 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Bugs in Open-Source Federated Learning Framework
Aug 09, 2023



Federated learning (FL), as a decentralized machine learning solution to the protection of users' private data, has become an important learning paradigm in recent years, especially since the enforcement of stricter laws and regulations in most countries. Therefore, a variety of FL frameworks are released to facilitate the development and application of federated learning. Despite the considerable amount of research on the security and privacy of FL models and systems, the security issues in FL frameworks have not been systematically studied yet. In this paper, we conduct the first empirical study on 1,112 FL framework bugs to investigate their characteristics. These bugs are manually collected, classified, and labeled from 12 open-source FL frameworks on GitHub. In detail, we construct taxonomies of 15 symptoms, 12 root causes, and 20 fix patterns of these bugs and investigate their correlations and distributions on 23 logical components and two main application scenarios. From the results of our study, we present nine findings, discuss their implications, and propound several suggestions to FL framework developers and security researchers on the FL frameworks.
Experimental Realization of Convolution Processing in Photonic Synthetic Frequency Dimensions
May 05, 2023Convolution is an essential operation in signal and image processing and consumes most of the computing power in convolutional neural networks. Photonic convolution has the promise of addressing computational bottlenecks and outperforming electronic implementations. Performing photonic convolution in the synthetic frequency dimension, which harnesses the dynamics of light in the spectral degrees of freedom for photons, can lead to highly compact devices. Here we experimentally realize convolution operations in the synthetic frequency dimension. Using a modulated ring resonator, we synthesize arbitrary convolution kernels using a pre-determined modulation waveform with high accuracy. We demonstrate the convolution computation between input frequency combs and synthesized kernels. We also introduce the idea of an additive offset to broaden the kinds of kernels that can be implemented experimentally when the modulation strength is limited. Our work demonstrate the use of synthetic frequency dimension to efficiently encode data and implement computation tasks, leading to a compact and scalable photonic computation architecture.
Towards Understanding and Mitigating Audio Adversarial Examples for Speaker Recognition
Jun 07, 2022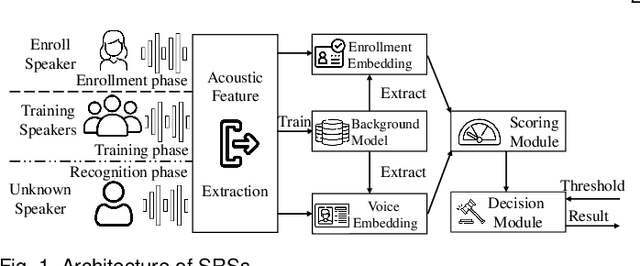

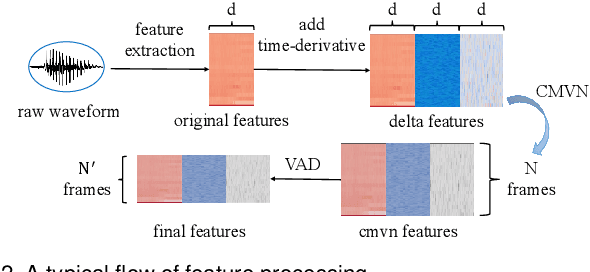
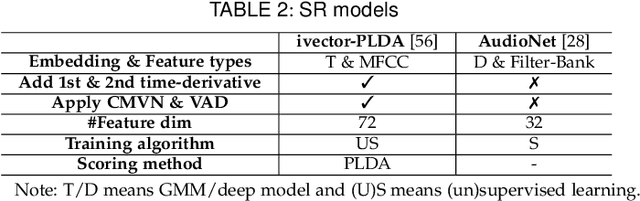
Speaker recognition systems (SRSs) have recently been shown to be vulnerable to adversarial attacks, raising significant security concerns. In this work, we systematically investigate transformation and adversarial training based defenses for securing SRSs. According to the characteristic of SRSs, we present 22 diverse transformations and thoroughly evaluate them using 7 recent promising adversarial attacks (4 white-box and 3 black-box) on speaker recognition. With careful regard for best practices in defense evaluations, we analyze the strength of transformations to withstand adaptive attacks. We also evaluate and understand their effectiveness against adaptive attacks when combined with adversarial training. Our study provides lots of useful insights and findings, many of them are new or inconsistent with the conclusions in the image and speech recognition domains, e.g., variable and constant bit rate speech compressions have different performance, and some non-differentiable transformations remain effective against current promising evasion techniques which often work well in the image domain. We demonstrate that the proposed novel feature-level transformation combined with adversarial training is rather effective compared to the sole adversarial training in a complete white-box setting, e.g., increasing the accuracy by 13.62% and attack cost by two orders of magnitude, while other transformations do not necessarily improve the overall defense capability. This work sheds further light on the research directions in this field. We also release our evaluation platform SPEAKERGUARD to foster further research.
AS2T: Arbitrary Source-To-Target Adversarial Attack on Speaker Recognition Systems
Jun 07, 2022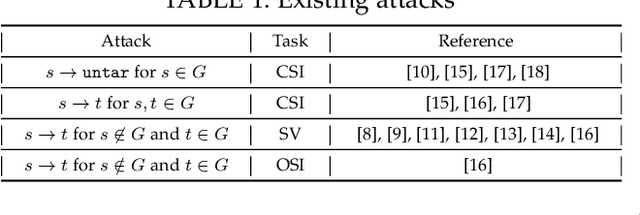


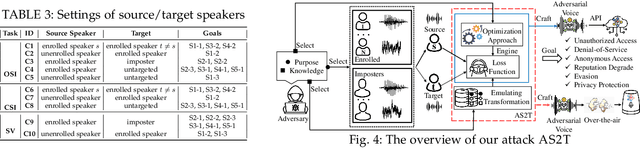
Recent work has illuminated the vulnerability of speaker recognition systems (SRSs) against adversarial attacks, raising significant security concerns in deploying SRSs. However, they considered only a few settings (e.g., some combinations of source and target speakers), leaving many interesting and important settings in real-world attack scenarios alone. In this work, we present AS2T, the first attack in this domain which covers all the settings, thus allows the adversary to craft adversarial voices using arbitrary source and target speakers for any of three main recognition tasks. Since none of the existing loss functions can be applied to all the settings, we explore many candidate loss functions for each setting including the existing and newly designed ones. We thoroughly evaluate their efficacy and find that some existing loss functions are suboptimal. Then, to improve the robustness of AS2T towards practical over-the-air attack, we study the possible distortions occurred in over-the-air transmission, utilize different transformation functions with different parameters to model those distortions, and incorporate them into the generation of adversarial voices. Our simulated over-the-air evaluation validates the effectiveness of our solution in producing robust adversarial voices which remain effective under various hardware devices and various acoustic environments with different reverberation, ambient noises, and noise levels. Finally, we leverage AS2T to perform thus far the largest-scale evaluation to understand transferability among 14 diverse SRSs. The transferability analysis provides many interesting and useful insights which challenge several findings and conclusion drawn in previous works in the image domain. Our study also sheds light on future directions of adversarial attacks in the speaker recognition domain.
SEC4SR: A Security Analysis Platform for Speaker Recognition
Sep 04, 2021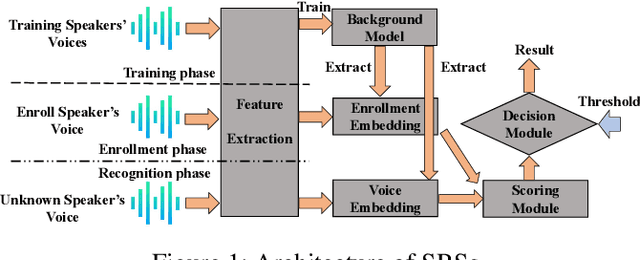
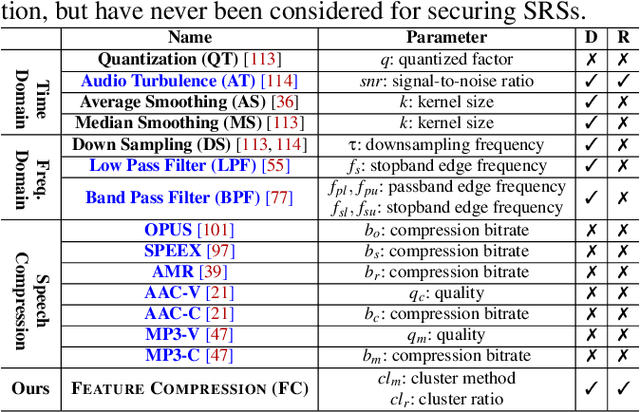
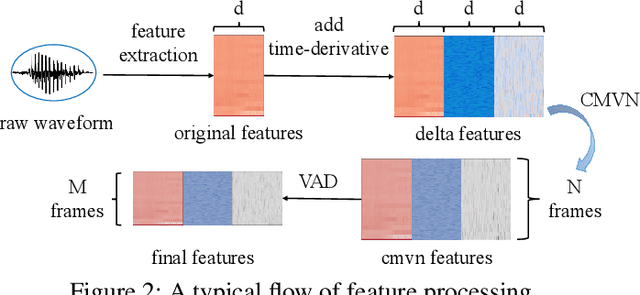
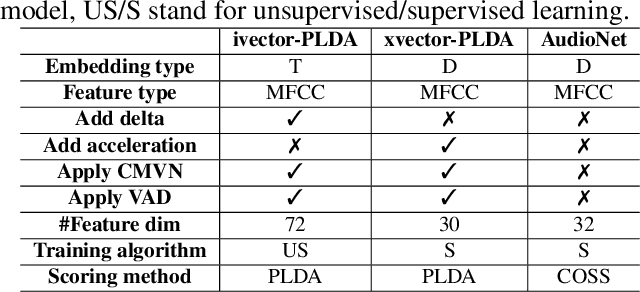
Adversarial attacks have been expanded to speaker recognition (SR). However, existing attacks are often assessed using different SR models, recognition tasks and datasets, and only few adversarial defenses borrowed from computer vision are considered. Yet,these defenses have not been thoroughly evaluated against adaptive attacks. Thus, there is still a lack of quantitative understanding about the strengths and limitations of adversarial attacks and defenses. More effective defenses are also required for securing SR systems. To bridge this gap, we present SEC4SR, the first platform enabling researchers to systematically and comprehensively evaluate adversarial attacks and defenses in SR. SEC4SR incorporates 4 white-box and 2 black-box attacks, 24 defenses including our novel feature-level transformations. It also contains techniques for mounting adaptive attacks. Using SEC4SR, we conduct thus far the largest-scale empirical study on adversarial attacks and defenses in SR, involving 23 defenses, 15 attacks and 4 attack settings. Our study provides lots of useful findings that may advance future research: such as (1) all the transformations slightly degrade accuracy on benign examples and their effectiveness vary with attacks; (2) most transformations become less effective under adaptive attacks, but some transformations become more effective; (3) few transformations combined with adversarial training yield stronger defenses over some but not all attacks, while our feature-level transformation combined with adversarial training yields the strongest defense over all the attacks. Extensive experiments demonstrate capabilities and advantages of SEC4SR which can benefit future research in SR.
Why an Android App is Classified as Malware? Towards Malware Classification Interpretation
Apr 24, 2020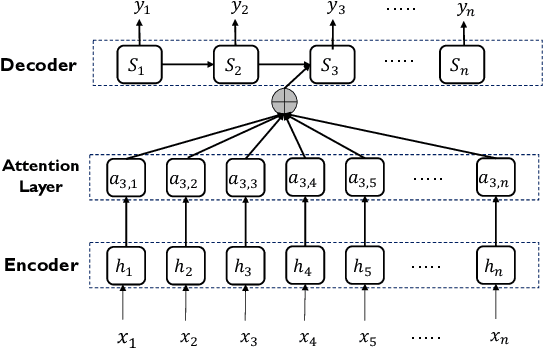

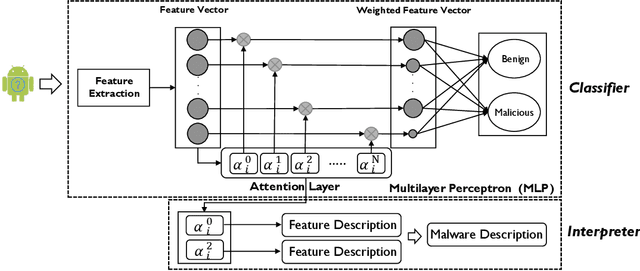

Machine learning (ML) based approach is considered as one of the most promising techniques for Android malware detection and has achieved high accuracy by leveraging commonly-used features. In practice, most of the ML classifications only provide a binary label to mobile users and app security analysts. However, stakeholders are more interested in the reason why apps are classified as malicious in both academia and industry. This belongs to the research area of interpretable ML but in a specific research domain (i.e., mobile malware detection). Although several interpretable ML methods have been exhibited to explain the final classification results in many cutting-edge Artificial Intelligent (AI) based research fields, till now, there is no study interpreting why an app is classified as malware or unveiling the domain-specific challenges. In this paper, to fill this gap, we propose a novel and interpretable ML-based approach (named XMal) to classify malware with high accuracy and explain the classification result meanwhile. (1) The first classification phase of XMal hinges multi-layer perceptron (MLP) and attention mechanism, and also pinpoints the key features most related to the classification result. (2) The second interpreting phase aims at automatically producing neural language descriptions to interpret the core malicious behaviors within apps. We evaluate the behavior description results by comparing with the existing interpretable ML-based methods (i.e., Drebin and LIME) to demonstrate the effectiveness of XMal. We find that XMal is able to reveal the malicious behaviors more accurately. Additionally, our experiments show that XMal can also interpret the reason why some samples are misclassified by ML classifiers. Our study peeks into the interpretable ML through the research of Android malware detection and analysis.
Advanced Evasion Attacks and Mitigations on Practical ML-Based Phishing Website Classifiers
Apr 15, 2020
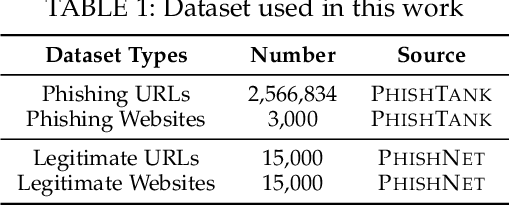
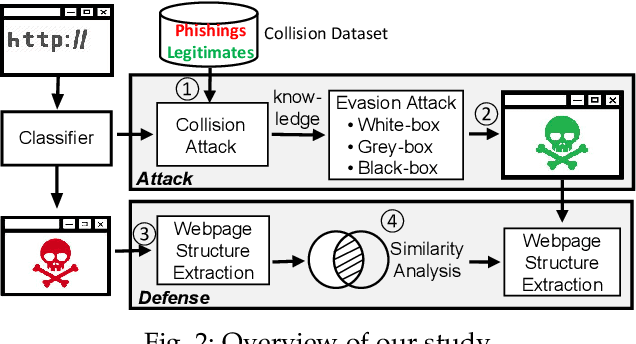
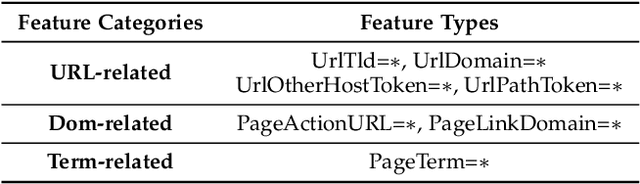
Machine learning (ML) based approaches have been the mainstream solution for anti-phishing detection. When they are deployed on the client-side, ML-based classifiers are vulnerable to evasion attacks. However, such potential threats have received relatively little attention because existing attacks destruct the functionalities or appearance of webpages and are conducted in the white-box scenario, making it less practical. Consequently, it becomes imperative to understand whether it is possible to launch evasion attacks with limited knowledge of the classifier, while preserving the functionalities and appearance. In this work, we show that even in the grey-, and black-box scenarios, evasion attacks are not only effective on practical ML-based classifiers, but can also be efficiently launched without destructing the functionalities and appearance. For this purpose, we propose three mutation-based attacks, differing in the knowledge of the target classifier, addressing a key technical challenge: automatically crafting an adversarial sample from a known phishing website in a way that can mislead classifiers. To launch attacks in the white- and grey-box scenarios, we also propose a sample-based collision attack to gain the knowledge of the target classifier. We demonstrate the effectiveness and efficiency of our evasion attacks on the state-of-the-art, Google's phishing page filter, achieved 100% attack success rate in less than one second per website. Moreover, the transferability attack on BitDefender's industrial phishing page classifier, TrafficLight, achieved up to 81.25% attack success rate. We further propose a similarity-based method to mitigate such evasion attacks, Pelican. We demonstrate that Pelican can effectively detect evasion attacks. Our findings contribute to design more robust phishing website classifiers in practice.
CORE: Automating Review Recommendation for Code Changes
Dec 20, 2019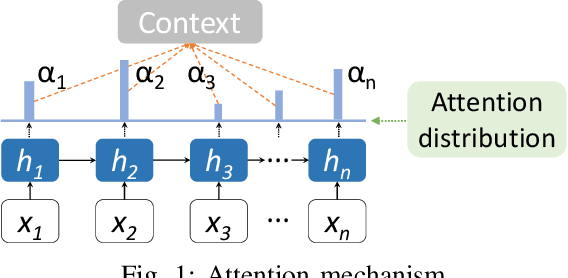
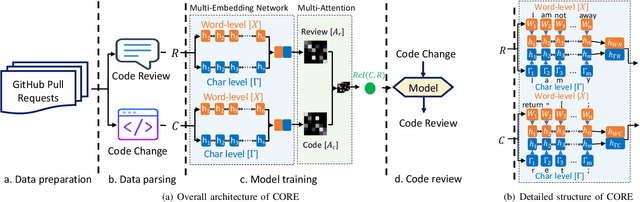
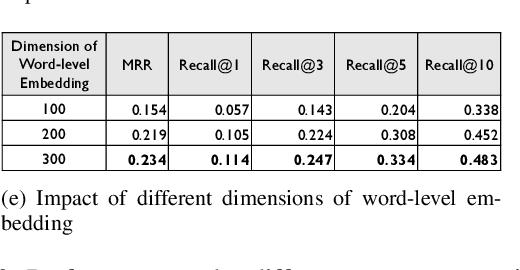
Code review is a common process that is used by developers, in which a reviewer provides useful comments or points out defects in the submitted source code changes via pull request. Code review has been widely used for both industry and open-source projects due to its capacity in early defect identification, project maintenance, and code improvement. With rapid updates on project developments, code review becomes a non-trivial and labor-intensive task for reviewers. Thus, an automated code review engine can be beneficial and useful for project development in practice. Although there exist prior studies on automating the code review process by adopting static analysis tools or deep learning techniques, they often require external sources such as partial or full source code for accurate review suggestion. In this paper, we aim at automating the code review process only based on code changes and the corresponding reviews but with better performance. The hinge of accurate code review suggestion is to learn good representations for both code changes and reviews. To achieve this with limited source, we design a multi-level embedding (i.e., word embedding and character embedding) approach to represent the semantics provided by code changes and reviews. The embeddings are then well trained through a proposed attentional deep learning model, as a whole named CORE. We evaluate the effectiveness of CORE on code changes and reviews collected from 19 popular Java projects hosted on Github. Experimental results show that our model CORE can achieve significantly better performance than the state-of-the-art model (DeepMem), with an increase of 131.03% in terms of Recall@10 and 150.69% in terms of Mean Reciprocal Rank. Qualitative general word analysis among project developers also demonstrates the performance of CORE in automating code review.
Who is Real Bob? Adversarial Attacks on Speaker Recognition Systems
Nov 03, 2019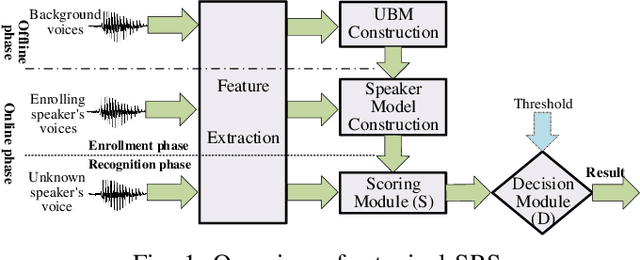
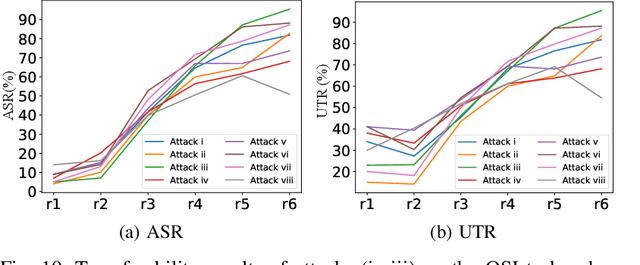


Speaker recognition (SR) is widely used in our daily life as a biometric authentication mechanism. The popularity of SR brings in serious security concerns, as demonstrated by recent adversarial attacks. However, the impacts of such threats in the practical black-box setting are still open, since current attacks consider the white-box setting only. In this paper, we conduct the first comprehensive and systematic study of the adversarial attacks on SR systems (SRSs) to understand their security weakness in the practical black-box setting. For this purpose, we propose an adversarial attack, named FakeBob, to craft adversarial samples. Specifically, we formulate the adversarial sample generation as an optimization problem, incorporated with the confidence of adversarial samples and maximal distortion to balance between the strength and imperceptibility of adversarial voices. One key contribution is to propose a novel algorithm to estimate the score threshold, a feature in SRSs, and use it in the optimization problem to solve the optimization problem. We demonstrate that FakeBob achieves close to 100% targeted attack success rate on both open-source and commercial systems. We further demonstrate that FakeBob is also effective (at least 65% untargeted success rate) on both open-source and commercial systems when playing over the air in the physical world. Moreover, we have conducted a human study which reveals that it is hard for human to differentiate the speakers of the original and adversarial voices. Last but not least, we show that three promising defense methods for adversarial attack from the speech recognition domain become ineffective on SRSs against FakeBob, which calls for more effective defense methods. We highlight that our study peeks into the security implications of adversarial attacks on SRSs, and realistically fosters to improve the security robustness of SRSs.