 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinK: Thinner Key Cache by Query-Driven Pruning
Paper and Code
Jul 30, 2024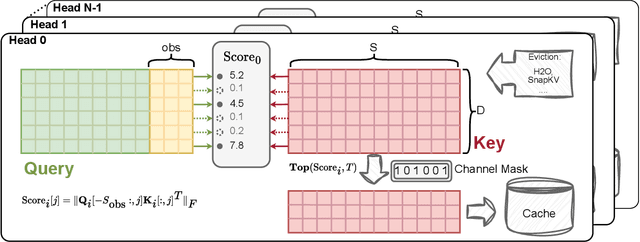
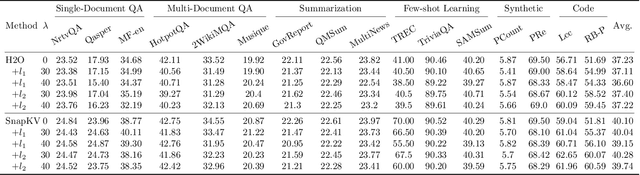
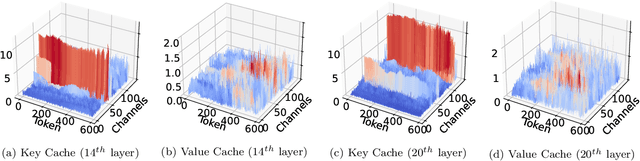
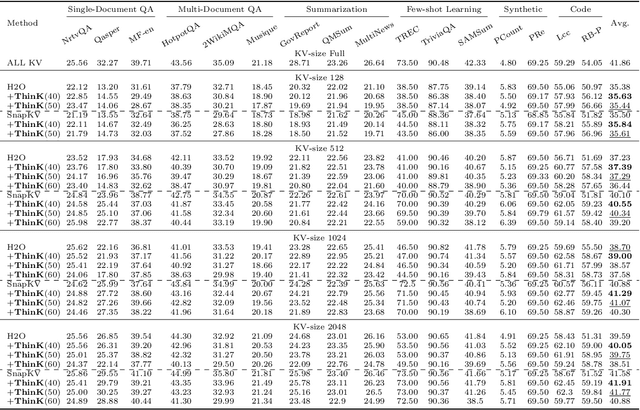
Large Language Models (LLMs) have revolutionized the field of natural language processing, achieving unprecedented performance across a variety of applications by leveraging increased model sizes and sequence lengths. However, the associated rise in computational and memory costs poses significant challenges, particularly in managing long sequences due to the quadratic complexity of the transformer attention mechanism. This paper focuses on the long-context scenario, addressing the inefficiencies in KV cache memory consumption during inference. Unlike existing approaches that optimize the memory based on the sequence lengths, we uncover that the channel dimension of the KV cache exhibits significant redundancy, characterized by unbalanced magnitude distribution and low-rank structure in attention weights. Based on these observations, we propose ThinK, a novel query-dependent KV cache pruning method designed to minimize attention weight loss while selectively pruning the least significant channels. Our approach not only maintains or enhances model accuracy but also achieves a reduction in memory costs by over 20% compared with vanilla KV cache eviction methods. Extensive evaluations on the LLaMA3 and Mistral models across various long-sequence datasets confirm the efficacy of ThinK, setting a new precedent for efficient LLM deployment without compromising performance. We also outline the potential of extending our method to value cache pruning, demonstrating ThinK's versatility and broad applicability in reducing both memory and computational overheads.