 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOG-HFYOLO :Orientation gradient guidance and heterogeneous feature fusion for deformation table cell instance segmentation
Apr 29, 2025Table structure recognition is a key task in document analysis. However, the geometric deformation in deformed tables causes a weak correlation between content information and structure, resulting in downstream tasks not being able to obtain accurate content information. To obtain fine-grained spatial coordinates of cells, we propose the OG-HFYOLO model, which enhances the edge response by Gradient Orientation-aware Extractor, combines a Heterogeneous Kernel Cross Fusion module and a scale-aware loss function to adapt to multi-scale objective features, and introduces mask-driven non-maximal suppression in the post-processing, which replaces the traditional bounding box suppression mechanism. Furthermore, we also propose a data generator, filling the gap in the dataset for fine-grained deformation table cell spatial coordinate localization, and derive a large-scale dataset named Deformation Wired Table (DWTAL). Experiments show that our proposed model demonstrates excellent segmentation accuracy on all mainstream instance segmentation models. The dataset and the source code are open source: https://github.com/justliulong/OGHFYOLO.
ASMA-Tune: Unlocking LLMs' Assembly Code Comprehension via Structural-Semantic Instruction Tuning
Mar 14, 2025Analysis and comprehension of assembly code are crucial in various applications, such as reverse engineering. However, the low information density and lack of explicit syntactic structures in assembly code pose significant challenges. Pioneering approaches with masked language modeling (MLM)-based methods have been limited by facilitating natural language interaction. While recent methods based on decoder-focused large language models (LLMs) have significantly enhanced semantic representation, they still struggle to capture the nuanced and sparse semantics in assembly code. In this paper, we propose Assembly Augmented Tuning (ASMA-Tune), an end-to-end structural-semantic instruction-tuning framework. Our approach synergizes encoder architectures with decoder-based LLMs through projector modules to enable comprehensive code understanding. Experiments show that ASMA-Tune outperforms existing benchmarks, significantly enhancing assembly code comprehension and instruction-following abilities. Our model and dataset are public at https://github.com/wxy3596/ASMA-Tune.
Physics-Guided Detector for SAR Airplanes
Nov 19, 2024The disperse structure distributions (discreteness) and variant scattering characteristics (variability) of SAR airplane targets lead to special challenges of object detection and recognition. The current deep learning-based detectors encounter challenges in distinguishing fine-grained SAR airplanes against complex backgrounds. To address it, we propose a novel physics-guided detector (PGD) learning paradigm for SAR airplanes that comprehensively investigate their discreteness and variability to improve the detection performance. It is a general learning paradigm that can be extended to different existing deep learning-based detectors with "backbone-neck-head" architectures. The main contributions of PGD include the physics-guided self-supervised learning, feature enhancement, and instance perception, denoted as PGSSL, PGFE, and PGIP, respectively. PGSSL aims to construct a self-supervised learning task based on a wide range of SAR airplane targets that encodes the prior knowledge of various discrete structure distributions into the embedded space. Then, PGFE enhances the multi-scale feature representation of a detector, guided by the physics-aware information learned from PGSSL. PGIP is constructed at the detection head to learn the refined and dominant scattering point of each SAR airplane instance, thus alleviating the interference from the complex background. We propose two implementations, denoted as PGD and PGD-Lite, and apply them to various existing detectors with different backbones and detection heads. The experiments demonstrate the flexibility and effectiveness of the proposed PGD, which can improve existing detectors on SAR airplane detection with fine-grained classification task (an improvement of 3.1\% mAP most), and achieve the state-of-the-art performance (90.7\% mAP) on SAR-AIRcraft-1.0 dataset. The project is open-source at \url{https://github.com/XAI4SAR/PGD}.
BlueLM-V-3B: Algorithm and System Co-Design for Multimodal Large Language Models on Mobile Devices
Nov 16, 2024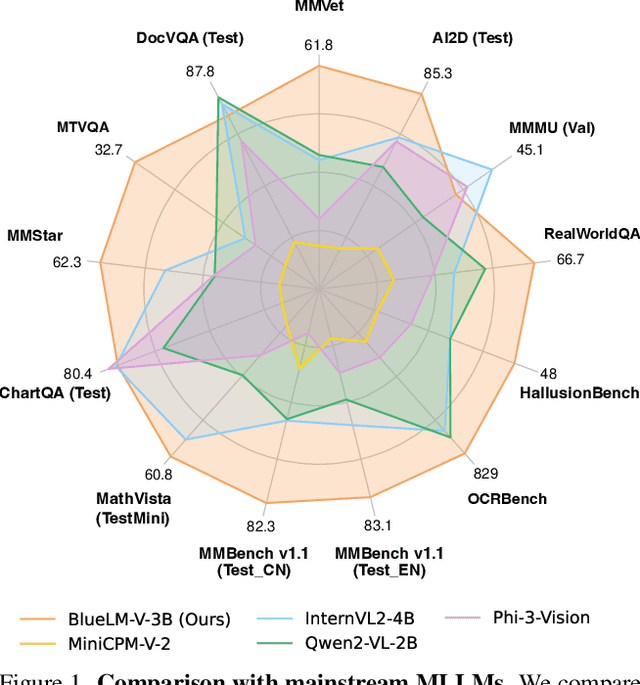
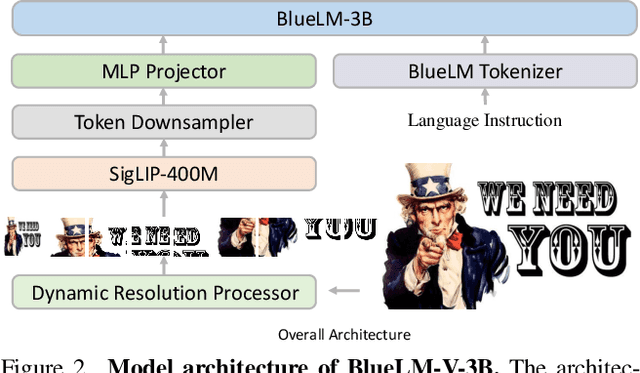

The emergence and growing popularity of multimodal large language models (MLLMs) have significant potential to enhance various aspects of daily life, from improving communication to facilitating learning and problem-solving. Mobile phones, as essential daily companions, represent the most effective and accessible deployment platform for MLLMs, enabling seamless integration into everyday tasks. However, deploying MLLMs on mobile phones presents challenges due to limitations in memory size and computational capability, making it difficult to achieve smooth and real-time processing without extensive optimization. In this paper, we present BlueLM-V-3B, an algorithm and system co-design approach specifically tailored for the efficient deployment of MLLMs on mobile platforms. To be specific, we redesign the dynamic resolution scheme adopted by mainstream MLLMs and implement system optimization for hardware-aware deployment to optimize model inference on mobile phones. BlueLM-V-3B boasts the following key highlights: (1) Small Size: BlueLM-V-3B features a language model with 2.7B parameters and a vision encoder with 400M parameters. (2) Fast Speed: BlueLM-V-3B achieves a generation speed of 24.4 token/s on the MediaTek Dimensity 9300 processor with 4-bit LLM weight quantization. (3) Strong Performance: BlueLM-V-3B has attained the highest average score of 66.1 on the OpenCompass benchmark among models with $\leq$ 4B parameters and surpassed a series of models with much larger parameter sizes (e.g., MiniCPM-V-2.6, InternVL2-8B).
Semantic Model Component Implementation for Model-driven Semantic Communications
Sep 27, 2024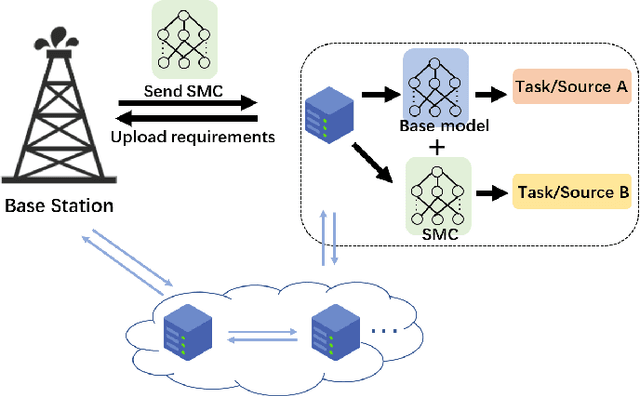

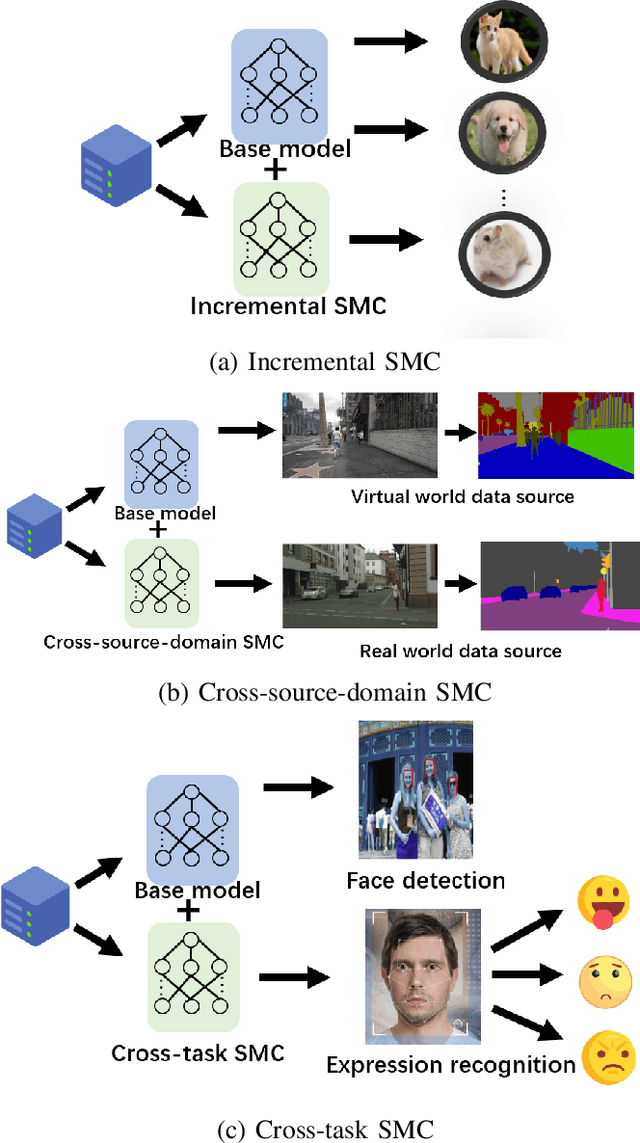
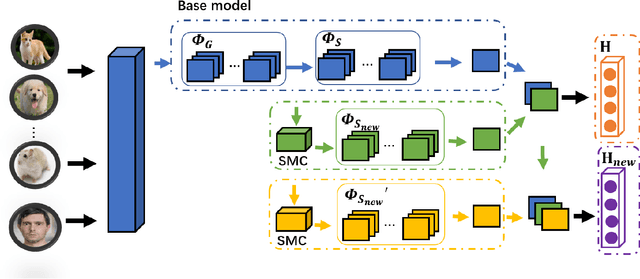
The key feature of model-driven semantic communication is the propagation of the model. The semantic model component (SMC) is designed to drive the intelligent model to transmit in the physical channel, allowing the intelligence to flow through the networks. According to the characteristics of neural networks with common and individual model parameters, this paper designs the cross-source-domain and cross-task semantic component model. Considering that the basic model is deployed on the edge node, the large server node updates the edge node by transmitting only the semantic component model to the edge node so that the edge node can handle different sources and different tasks. In addition, this paper also discusses how channel noise affects the performance of the model and proposes methods of injection noise and regularization to improve the noise resistance of the model. Experiments show that SMCs use smaller model parameters to achieve cross-source, cross-task functionality while maintaining performance and improving the model's tolerance to noise. Finally, a component transfer-based unmanned vehicle tracking prototype was implemented to verify the feasibility of model components in practical applications.
Active Generation Network of Human Skeleton for Action Recognition
Jan 30, 2024Data generation is a data augmentation technique for enhancing the generalization ability for skeleton-based human action recognition. Most existing data generation methods face challenges to ensure the temporal consistency of the dynamic information for action. In addition, the data generated by these methods lack diversity when only a few training samples are available. To solve those problems, We propose a novel active generative network (AGN), which can adaptively learn various action categories by motion style transfer to generate new actions when the data for a particular action is only a single sample or few samples. The AGN consists of an action generation network and an uncertainty metric network. The former, with ST-GCN as the Backbone, can implicitly learn the morphological features of the target action while preserving the category features of the source action. The latter guides generating actions. Specifically, an action recognition model generates prediction vectors for each action, which is then scored using an uncertainty metric. Finally, UMN provides the uncertainty sampling basis for the generated actions.
Dynamic Domain Discrepancy Adjustment for Active Multi-Domain Adaptation
Jul 26, 2023Multi-source unsupervised domain adaptation (MUDA) aims to transfer knowledge from related source domains to an unlabeled target domain. While recent MUDA methods have shown promising results, most focus on aligning the overall feature distributions across source domains, which can lead to negative effects due to redundant features within each domain. Moreover, there is a significant performance gap between MUDA and supervised methods. To address these challenges, we propose a novel approach called Dynamic Domain Discrepancy Adjustment for Active Multi-Domain Adaptation (D3AAMDA). Firstly, we establish a multi-source dynamic modulation mechanism during the training process based on the degree of distribution differences between source and target domains. This mechanism controls the alignment level of features between each source domain and the target domain, effectively leveraging the local advantageous feature information within the source domains. Additionally, we propose a Multi-source Active Boundary Sample Selection (MABS) strategy, which utilizes a guided dynamic boundary loss to design an efficient query function for selecting important samples. This strategy achieves improved generalization to the target domain with minimal sampling costs. We extensively evaluate our proposed method on commonly used domain adaptation datasets, comparing it against existing UDA and ADA methods. The experimental results unequivocally demonstrate the superiority of our approach.
Improving Knowledge Distillation Via Transferring Learning Ability
Apr 24, 2023Existing knowledge distillation methods generally use a teacher-student approach, where the student network solely learns from a well-trained teacher. However, this approach overlooks the inherent differences in learning abilities between the teacher and student networks, thus causing the capacity-gap problem. To address this limitation, we propose a novel method called SLKD.