 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinK: Thinner Key Cache by Query-Driven Pruning
Jul 30, 2024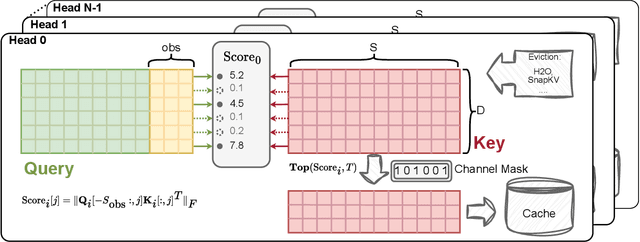
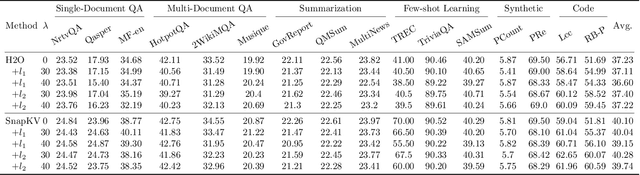
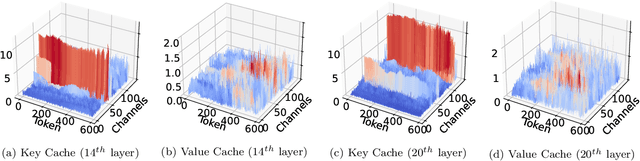
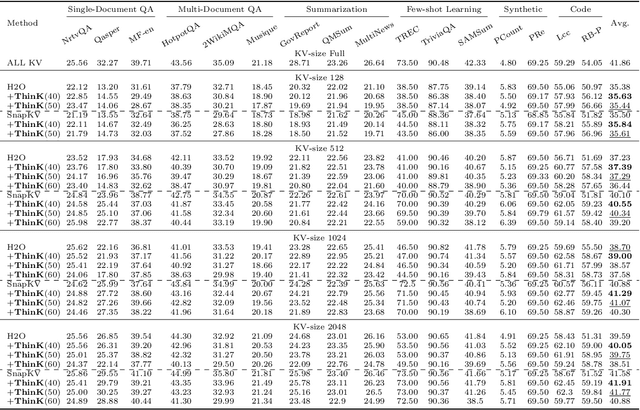
Large Language Models (LLMs) have revolutionized the field of natural language processing, achieving unprecedented performance across a variety of applications by leveraging increased model sizes and sequence lengths. However, the associated rise in computational and memory costs poses significant challenges, particularly in managing long sequences due to the quadratic complexity of the transformer attention mechanism. This paper focuses on the long-context scenario, addressing the inefficiencies in KV cache memory consumption during inference. Unlike existing approaches that optimize the memory based on the sequence lengths, we uncover that the channel dimension of the KV cache exhibits significant redundancy, characterized by unbalanced magnitude distribution and low-rank structure in attention weights. Based on these observations, we propose ThinK, a novel query-dependent KV cache pruning method designed to minimize attention weight loss while selectively pruning the least significant channels. Our approach not only maintains or enhances model accuracy but also achieves a reduction in memory costs by over 20% compared with vanilla KV cache eviction methods. Extensive evaluations on the LLaMA3 and Mistral models across various long-sequence datasets confirm the efficacy of ThinK, setting a new precedent for efficient LLM deployment without compromising performance. We also outline the potential of extending our method to value cache pruning, demonstrating ThinK's versatility and broad applicability in reducing both memory and computational overheads.
ReFT: Reasoning with Reinforced Fine-Tuning
Jan 17, 2024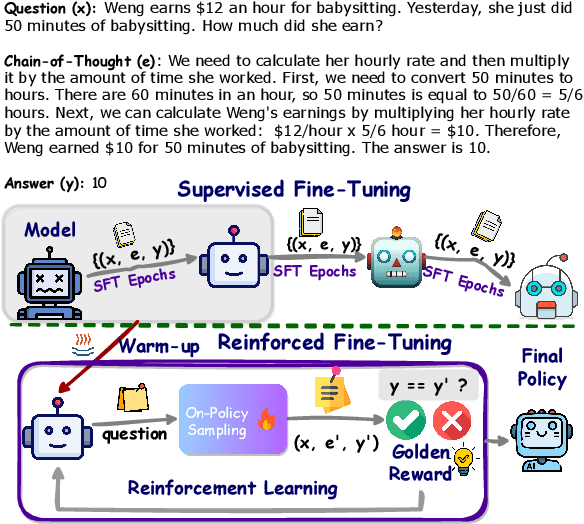
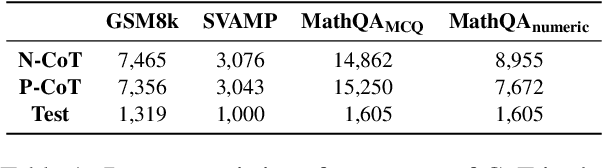
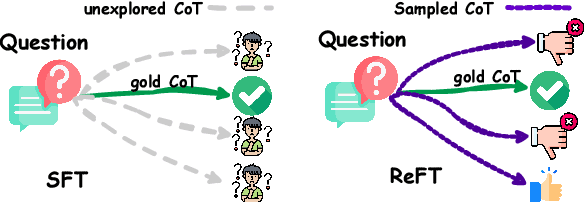
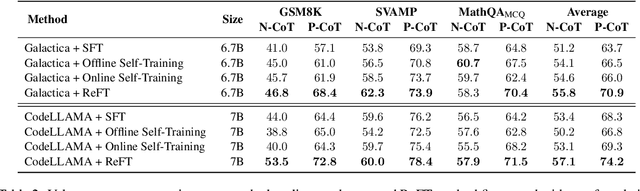
One way to enhance the reasoning capability of Large Language Models (LLMs) is to conduct Supervised Fine-Tuning (SFT) using Chain-of-Thought (CoT) annotations. This approach does not show sufficiently strong generalization ability, however, because the training only relies on the given CoT data. In math problem-solving, for example, there is usually only one annotated reasoning path for each question in the training data. Intuitively, it would be better for the algorithm to learn from multiple annotated reasoning paths given a question. To address this issue, we propose a simple yet effective approach called Reinforced Fine-Tuning (ReFT) to enhance the generalizability of learning LLMs for reasoning, with math problem-solving as an example. ReFT first warmups the model with SFT, and then employs on-line reinforcement learning, specifically the PPO algorithm in this paper, to further fine-tune the model, where an abundance of reasoning paths are automatically sampled given the question and the rewards are naturally derived from the ground-truth answers. Extensive experiments on GSM8K, MathQA, and SVAMP datasets show that ReFT significantly outperforms SFT, and the performance can be potentially further boosted by combining inference-time strategies such as majority voting and re-ranking. Note that ReFT obtains the improvement by learning from the same training questions as SFT, without relying on extra or augmented training questions. This indicates a superior generalization ability for ReFT.
Design of Chain-of-Thought in Math Problem Solving
Sep 30, 2023Chain-of-Thought (CoT) plays a crucial role in reasoning for math problem solving. We conduct a comprehensive examination of methods for designing CoT, comparing conventional natural language CoT with various program CoTs, including the self-describing program, the comment-describing program, and the non-describing program. Furthermore, we investigate the impact of programming language on program CoTs, comparing Python and Wolfram Language. Through extensive experiments on GSM8K, MATHQA, and SVAMP, we find that program CoTs often have superior effectiveness in math problem solving. Notably, the best performing combination with 30B parameters beats GPT-3.5-turbo by a significant margin. The results show that self-describing program offers greater diversity and thus can generally achieve higher performance. We also find that Python is a better choice of language than Wolfram for program CoTs. The experimental results provide a valuable guideline for future CoT designs that take into account both programming language and coding style for further advancements. Our datasets and code are publicly available.
Leveraging Training Data in Few-Shot Prompting for Numerical Reasoning
Jun 09, 2023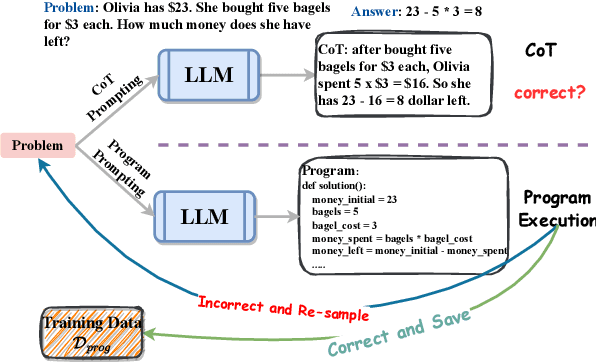
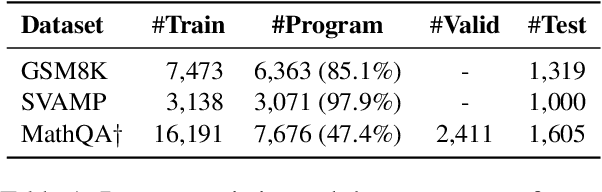

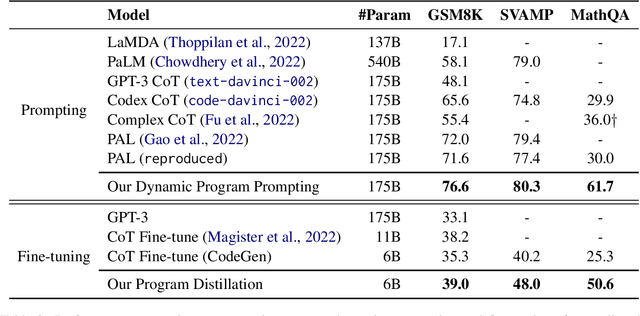
Chain-of-thought (CoT) prompting with large language models has proven effective in numerous natural language processing tasks, but designing prompts that generalize well to diverse problem types can be challenging, especially in the context of math word problem (MWP) solving. Additionally, it is common to have a large amount of training data that have a better diversity coverage but CoT annotations are not available, which limits the use of supervised learning techniques. To address these issues, we investigate two approaches to leverage the training data in a few-shot prompting scenario: dynamic program prompting and program distillation. Our approach is largely inspired by Gao et al., (2022), where they proposed to replace the CoT with the programs as the intermediate reasoning step. Such a prompting strategy allows us to accurately verify the answer correctness through program execution in MWP solving. Our dynamic program prompting involves annotating the training data by sampling correct programs from a large language model, while program distillation involves adapting a smaller model to the program-annotated training data. Our experiments on three standard MWP datasets demonstrate the effectiveness of these approaches, yielding significant improvements over previous baselines for prompting and fine-tuning. Our results suggest that leveraging a large amount of training data can improve the generalization ability of prompts and boost the performance of fine-tuned small models in MWP solving.
Sequence-to-Sequence Pre-training with Unified Modality Masking for Visual Document Understanding
May 16, 2023



This paper presents GenDoc, a general sequence-to-sequence document understanding model pre-trained with unified masking across three modalities: text, image, and layout. The proposed model utilizes an encoder-decoder architecture, which allows for increased adaptability to a wide range of downstream tasks with diverse output formats, in contrast to the encoder-only models commonly employed in document understanding. In addition to the traditional text infilling task used in previous encoder-decoder models, our pre-training extends to include tasks of masked image token prediction and masked layout prediction. We also design modality-specific instruction and adopt both disentangled attention and the mixture-of-modality-experts strategy to effectively capture the information leveraged by each modality. Evaluation of the proposed model through extensive experiments on several downstream tasks in document understanding demonstrates its ability to achieve superior or competitive performance compared to state-of-the-art approaches. Our analysis further suggests that GenDoc is more robust than the encoder-only models in scenarios where the OCR quality is imperfect.
Learning to Reason Deductively: Math Word Problem Solving as Complex Relation Extraction
Mar 19, 2022
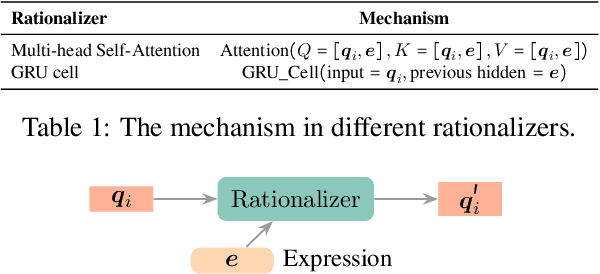
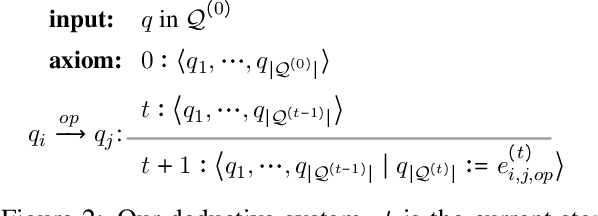
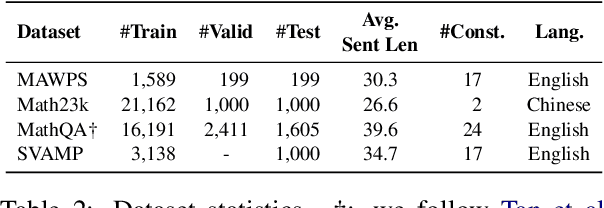
Solving math word problems requires deductive reasoning over the quantities in the text. Various recent research efforts mostly relied on sequence-to-sequence or sequence-to-tree models to generate mathematical expressions without explicitly performing relational reasoning between quantities in the given context. While empirically effective, such approaches typically do not provide explanations for the generated expressions. In this work, we view the task as a complex relation extraction problem, proposing a novel approach that presents explainable deductive reasoning steps to iteratively construct target expressions, where each step involves a primitive operation over two quantities defining their relation. Through extensive experiments on four benchmark datasets, we show that the proposed model significantly outperforms existing strong baselines. We further demonstrate that the deductive procedure not only presents more explainable steps but also enables us to make more accurate predictions on questions that require more complex reasoning.
To be Closer: Learning to Link up Aspects with Opinions
Sep 17, 2021


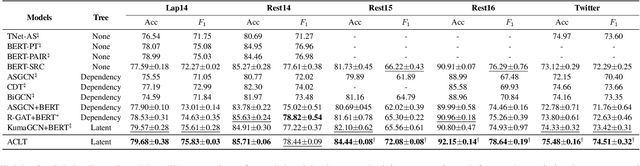
Dependency parse trees are helpful for discovering the opinion words in aspect-based sentiment analysis (ABSA). However, the trees obtained from off-the-shelf dependency parsers are static, and could be sub-optimal in ABSA. This is because the syntactic trees are not designed for capturing the interactions between opinion words and aspect words. In this work, we aim to shorten the distance between aspects and corresponding opinion words by learning an aspect-centric tree structure. The aspect and opinion words are expected to be closer along such tree structure compared to the standard dependency parse tree. The learning process allows the tree structure to adaptively correlate the aspect and opinion words, enabling us to better identify the polarity in the ABSA task. We conduct experiments on five aspect-based sentiment datasets, and the proposed model significantly outperforms recent strong baselines. Furthermore, our thorough analysis demonstrates the average distance between aspect and opinion words are shortened by at least 19% on the standard SemEval Restaurant14 dataset.
Better Feature Integration for Named Entity Recognition
Apr 12, 2021



It has been shown that named entity recognition (NER) could benefit from incorporating the long-distance structured information captured by dependency trees. We believe this is because both types of features - the contextual information captured by the linear sequences and the structured information captured by the dependency trees may complement each other. However, existing approaches largely focused on stacking the LSTM and graph neural networks such as graph convolutional networks (GCNs) for building improved NER models, where the exact interaction mechanism between the two types of features is not very clear, and the performance gain does not appear to be significant. In this work, we propose a simple and robust solution to incorporate both types of features with our Synergized-LSTM (Syn-LSTM), which clearly captures how the two types of features interact. We conduct extensive experiments on several standard datasets across four languages. The results demonstrate that the proposed model achieves better performance than previous approaches while requiring fewer parameters. Our further analysis demonstrates that our model can capture longer dependencies compared with strong baselines.
Knowledge Graph Empowered Entity Description Generation
Apr 30, 2020
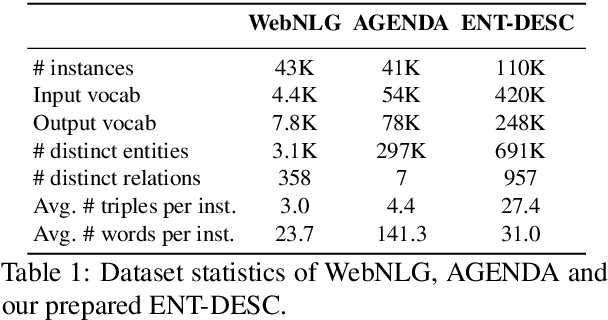

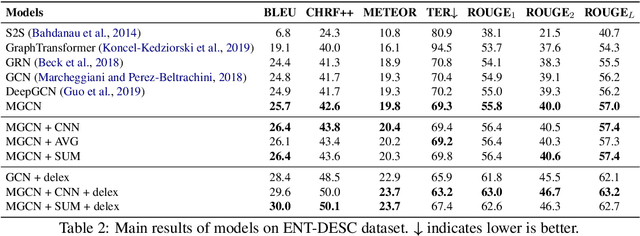
Existing works on KG-to-text generation take as input a few RDF triples or key-value pairs conveying the knowledge of some entities to generate a natural language description. Existing datasets, such as WikiBIO, WebNLG, and E2E, basically have a good alignment between an input triple/pair set and its output text. However in practice, the input knowledge could be more than enough, because the output description may only want to cover the most significant knowledge. In this paper, we introduce a large-scale and challenging dataset to facilitate the study of such practical scenario in KG-to-text. Our dataset involves exploring large knowledge graphs (KG) to retrieve abundant knowledge of various types of main entities, which makes the current graph-to-sequence models severely suffered from the problems of information loss and parameter explosion while generating the description text. We address these challenges by proposing a multi-graph structure that is able to represent the original graph information more comprehensively. Furthermore, we also incorporate aggregation methods that learn to ensemble the rich graph information. Extensive experiments demonstrate the effectiveness of our model architecture.
Dependency-Guided LSTM-CRF for Named Entity Recognition
Sep 23, 2019



Dependency tree structures capture long-distance and syntactic relationships between words in a sentence. The syntactic relations (e.g., nominal subject, object) can potentially infer the existence of certain named entities. In addition, the performance of a named entity recognizer could benefit from the long-distance dependencies between the words in dependency trees. In this work, we propose a simple yet effective dependency-guided LSTM-CRF model to encode the complete dependency trees and capture the above properties for the task of named entity recognition (NER). The data statistics show strong correlations between the entity types and dependency relations. We conduct extensive experiments on several standard datasets and demonstrate the effectiveness of the proposed model in improving NER and achieving state-of-the-art performance. Our analysis reveals that the significant improvements mainly result from the dependency relations and long-distance interactions provided by dependency trees.