 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning More from Less: Exploiting Counterfactuals for Data-Efficient Chart Understanding
May 11, 2026Vision-Language Models (VLMs) have demonstrated remarkable progress in chart understanding, largely driven by supervised fine-tuning (SFT) on increasingly large synthetic datasets. However, scaling SFT data alone is inefficient and overlooks a key property of charts: charts are programmatically generated visual artifacts, where small, code-controlled visual changes can induce drastic shifts in semantics and correct answers. Learning this counterfactual sensitivity requires VLMs to discriminate fine-grained visual differences, yet standard SFT treats training instances independently and provides limited supervision to enforce this behavior. To address this, we introduce ChartCF, a data-efficient training framework designed to enhance counterfactual sensitivity. ChartCF consists of: (1) a counterfactual data synthesis pipeline via code modification, (2) a chart similarity-based data selection strategy that filters overly difficult samples for improved training efficiency, and (3) multimodal preference optimization across both textual and visual modalities. Experiments on five benchmarks show that ChartCF achieves superior or comparable performance to strong chart-specific VLMs while using significantly less training data.
Logic-guided Deep Reinforcement Learning for Stock Trading
Oct 09, 2023



Deep reinforcement learning (DRL) has revolutionized quantitative finance by achieving excellent performance without significant manual effort. Whereas we observe that the DRL models behave unstably in a dynamic stock market due to the low signal-to-noise ratio nature of the financial data. In this paper, we propose a novel logic-guided trading framework, termed as SYENS (Program Synthesis-based Ensemble Strategy). Different from the previous state-of-the-art ensemble reinforcement learning strategy which arbitrarily selects the best-performing agent for testing based on a single measurement, our framework proposes regularizing the model's behavior in a hierarchical manner using the program synthesis by sketching paradigm. First, we propose a high-level, domain-specific language (DSL) that is used for the depiction of the market environment and action. Then based on the DSL, a novel program sketch is introduced, which embeds human expert knowledge in a logical manner. Finally, based on the program sketch, we adopt the program synthesis by sketching a paradigm and synthesizing a logical, hierarchical trading strategy. We evaluate SYENS on the 30 Dow Jones stocks under the cash trading and the margin trading settings. Experimental results demonstrate that our proposed framework can significantly outperform the baselines with much higher cumulative return and lower maximum drawdown under both settings.
Unveiling Project-Specific Bias in Neural Code Models
Jan 19, 2022

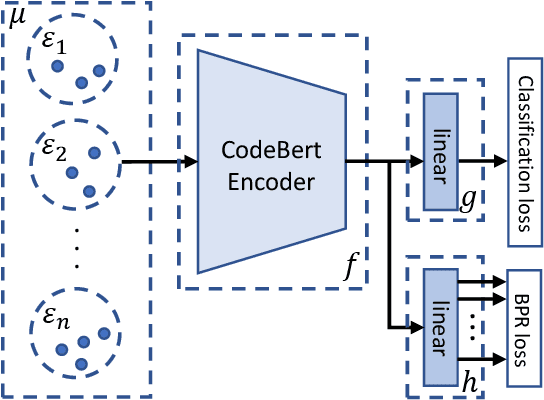
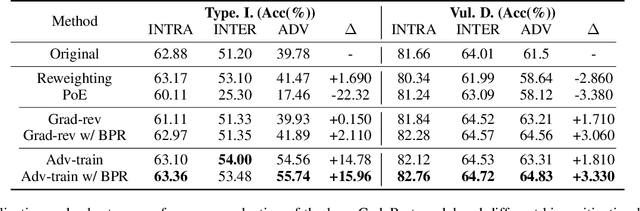
Neural code models have introduced significant improvements over many software analysis tasks like type inference, vulnerability detection, etc. Despite the good performance of such models under the common intra-project independent and identically distributed (IID) training and validation setting, we observe that they usually fail to generalize to real-world inter-project out-of-distribution (OOD) setting. In this work, we show that such phenomenon is caused by model heavily relying on project-specific, ungeneralizable tokens like self-defined variable and function names for downstream prediction, and we formulate it as the project-specific bias learning behavior. We propose a measurement to interpret such behavior, termed as Cond-Idf, which combines co-occurrence probability and inverse document frequency to measure the level of relatedness of token with label and its project-specificness. The approximation indicates that without proper regularization with prior knowledge, model tends to leverage spurious statistical cues for prediction. Equipped with these observations, we propose a bias mitigation mechanism Batch Partition Regularization (BPR) that regularizes model to infer based on proper behavior by leveraging latent logic relations among samples. Experimental results on two deep code benchmarks indicate that BPR can improve both inter-project OOD generalization and adversarial robustness while not sacrificing accuracy on IID data.
Why an Android App is Classified as Malware? Towards Malware Classification Interpretation
Apr 24, 2020

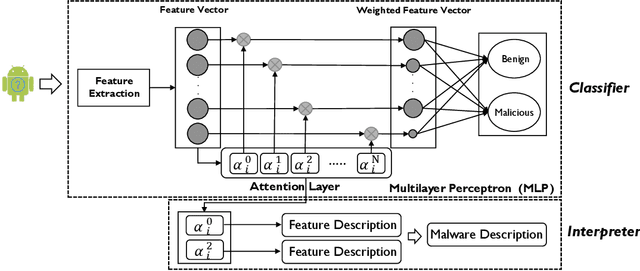

Machine learning (ML) based approach is considered as one of the most promising techniques for Android malware detection and has achieved high accuracy by leveraging commonly-used features. In practice, most of the ML classifications only provide a binary label to mobile users and app security analysts. However, stakeholders are more interested in the reason why apps are classified as malicious in both academia and industry. This belongs to the research area of interpretable ML but in a specific research domain (i.e., mobile malware detection). Although several interpretable ML methods have been exhibited to explain the final classification results in many cutting-edge Artificial Intelligent (AI) based research fields, till now, there is no study interpreting why an app is classified as malware or unveiling the domain-specific challenges. In this paper, to fill this gap, we propose a novel and interpretable ML-based approach (named XMal) to classify malware with high accuracy and explain the classification result meanwhile. (1) The first classification phase of XMal hinges multi-layer perceptron (MLP) and attention mechanism, and also pinpoints the key features most related to the classification result. (2) The second interpreting phase aims at automatically producing neural language descriptions to interpret the core malicious behaviors within apps. We evaluate the behavior description results by comparing with the existing interpretable ML-based methods (i.e., Drebin and LIME) to demonstrate the effectiveness of XMal. We find that XMal is able to reveal the malicious behaviors more accurately. Additionally, our experiments show that XMal can also interpret the reason why some samples are misclassified by ML classifiers. Our study peeks into the interpretable ML through the research of Android malware detection and analysis.