 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeakBoost: Perceptual-Loss-Based Membership Inference Attack
Feb 05, 2026Membership inference attacks (MIAs) aim to determine whether a sample was part of a model's training set, posing serious privacy risks for modern machine-learning systems. Existing MIAs primarily rely on static indicators, such as loss or confidence, and do not fully leverage the dynamic behavior of models when actively probed. We propose LeakBoost, a perceptual-loss-based interrogation framework that actively probes a model's internal representations to expose hidden membership signals. Given a candidate input, LeakBoost synthesizes an interrogation image by optimizing a perceptual (activation-space) objective, amplifying representational differences between members and non-members. This image is then analyzed by an off-the-shelf membership detector, without modifying the detector itself. When combined with existing membership inference methods, LeakBoost achieves substantial improvements at low false-positive rates across multiple image classification datasets and diverse neural network architectures. In particular, it raises AUC from near-chance levels (0.53-0.62) to 0.81-0.88, and increases TPR at 1 percent FPR by over an order of magnitude compared to strong baseline attacks. A detailed sensitivity analysis reveals that deeper layers and short, low-learning-rate optimization produce the strongest leakage, and that improvements concentrate in gradient-based detectors. LeakBoost thus offers a modular and computationally efficient way to assess privacy risks in white-box settings, advancing the study of dynamic membership inference.
Memory Backdoor Attacks on Neural Networks
Nov 21, 2024



Neural networks, such as image classifiers, are frequently trained on proprietary and confidential datasets. It is generally assumed that once deployed, the training data remains secure, as adversaries are limited to query response interactions with the model, where at best, fragments of arbitrary data can be inferred without any guarantees on their authenticity. In this paper, we propose the memory backdoor attack, where a model is covertly trained to memorize specific training samples and later selectively output them when triggered with an index pattern. What makes this attack unique is that it (1) works even when the tasks conflict (making a classifier output images), (2) enables the systematic extraction of training samples from deployed models and (3) offers guarantees on the extracted authenticity of the data. We demonstrate the attack on image classifiers, segmentation models, and a large language model (LLM). We demonstrate the attack on image classifiers, segmentation models, and a large language model (LLM). With this attack, it is possible to hide thousands of images and texts in modern vision architectures and LLMs respectively, all while maintaining model performance. The memory back door attack poses a significant threat not only to conventional model deployments but also to federated learning paradigms and other modern frameworks. Therefore, we suggest an efficient and effective countermeasure that can be immediately applied and advocate for further work on the topic.
Back-in-Time Diffusion: Unsupervised Detection of Medical Deepfakes
Jul 21, 2024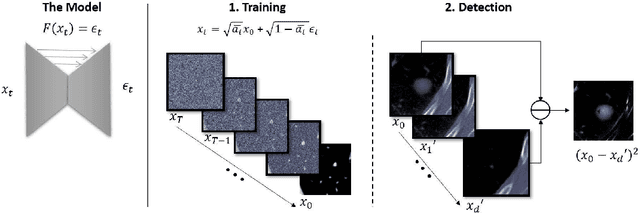



Recent progress in generative models has made it easier for a wide audience to edit and create image content, raising concerns about the proliferation of deepfakes, especially in healthcare. Despite the availability of numerous techniques for detecting manipulated images captured by conventional cameras, their applicability to medical images is limited. This limitation stems from the distinctive forensic characteristics of medical images, a result of their imaging process. In this work we propose a novel anomaly detector for medical imagery based on diffusion models. Normally, diffusion models are used to generate images. However, we show how a similar process can be used to detect synthetic content by making a model reverse the diffusion on a suspected image. We evaluate our method on the task of detecting fake tumors injected and removed from CT and MRI scans. Our method significantly outperforms other state of the art unsupervised detectors with an increased AUC of 0.9 from 0.79 for injection and of 0.96 from 0.91 for removal on average.
Membership Inference Attacks Against Time-Series Models
Jul 03, 2024



Analyzing time-series data that may contain personal information, particularly in the medical field, presents serious privacy concerns. Sensitive health data from patients is often used to train machine-learning models for diagnostics and ongoing care. Assessing the privacy risk of such models is crucial to making knowledgeable decisions on whether to use a model in production, share it with third parties, or deploy it in patients homes. Membership Inference Attacks (MIA) are a key method for this kind of evaluation, however time-series prediction models have not been thoroughly studied in this context. We explore existing MIA techniques on time-series models, and introduce new features, focusing on the seasonality and trend components of the data. Seasonality is estimated using a multivariate Fourier transform, and a low-degree polynomial is used to approximate trends. We applied these techniques to various types of time-series models, using datasets from the health domain. Our results demonstrate that these new features enhance the effectiveness of MIAs in identifying membership, improving the understanding of privacy risks in medical data applications.
Is My Data in Your Retrieval Database? Membership Inference Attacks Against Retrieval Augmented Generation
May 30, 2024


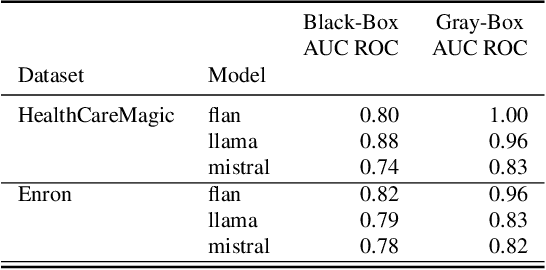
Retrieval Augmented Generation (RAG) systems have shown great promise in natural language processing. However, their reliance on data stored in a retrieval database, which may contain proprietary or sensitive information, introduces new privacy concerns. Specifically, an attacker may be able to infer whether a certain text passage appears in the retrieval database by observing the outputs of the RAG system, an attack known as a Membership Inference Attack (MIA). Despite the significance of this threat, MIAs against RAG systems have yet remained under-explored. This study addresses this gap by introducing an efficient and easy-to-use method for conducting MIA against RAG systems. We demonstrate the effectiveness of our attack using two benchmark datasets and multiple generative models, showing that the membership of a document in the retrieval database can be efficiently determined through the creation of an appropriate prompt in both black-box and gray-box settings. Our findings highlight the importance of implementing security countermeasures in deployed RAG systems to protect the privacy and security of retrieval databases.
What Was Your Prompt? A Remote Keylogging Attack on AI Assistants
Mar 14, 2024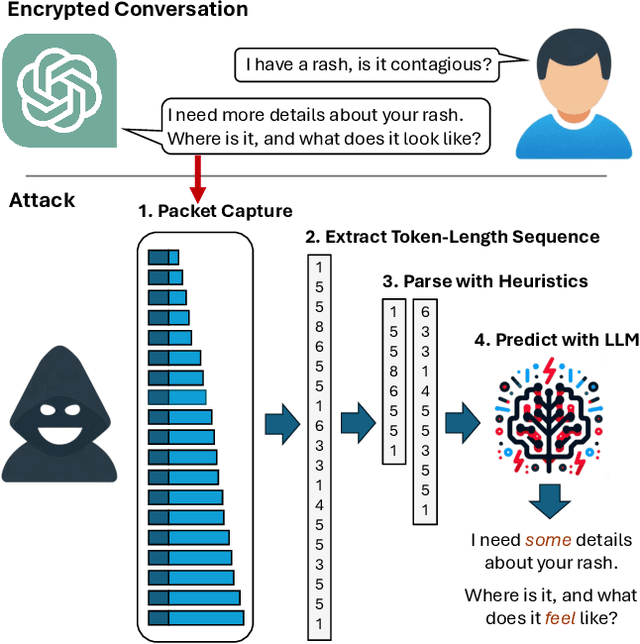
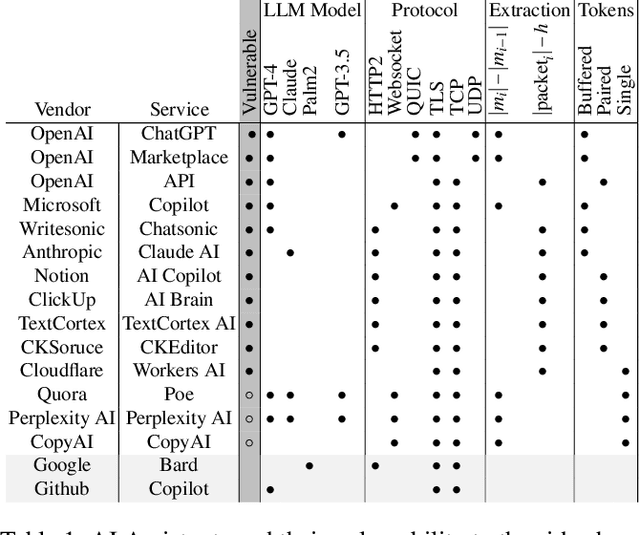


AI assistants are becoming an integral part of society, used for asking advice or help in personal and confidential issues. In this paper, we unveil a novel side-channel that can be used to read encrypted responses from AI Assistants over the web: the token-length side-channel. We found that many vendors, including OpenAI and Microsoft, have this side-channel. However, inferring the content of a response from a token-length sequence alone proves challenging. This is because tokens are akin to words, and responses can be several sentences long leading to millions of grammatically correct sentences. In this paper, we show how this can be overcome by (1) utilizing the power of a large language model (LLM) to translate these sequences, (2) providing the LLM with inter-sentence context to narrow the search space and (3) performing a known-plaintext attack by fine-tuning the model on the target model's writing style. Using these methods, we were able to accurately reconstruct 29\% of an AI assistant's responses and successfully infer the topic from 55\% of them. To demonstrate the threat, we performed the attack on OpenAI's ChatGPT-4 and Microsoft's Copilot on both browser and API traffic.
SoK: Reducing the Vulnerability of Fine-tuned Language Models to Membership Inference Attacks
Mar 13, 2024


Natural language processing models have experienced a significant upsurge in recent years, with numerous applications being built upon them. Many of these applications require fine-tuning generic base models on customized, proprietary datasets. This fine-tuning data is especially likely to contain personal or sensitive information about individuals, resulting in increased privacy risk. Membership inference attacks are the most commonly employed attack to assess the privacy leakage of a machine learning model. However, limited research is available on the factors that affect the vulnerability of language models to this kind of attack, or on the applicability of different defense strategies in the language domain. We provide the first systematic review of the vulnerability of fine-tuned large language models to membership inference attacks, the various factors that come into play, and the effectiveness of different defense strategies. We find that some training methods provide significantly reduced privacy risk, with the combination of differential privacy and low-rank adaptors achieving the best privacy protection against these attacks.
Transpose Attack: Stealing Datasets with Bidirectional Training
Nov 13, 2023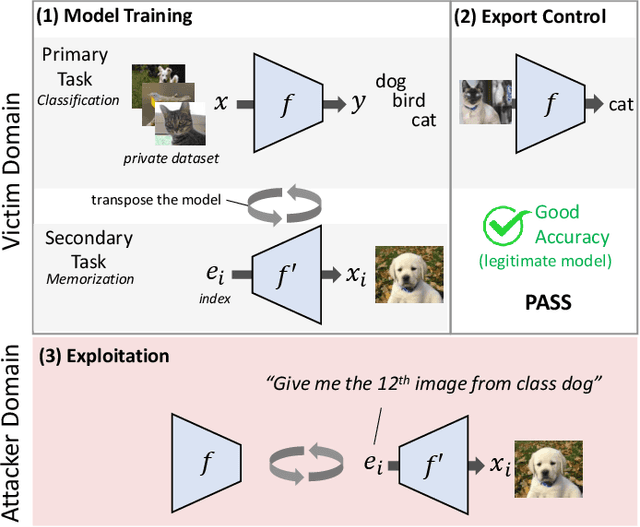



Deep neural networks are normally executed in the forward direction. However, in this work, we identify a vulnerability that enables models to be trained in both directions and on different tasks. Adversaries can exploit this capability to hide rogue models within seemingly legitimate models. In addition, in this work we show that neural networks can be taught to systematically memorize and retrieve specific samples from datasets. Together, these findings expose a novel method in which adversaries can exfiltrate datasets from protected learning environments under the guise of legitimate models. We focus on the data exfiltration attack and show that modern architectures can be used to secretly exfiltrate tens of thousands of samples with high fidelity, high enough to compromise data privacy and even train new models. Moreover, to mitigate this threat we propose a novel approach for detecting infected models.
YolOOD: Utilizing Object Detection Concepts for Out-of-Distribution Detection
Dec 05, 2022



Out-of-distribution (OOD) detection has attracted a large amount of attention from the machine learning research community in recent years due to its importance in deployed systems. Most of the previous studies focused on the detection of OOD samples in the multi-class classification task. However, OOD detection in the multi-label classification task remains an underexplored domain. In this research, we propose YolOOD - a method that utilizes concepts from the object detection domain to perform OOD detection in the multi-label classification task. Object detection models have an inherent ability to distinguish between objects of interest (in-distribution) and irrelevant objects (e.g., OOD objects) on images that contain multiple objects from different categories. These abilities allow us to convert a regular object detection model into an image classifier with inherent OOD detection capabilities with just minor changes. We compare our approach to state-of-the-art OOD detection methods and demonstrate YolOOD's ability to outperform these methods on a comprehensive suite of in-distribution and OOD benchmark datasets.
The Security of Deep Learning Defences for Medical Imaging
Jan 21, 2022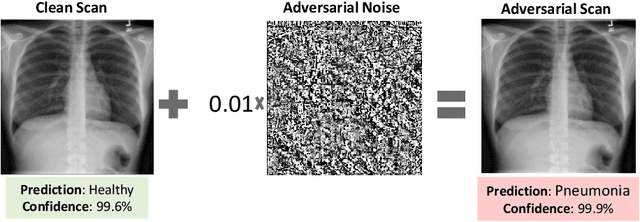
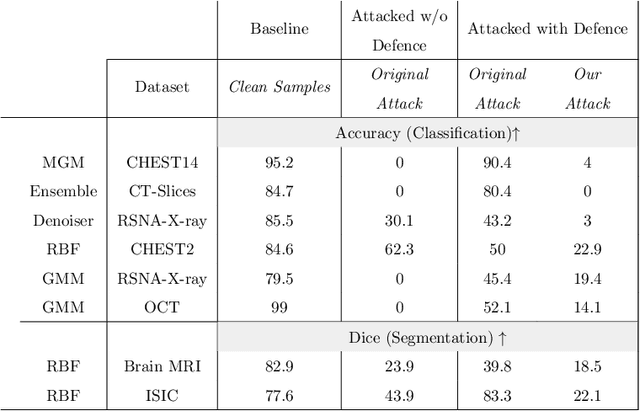
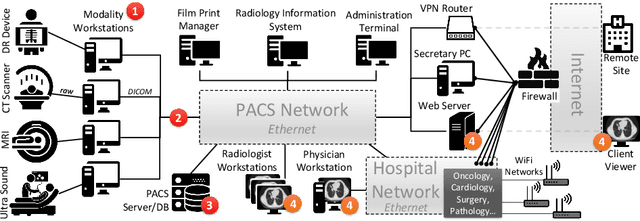
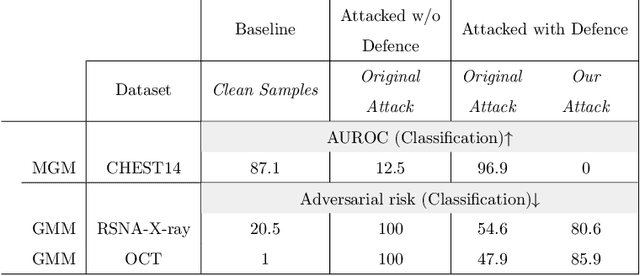
Deep learning has shown great promise in the domain of medical image analysis. Medical professionals and healthcare providers have been adopting the technology to speed up and enhance their work. These systems use deep neural networks (DNN) which are vulnerable to adversarial samples; images with imperceivable changes that can alter the model's prediction. Researchers have proposed defences which either make a DNN more robust or detect the adversarial samples before they do harm. However, none of these works consider an informed attacker which can adapt to the defence mechanism. We show that an informed attacker can evade five of the current state of the art defences while successfully fooling the victim's deep learning model, rendering these defences useless. We then suggest better alternatives for securing healthcare DNNs from such attacks: (1) harden the system's security and (2) use digital signatures.