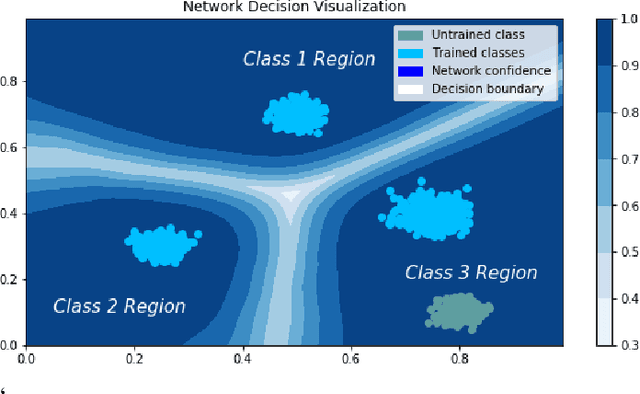

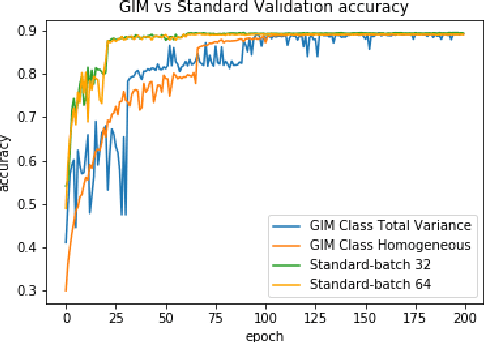
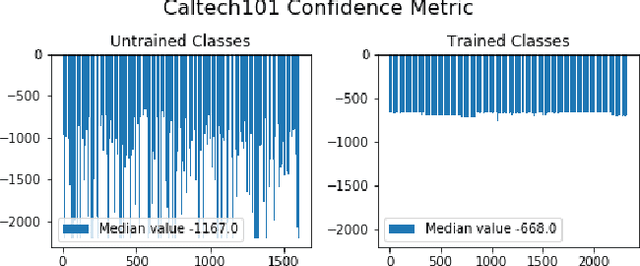
In many cases, neural network classifiers are likely to be exposed to input data that is outside of their training distribution data. Samples from outside the distribution may be classified as an existing class with high probability by softmax-based classifiers; such incorrect classifications affect the performance of the classifiers and the applications/systems that depend on them. Previous research aimed at distinguishing training distribution data from out-of-distribution data (OOD) has proposed detectors that are external to the classification method. We present Gaussian isolation machine (GIM), a novel hybrid (generative-discriminative) classifier aimed at solving the problem arising when OOD data is encountered. The GIM is based on a neural network and utilizes a new loss function that imposes a distribution on each of the trained classes in the neural network's output space, which can be approximated by a Gaussian. The proposed GIM's novelty lies in its discriminative performance and generative capabilities, a combination of characteristics not usually seen in a single classifier. The GIM achieves state-of-the-art classification results on image recognition and sentiment analysis benchmarking datasets and can also deal with OOD inputs. We also demonstrate the benefits of incorporating part of the GIM's loss function into standard neural networks as a regularization method.
End-to-End Deep Neural Networks and Transfer Learning for Automatic Analysis of Nation-State Malware
Nov 30, 2019

Malware allegedly developed by nation-states, also known as advanced persistent threats (APT), are becoming more common. The task of attributing an APT to a specific nation-state or classifying it to the correct APT family is challenging for several reasons. First, each nation-state has more than a single cyber unit that develops such malware, rendering traditional authorship attribution algorithms useless. Furthermore, the dataset of such available APTs is still extremely small. Finally, those APTs use state-of-the-art evasion techniques, making feature extraction challenging. In this paper, we use a deep neural network (DNN) as a classifier for nation-state APT attribution. We record the dynamic behavior of the APT when run in a sandbox and use it as raw input for the neural network, allowing the DNN to learn high level feature abstractions of the APTs itself. We also use the same raw features for APT family classification. Finally, we use the feature abstractions learned by the APT family classifier to solve the attribution problem. Using a test set of 1000 Chinese and Russian developed APTs, we achieved an accuracy rate of 98.6%.
* arXiv admin note: substantial text overlap with arXiv:1711.09666
Query-Efficient GAN Based Black-Box Attack Against Sequence Based Machine and Deep Learning Classifiers
Sep 22, 2018
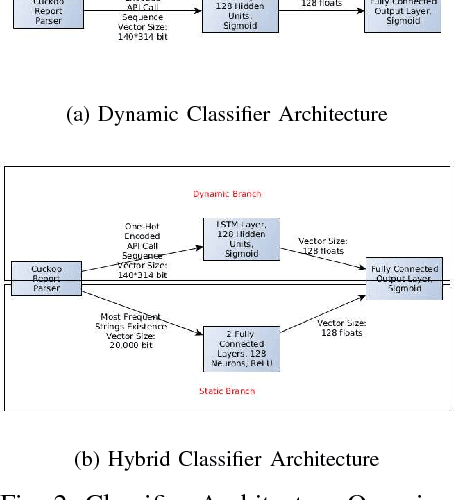

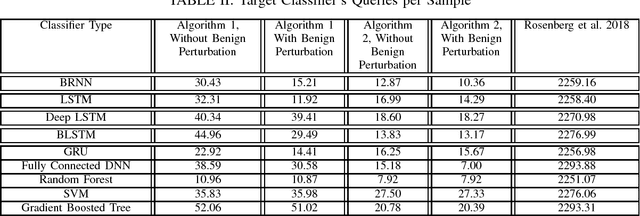
In this paper, we present a generic black-box attack, demonstrated against API call based machine learning malware classifiers. We generate adversarial examples combining sequences (API call sequences) and other features (e.g., printable strings) that will be misclassified by the classifier without affecting the malware functionality. Our attack minimizes the number of target classifier queries and only requires access to the predicted label of the attacked model (without the confidence level). We evaluate the attack's effectiveness against many classifiers such as RNN variants, DNN, SVM, GBDT, etc. We show that the attack requires fewer queries and less knowledge about the attacked model's architecture than other existing black-box attacks, making it optimal to attack cloud based models at a minimal cost. Finally, we discuss the robustness of this attack to existing defense mechanisms.
Generic Black-Box End-to-End Attack Against State of the Art API Call Based Malware Classifiers
Jun 24, 2018

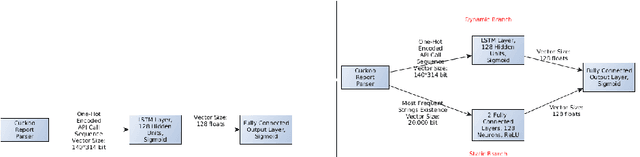
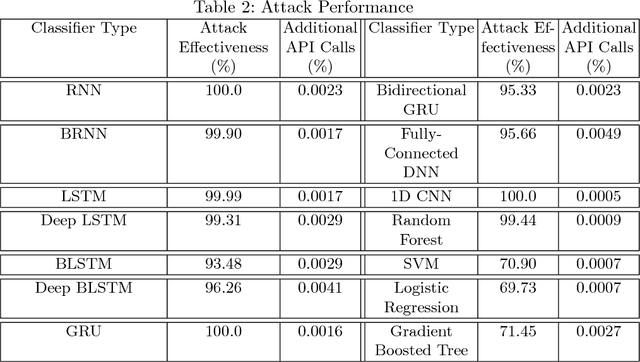
In this paper, we present a black-box attack against API call based machine learning malware classifiers, focusing on generating adversarial sequences combining API calls and static features (e.g., printable strings) that will be misclassified by the classifier without affecting the malware functionality. We show that this attack is effective against many classifiers due to the transferability principle between RNN variants, feed forward DNNs, and traditional machine learning classifiers such as SVM. We also implement GADGET, a software framework to convert any malware binary to a binary undetected by malware classifiers, using the proposed attack, without access to the malware source code.
DeepAPT: Nation-State APT Attribution Using End-to-End Deep Neural Networks
Nov 27, 2017In recent years numerous advanced malware, aka advanced persistent threats (APT) are allegedly developed by nation-states. The task of attributing an APT to a specific nation-state is extremely challenging for several reasons. Each nation-state has usually more than a single cyber unit that develops such advanced malware, rendering traditional authorship attribution algorithms useless. Furthermore, those APTs use state-of-the-art evasion techniques, making feature extraction challenging. Finally, the dataset of such available APTs is extremely small. In this paper we describe how deep neural networks (DNN) could be successfully employed for nation-state APT attribution. We use sandbox reports (recording the behavior of the APT when run dynamically) as raw input for the neural network, allowing the DNN to learn high level feature abstractions of the APTs itself. Using a test set of 1,000 Chinese and Russian developed APTs, we achieved an accuracy rate of 94.6%.