 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhoStream: Benchmarking Real-World Streaming for Omnimodal Assistants in Mobile Scenarios
Jan 30, 2026Multimodal Large Language Models excel at offline audio-visual understanding, but their ability to serve as mobile assistants in continuous real-world streams remains underexplored. In daily phone use, mobile assistants must track streaming audio-visual inputs and respond at the right time, yet existing benchmarks are often restricted to multiple-choice questions or use shorter videos. In this paper, we introduce PhoStream, the first mobile-centric streaming benchmark that unifies on-screen and off-screen scenarios to evaluate video, audio, and temporal reasoning. PhoStream contains 5,572 open-ended QA pairs from 578 videos across 4 scenarios and 10 capabilities. We build it with an Automated Generative Pipeline backed by rigorous human verification, and evaluate models using a realistic Online Inference Pipeline and LLM-as-a-Judge evaluation for open-ended responses. Experiments reveal a temporal asymmetry in LLM-judged scores (0-100): models perform well on Instant and Backward tasks (Gemini 3 Pro exceeds 80), but drop sharply on Forward tasks (16.40), largely due to early responses before the required visual and audio cues appear. This highlights a fundamental limitation: current MLLMs struggle to decide when to speak, not just what to say. Code and datasets used in this work will be made publicly accessible at https://github.com/Lucky-Lance/PhoStream.
GLEAM: Learning to Match and Explain in Cross-View Geo-Localization
Sep 09, 2025Cross-View Geo-Localization (CVGL) focuses on identifying correspondences between images captured from distinct perspectives of the same geographical location. However, existing CVGL approaches are typically restricted to a single view or modality, and their direct visual matching strategy lacks interpretability: they merely predict whether two images correspond, without explaining the rationale behind the match. In this paper, we present GLEAM-C, a foundational CVGL model that unifies multiple views and modalities-including UAV imagery, street maps, panoramic views, and ground photographs-by aligning them exclusively with satellite imagery. Our framework enhances training efficiency through optimized implementation while achieving accuracy comparable to prior modality-specific CVGL models through a two-phase training strategy. Moreover, to address the lack of interpretability in traditional CVGL methods, we leverage the reasoning capabilities of multimodal large language models (MLLMs) to propose a new task, GLEAM-X, which combines cross-view correspondence prediction with explainable reasoning. To support this task, we construct a bilingual benchmark using GPT-4o and Doubao-1.5-Thinking-Vision-Pro to generate training and testing data. The test set is further refined through detailed human revision, enabling systematic evaluation of explainable cross-view reasoning and advancing transparency and scalability in geo-localization. Together, GLEAM-C and GLEAM-X form a comprehensive CVGL pipeline that integrates multi-modal, multi-view alignment with interpretable correspondence analysis, unifying accurate cross-view matching with explainable reasoning and advancing Geo-Localization by enabling models to better Explain And Match. Code and datasets used in this work will be made publicly accessible at https://github.com/Lucky-Lance/GLEAM.
Adaptive Markup Language Generation for Contextually-Grounded Visual Document Understanding
May 08, 2025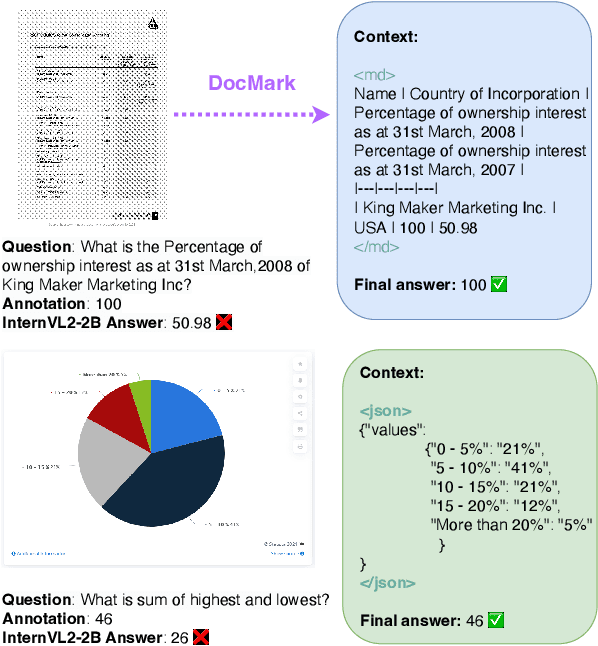
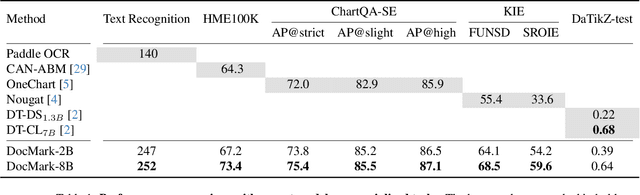
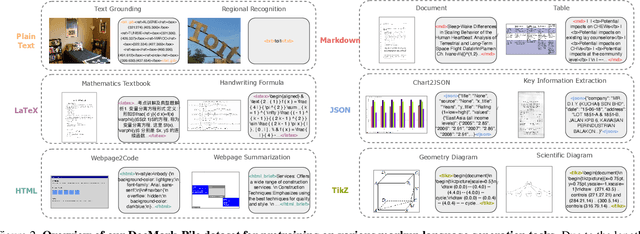
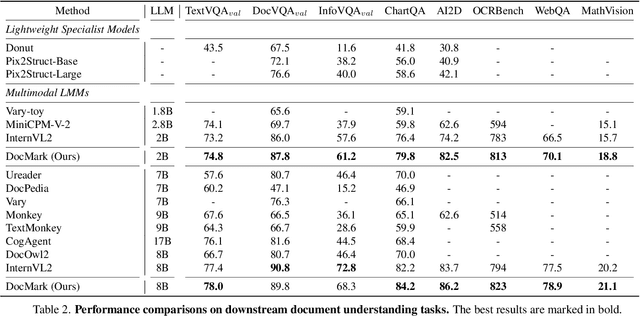
Visual Document Understanding has become essential with the increase of text-rich visual content. This field poses significant challenges due to the need for effective integration of visual perception and textual comprehension, particularly across diverse document types with complex layouts. Moreover, existing fine-tuning datasets for this domain often fall short in providing the detailed contextual information for robust understanding, leading to hallucinations and limited comprehension of spatial relationships among visual elements. To address these challenges, we propose an innovative pipeline that utilizes adaptive generation of markup languages, such as Markdown, JSON, HTML, and TiKZ, to build highly structured document representations and deliver contextually-grounded responses. We introduce two fine-grained structured datasets: DocMark-Pile, comprising approximately 3.8M pretraining data pairs for document parsing, and DocMark-Instruct, featuring 624k fine-tuning data annotations for grounded instruction following. Extensive experiments demonstrate that our proposed model significantly outperforms existing state-of-theart MLLMs across a range of visual document understanding benchmarks, facilitating advanced reasoning and comprehension capabilities in complex visual scenarios. Our code and models are released at https://github. com/Euphoria16/DocMark.
SmartBench: Is Your LLM Truly a Good Chinese Smartphone Assistant?
Mar 08, 2025Large Language Models (LLMs) have become integral to daily life, especially advancing as intelligent assistants through on-device deployment on smartphones. However, existing LLM evaluation benchmarks predominantly focus on objective tasks like mathematics and coding in English, which do not necessarily reflect the practical use cases of on-device LLMs in real-world mobile scenarios, especially for Chinese users. To address these gaps, we introduce SmartBench, the first benchmark designed to evaluate the capabilities of on-device LLMs in Chinese mobile contexts. We analyze functionalities provided by representative smartphone manufacturers and divide them into five categories: text summarization, text Q\&A, information extraction, content creation, and notification management, further detailed into 20 specific tasks. For each task, we construct high-quality datasets comprising 50 to 200 question-answer pairs that reflect everyday mobile interactions, and we develop automated evaluation criteria tailored for these tasks. We conduct comprehensive evaluations of on-device LLMs and MLLMs using SmartBench and also assess their performance after quantized deployment on real smartphone NPUs. Our contributions provide a standardized framework for evaluating on-device LLMs in Chinese, promoting further development and optimization in this critical area. Code and data will be available at https://github.com/Lucky-Lance/SmartBench.
GenieBlue: Integrating both Linguistic and Multimodal Capabilities for Large Language Models on Mobile Devices
Mar 08, 2025Recent advancements in Multimodal Large Language Models (MLLMs) have enabled their deployment on mobile devices. However, challenges persist in maintaining strong language capabilities and ensuring hardware compatibility, both of which are crucial for user experience and practical deployment efficiency. In our deployment process, we observe that existing MLLMs often face performance degradation on pure language tasks, and the current NPU platforms on smartphones do not support the MoE architecture, which is commonly used to preserve pure language capabilities during multimodal training. To address these issues, we systematically analyze methods to maintain pure language capabilities during the training of MLLMs, focusing on both training data and model architecture aspects. Based on these analyses, we propose GenieBlue, an efficient MLLM structural design that integrates both linguistic and multimodal capabilities for LLMs on mobile devices. GenieBlue freezes the original LLM parameters during MLLM training to maintain pure language capabilities. It acquires multimodal capabilities by duplicating specific transformer blocks for full fine-tuning and integrating lightweight LoRA modules. This approach preserves language capabilities while achieving comparable multimodal performance through extensive training. Deployed on smartphone NPUs, GenieBlue demonstrates efficiency and practicality for applications on mobile devices.
Rethinking Video Tokenization: A Conditioned Diffusion-based Approach
Mar 05, 2025
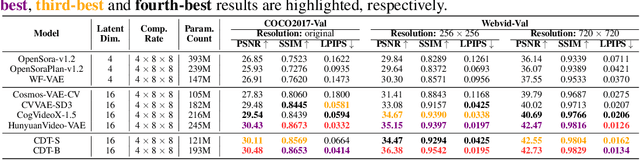
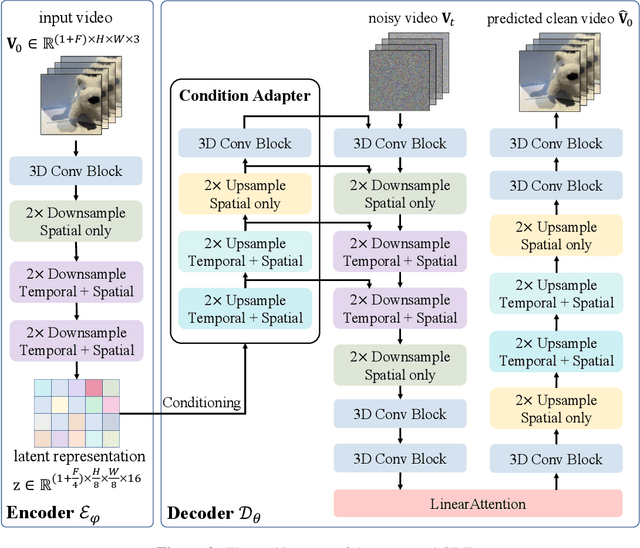
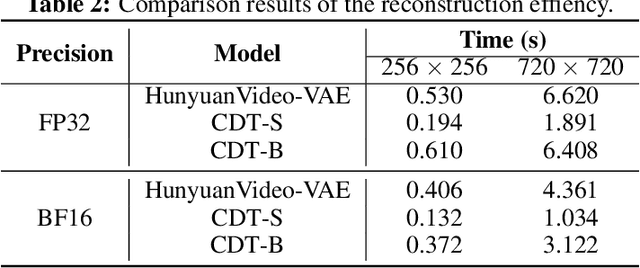
Video tokenizers, which transform videos into compact latent representations, are key to video generation. Existing video tokenizers are based on the VAE architecture and follow a paradigm where an encoder compresses videos into compact latents, and a deterministic decoder reconstructs the original videos from these latents. In this paper, we propose a novel \underline{\textbf{C}}onditioned \underline{\textbf{D}}iffusion-based video \underline{\textbf{T}}okenizer entitled \textbf{\ourmethod}, which departs from previous methods by replacing the deterministic decoder with a 3D causal diffusion model. The reverse diffusion generative process of the decoder is conditioned on the latent representations derived via the encoder. With a feature caching and sampling acceleration, the framework efficiently reconstructs high-fidelity videos of arbitrary lengths. Results show that {\ourmethod} achieves state-of-the-art performance in video reconstruction tasks using just a single-step sampling. Even a smaller version of {\ourmethod} still achieves reconstruction results on par with the top two baselines. Furthermore, the latent video generation model trained using {\ourmethod} also shows superior performance.
PointOBB-v3: Expanding Performance Boundaries of Single Point-Supervised Oriented Object Detection
Jan 23, 2025



With the growing demand for oriented object detection (OOD), recent studies on point-supervised OOD have attracted significant interest. In this paper, we propose PointOBB-v3, a stronger single point-supervised OOD framework. Compared to existing methods, it generates pseudo rotated boxes without additional priors and incorporates support for the end-to-end paradigm. PointOBB-v3 functions by integrating three unique image views: the original view, a resized view, and a rotated/flipped (rot/flp) view. Based on the views, a scale augmentation module and an angle acquisition module are constructed. In the first module, a Scale-Sensitive Consistency (SSC) loss and a Scale-Sensitive Feature Fusion (SSFF) module are introduced to improve the model's ability to estimate object scale. To achieve precise angle predictions, the second module employs symmetry-based self-supervised learning. Additionally, we introduce an end-to-end version that eliminates the pseudo-label generation process by integrating a detector branch and introduces an Instance-Aware Weighting (IAW) strategy to focus on high-quality predictions. We conducted extensive experiments on the DIOR-R, DOTA-v1.0/v1.5/v2.0, FAIR1M, STAR, and RSAR datasets. Across all these datasets, our method achieves an average improvement in accuracy of 3.56% in comparison to previous state-of-the-art methods. The code will be available at https://github.com/ZpyWHU/PointOBB-v3.
CodeV: Issue Resolving with Visual Data
Dec 23, 2024
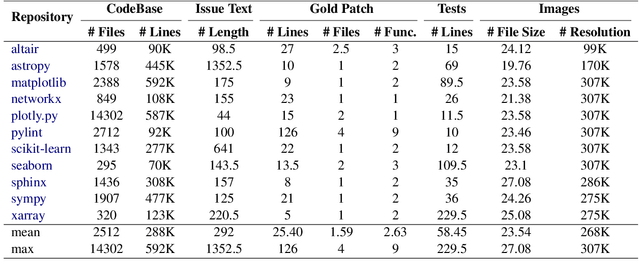


Large Language Models (LLMs) have advanced rapidly in recent years, with their applications in software engineering expanding to more complex repository-level tasks. GitHub issue resolving is a key challenge among these tasks. While recent approaches have made progress on this task, they focus on textual data within issues, neglecting visual data. However, this visual data is crucial for resolving issues as it conveys additional knowledge that text alone cannot. We propose CodeV, the first approach to leveraging visual data to enhance the issue-resolving capabilities of LLMs. CodeV resolves each issue by following a two-phase process: data processing and patch generation. To evaluate CodeV, we construct a benchmark for visual issue resolving, namely Visual SWE-bench. Through extensive experiments, we demonstrate the effectiveness of CodeV, as well as provide valuable insights into leveraging visual data to resolve GitHub issues.
BlueLM-V-3B: Algorithm and System Co-Design for Multimodal Large Language Models on Mobile Devices
Nov 16, 2024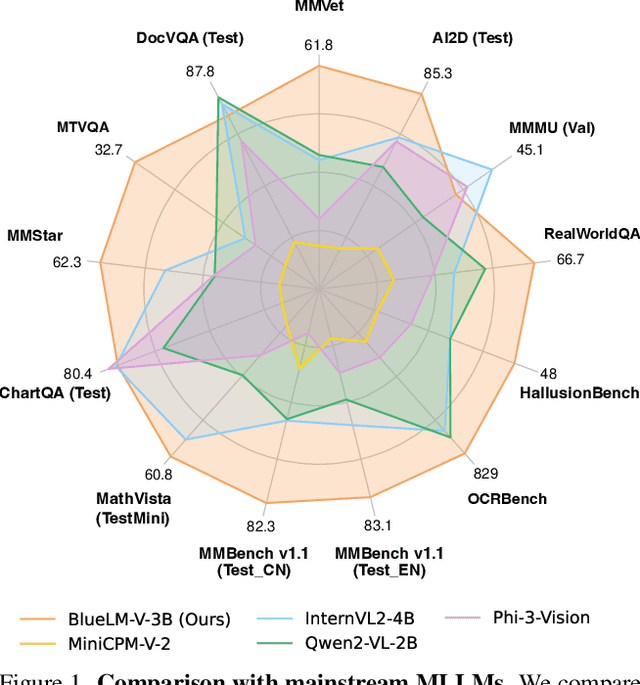
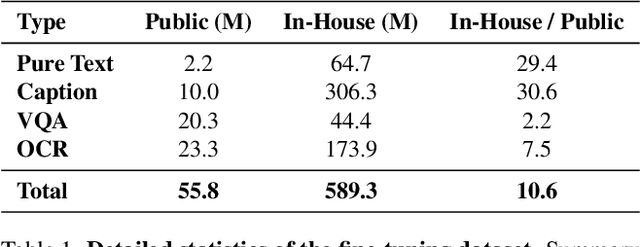
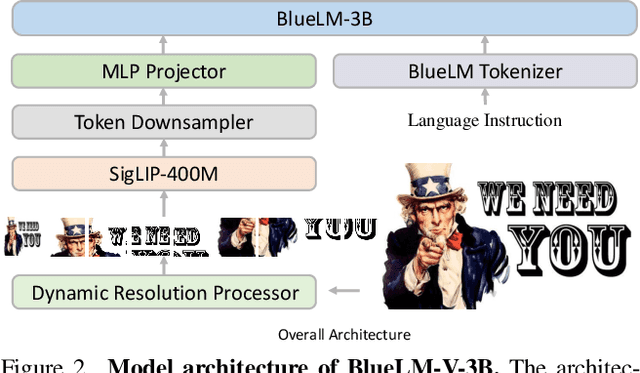

The emergence and growing popularity of multimodal large language models (MLLMs) have significant potential to enhance various aspects of daily life, from improving communication to facilitating learning and problem-solving. Mobile phones, as essential daily companions, represent the most effective and accessible deployment platform for MLLMs, enabling seamless integration into everyday tasks. However, deploying MLLMs on mobile phones presents challenges due to limitations in memory size and computational capability, making it difficult to achieve smooth and real-time processing without extensive optimization. In this paper, we present BlueLM-V-3B, an algorithm and system co-design approach specifically tailored for the efficient deployment of MLLMs on mobile platforms. To be specific, we redesign the dynamic resolution scheme adopted by mainstream MLLMs and implement system optimization for hardware-aware deployment to optimize model inference on mobile phones. BlueLM-V-3B boasts the following key highlights: (1) Small Size: BlueLM-V-3B features a language model with 2.7B parameters and a vision encoder with 400M parameters. (2) Fast Speed: BlueLM-V-3B achieves a generation speed of 24.4 token/s on the MediaTek Dimensity 9300 processor with 4-bit LLM weight quantization. (3) Strong Performance: BlueLM-V-3B has attained the highest average score of 66.1 on the OpenCompass benchmark among models with $\leq$ 4B parameters and surpassed a series of models with much larger parameter sizes (e.g., MiniCPM-V-2.6, InternVL2-8B).
ThinK: Thinner Key Cache by Query-Driven Pruning
Jul 30, 2024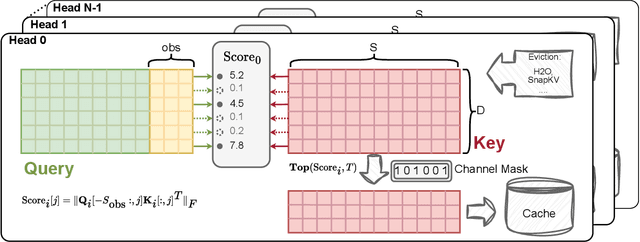
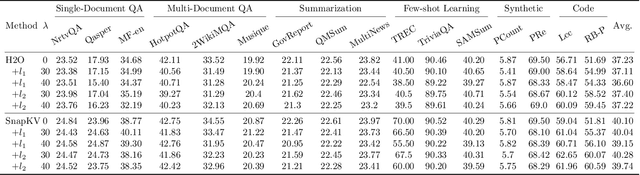
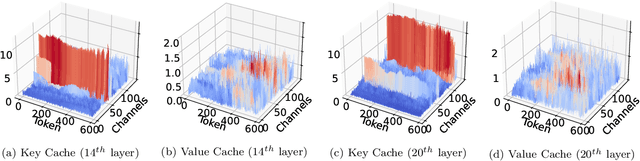
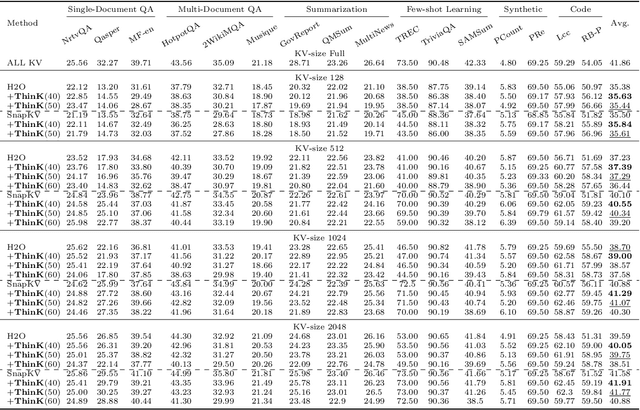
Large Language Models (LLMs) have revolutionized the field of natural language processing, achieving unprecedented performance across a variety of applications by leveraging increased model sizes and sequence lengths. However, the associated rise in computational and memory costs poses significant challenges, particularly in managing long sequences due to the quadratic complexity of the transformer attention mechanism. This paper focuses on the long-context scenario, addressing the inefficiencies in KV cache memory consumption during inference. Unlike existing approaches that optimize the memory based on the sequence lengths, we uncover that the channel dimension of the KV cache exhibits significant redundancy, characterized by unbalanced magnitude distribution and low-rank structure in attention weights. Based on these observations, we propose ThinK, a novel query-dependent KV cache pruning method designed to minimize attention weight loss while selectively pruning the least significant channels. Our approach not only maintains or enhances model accuracy but also achieves a reduction in memory costs by over 20% compared with vanilla KV cache eviction methods. Extensive evaluations on the LLaMA3 and Mistral models across various long-sequence datasets confirm the efficacy of ThinK, setting a new precedent for efficient LLM deployment without compromising performance. We also outline the potential of extending our method to value cache pruning, demonstrating ThinK's versatility and broad applicability in reducing both memory and computational overheads.