 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASMA-Tune: Unlocking LLMs' Assembly Code Comprehension via Structural-Semantic Instruction Tuning
Mar 14, 2025Analysis and comprehension of assembly code are crucial in various applications, such as reverse engineering. However, the low information density and lack of explicit syntactic structures in assembly code pose significant challenges. Pioneering approaches with masked language modeling (MLM)-based methods have been limited by facilitating natural language interaction. While recent methods based on decoder-focused large language models (LLMs) have significantly enhanced semantic representation, they still struggle to capture the nuanced and sparse semantics in assembly code. In this paper, we propose Assembly Augmented Tuning (ASMA-Tune), an end-to-end structural-semantic instruction-tuning framework. Our approach synergizes encoder architectures with decoder-based LLMs through projector modules to enable comprehensive code understanding. Experiments show that ASMA-Tune outperforms existing benchmarks, significantly enhancing assembly code comprehension and instruction-following abilities. Our model and dataset are public at https://github.com/wxy3596/ASMA-Tune.
Towards Understanding and Mitigating Audio Adversarial Examples for Speaker Recognition
Jun 07, 2022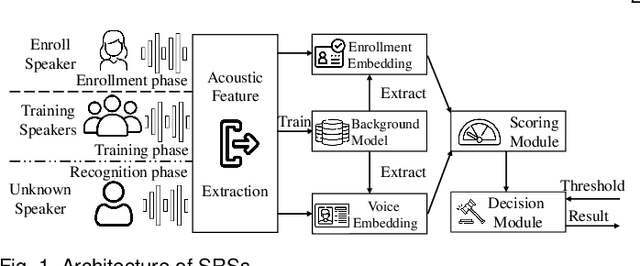

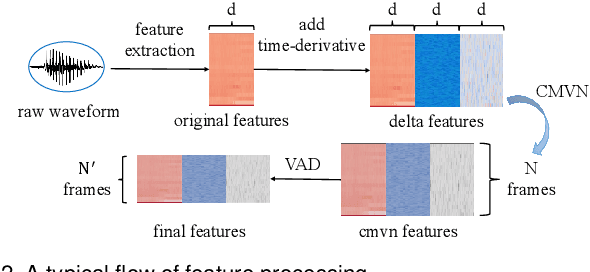
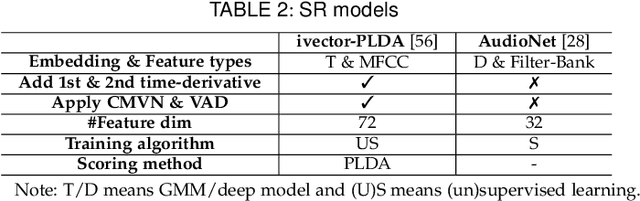
Speaker recognition systems (SRSs) have recently been shown to be vulnerable to adversarial attacks, raising significant security concerns. In this work, we systematically investigate transformation and adversarial training based defenses for securing SRSs. According to the characteristic of SRSs, we present 22 diverse transformations and thoroughly evaluate them using 7 recent promising adversarial attacks (4 white-box and 3 black-box) on speaker recognition. With careful regard for best practices in defense evaluations, we analyze the strength of transformations to withstand adaptive attacks. We also evaluate and understand their effectiveness against adaptive attacks when combined with adversarial training. Our study provides lots of useful insights and findings, many of them are new or inconsistent with the conclusions in the image and speech recognition domains, e.g., variable and constant bit rate speech compressions have different performance, and some non-differentiable transformations remain effective against current promising evasion techniques which often work well in the image domain. We demonstrate that the proposed novel feature-level transformation combined with adversarial training is rather effective compared to the sole adversarial training in a complete white-box setting, e.g., increasing the accuracy by 13.62% and attack cost by two orders of magnitude, while other transformations do not necessarily improve the overall defense capability. This work sheds further light on the research directions in this field. We also release our evaluation platform SPEAKERGUARD to foster further research.