 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Calibration Enhanced Network by Inverse Adversarial Attack
Apr 08, 2025Test automation has become increasingly important as the complexity of both design and content in Human Machine Interface (HMI) software continues to grow. Current standard practice uses Optical Character Recognition (OCR) techniques to automatically extract textual information from HMI screens for validation. At present, one of the key challenges faced during the automation of HMI screen validation is the noise handling for the OCR models. In this paper, we propose to utilize adversarial training techniques to enhance OCR models in HMI testing scenarios. More specifically, we design a new adversarial attack objective for OCR models to discover the decision boundaries in the context of HMI testing. We then adopt adversarial training to optimize the decision boundaries towards a more robust and accurate OCR model. In addition, we also built an HMI screen dataset based on real-world requirements and applied multiple types of perturbation onto the clean HMI dataset to provide a more complete coverage for the potential scenarios. We conduct experiments to demonstrate how using adversarial training techniques yields more robust OCR models against various kinds of noises, while still maintaining high OCR model accuracy. Further experiments even demonstrate that the adversarial training models exhibit a certain degree of robustness against perturbations from other patterns.
LLMs for Relational Reasoning: How Far are We?
Jan 17, 2024Large language models (LLMs) have revolutionized many areas (e.g. natural language processing, software engineering, etc.) by achieving state-of-the-art performance on extensive downstream tasks. Aiming to achieve robust and general artificial intelligence, there has been a surge of interest in investigating the reasoning ability of the LLMs. Whereas the textual and numerical reasoning benchmarks adopted by previous works are rather shallow and simple, it is hard to conclude that the LLMs possess strong reasoning ability by merely achieving positive results on these benchmarks. Recent efforts have demonstrated that the LLMs are poor at solving sequential decision-making problems that require common-sense planning by evaluating their performance on the reinforcement learning benchmarks. In this work, we conduct an in-depth assessment of several state-of-the-art LLMs' reasoning ability based on the inductive logic programming (ILP) benchmark, which is broadly recognized as a representative and challenging measurement for evaluating logic program induction/synthesis systems as it requires inducing strict cause-effect logic to achieve robust deduction on independent and identically distributed (IID) and out-of-distribution (OOD) test samples. Our evaluations illustrate that compared with the neural program induction systems which are much smaller in model size, the state-of-the-art LLMs are much poorer in terms of reasoning ability by achieving much lower performance and generalization using either natural language prompting or truth-value matrix prompting.
Logic-guided Deep Reinforcement Learning for Stock Trading
Oct 09, 2023



Deep reinforcement learning (DRL) has revolutionized quantitative finance by achieving excellent performance without significant manual effort. Whereas we observe that the DRL models behave unstably in a dynamic stock market due to the low signal-to-noise ratio nature of the financial data. In this paper, we propose a novel logic-guided trading framework, termed as SYENS (Program Synthesis-based Ensemble Strategy). Different from the previous state-of-the-art ensemble reinforcement learning strategy which arbitrarily selects the best-performing agent for testing based on a single measurement, our framework proposes regularizing the model's behavior in a hierarchical manner using the program synthesis by sketching paradigm. First, we propose a high-level, domain-specific language (DSL) that is used for the depiction of the market environment and action. Then based on the DSL, a novel program sketch is introduced, which embeds human expert knowledge in a logical manner. Finally, based on the program sketch, we adopt the program synthesis by sketching a paradigm and synthesizing a logical, hierarchical trading strategy. We evaluate SYENS on the 30 Dow Jones stocks under the cash trading and the margin trading settings. Experimental results demonstrate that our proposed framework can significantly outperform the baselines with much higher cumulative return and lower maximum drawdown under both settings.
Do We Really Need Graph Neural Networks for Traffic Forecasting?
Jan 30, 2023Spatio-temporal graph neural networks (STGNN) have become the most popular solution to traffic forecasting. While successful, they rely on the message passing scheme of GNNs to establish spatial dependencies between nodes, and thus inevitably inherit GNNs' notorious inefficiency. Given these facts, in this paper, we propose an embarrassingly simple yet remarkably effective spatio-temporal learning approach, entitled SimST. Specifically, SimST approximates the efficacies of GNNs by two spatial learning techniques, which respectively model local and global spatial correlations. Moreover, SimST can be used alongside various temporal models and involves a tailored training strategy. We conduct experiments on five traffic benchmarks to assess the capability of SimST in terms of efficiency and effectiveness. Empirical results show that SimST improves the prediction throughput by up to 39 times compared to more sophisticated STGNNs while attaining comparable performance, which indicates that GNNs are not the only option for spatial modeling in traffic forecasting.
GALOIS: Boosting Deep Reinforcement Learning via Generalizable Logic Synthesis
May 27, 2022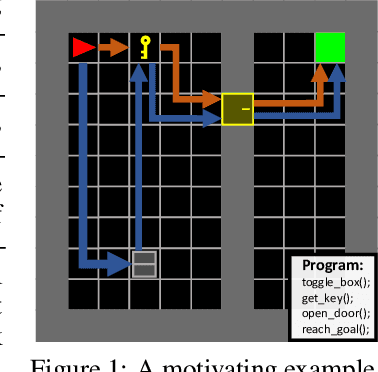
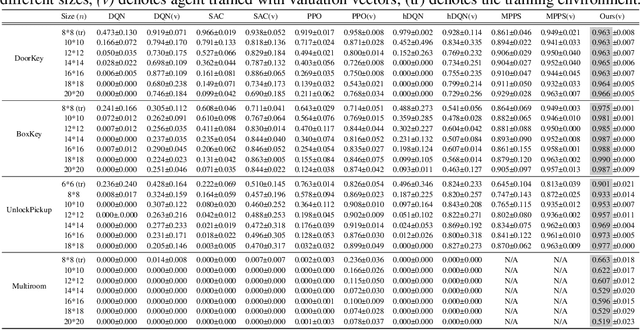
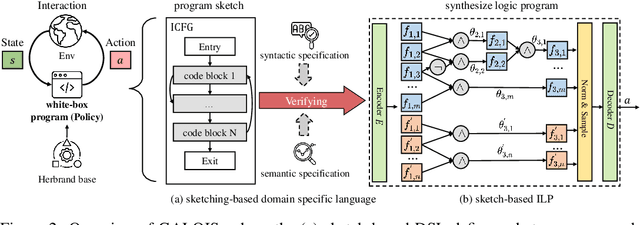
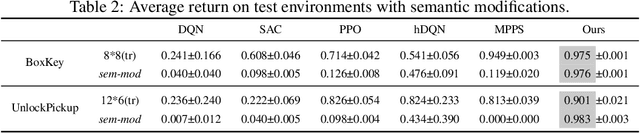
Despite achieving superior performance in human-level control problems, unlike humans, deep reinforcement learning (DRL) lacks high-order intelligence (e.g., logic deduction and reuse), thus it behaves ineffectively than humans regarding learning and generalization in complex problems. Previous works attempt to directly synthesize a white-box logic program as the DRL policy, manifesting logic-driven behaviors. However, most synthesis methods are built on imperative or declarative programming, and each has a distinct limitation, respectively. The former ignores the cause-effect logic during synthesis, resulting in low generalizability across tasks. The latter is strictly proof-based, thus failing to synthesize programs with complex hierarchical logic. In this paper, we combine the above two paradigms together and propose a novel Generalizable Logic Synthesis (GALOIS) framework to synthesize hierarchical and strict cause-effect logic programs. GALOIS leverages the program sketch and defines a new sketch-based hybrid program language for guiding the synthesis. Based on that, GALOIS proposes a sketch-based program synthesis method to automatically generate white-box programs with generalizable and interpretable cause-effect logic. Extensive evaluations on various decision-making tasks with complex logic demonstrate the superiority of GALOIS over mainstream baselines regarding the asymptotic performance, generalizability, and great knowledge reusability across different environments.
Unveiling Project-Specific Bias in Neural Code Models
Jan 19, 2022

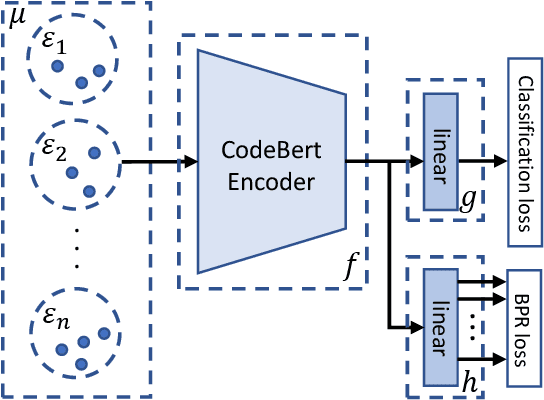
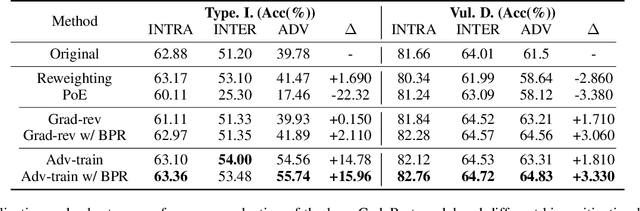
Neural code models have introduced significant improvements over many software analysis tasks like type inference, vulnerability detection, etc. Despite the good performance of such models under the common intra-project independent and identically distributed (IID) training and validation setting, we observe that they usually fail to generalize to real-world inter-project out-of-distribution (OOD) setting. In this work, we show that such phenomenon is caused by model heavily relying on project-specific, ungeneralizable tokens like self-defined variable and function names for downstream prediction, and we formulate it as the project-specific bias learning behavior. We propose a measurement to interpret such behavior, termed as Cond-Idf, which combines co-occurrence probability and inverse document frequency to measure the level of relatedness of token with label and its project-specificness. The approximation indicates that without proper regularization with prior knowledge, model tends to leverage spurious statistical cues for prediction. Equipped with these observations, we propose a bias mitigation mechanism Batch Partition Regularization (BPR) that regularizes model to infer based on proper behavior by leveraging latent logic relations among samples. Experimental results on two deep code benchmarks indicate that BPR can improve both inter-project OOD generalization and adversarial robustness while not sacrificing accuracy on IID data.
Fairness Matters -- A Data-Driven Framework Towards Fair and High Performing Facial Recognition Systems
Sep 16, 2020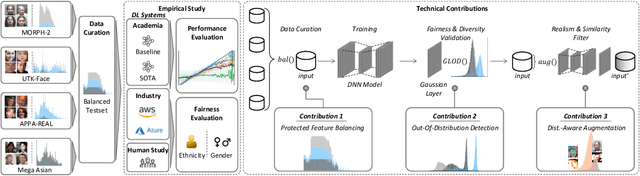


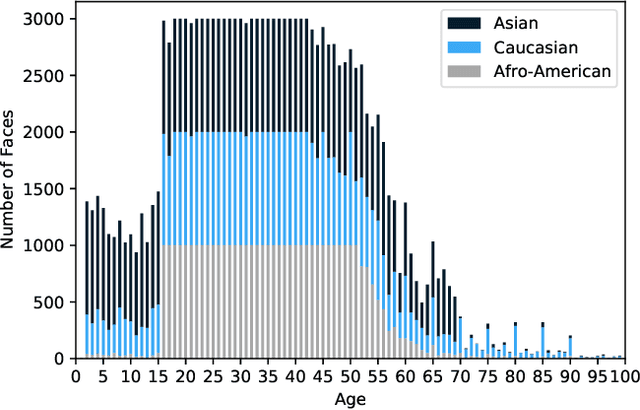
Facial recognition technologies are widely used in governmental and industrial applications. Together with the advancements in deep learning (DL), human-centric tasks such as accurate age prediction based on face images become feasible. However, the issue of fairness when predicting the age for different ethnicity and gender remains an open problem. Policing systems use age to estimate the likelihood of someone to commit a crime, where younger suspects tend to be more likely involved. Unfair age prediction may lead to unfair treatment of humans not only in crime prevention but also in marketing, identity acquisition and authentication. Therefore, this work follows two parts. First, an empirical study is conducted evaluating performance and fairness of state-of-the-art systems for age prediction including baseline and most recent works of academia and the main industrial service providers (Amazon AWS and Microsoft Azure). Building on the findings we present a novel approach to mitigate unfairness and enhance performance, using distribution-aware dataset curation and augmentation. Distribution-awareness is based on out-of-distribution detection which is utilized to validate equal and diverse DL system behavior towards e.g. ethnicity and gender. In total we train 24 DNN models and utilize one million data points to assess performance and fairness of the state-of-the-art for face recognition algorithms. We demonstrate an improvement in mean absolute age prediction error from 7.70 to 3.39 years and a 4-fold increase in fairness towards ethnicity when compared to related work. Utilizing the presented methodology we are able to outperform leading industry players such as Amazon AWS or Microsoft Azure in both fairness and age prediction accuracy and provide the necessary guidelines to assess quality and enhance face recognition systems based on DL techniques.