 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeed-Prover 1.5: Mastering Undergraduate-Level Theorem Proving via Learning from Experience
Dec 19, 2025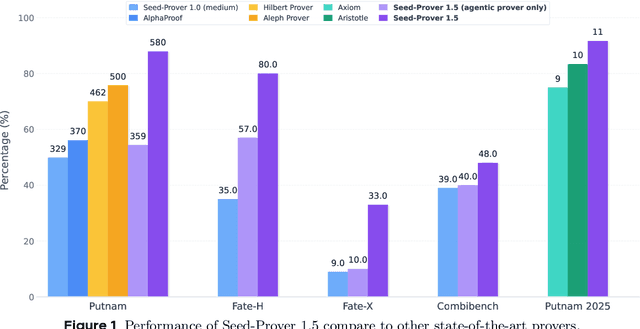

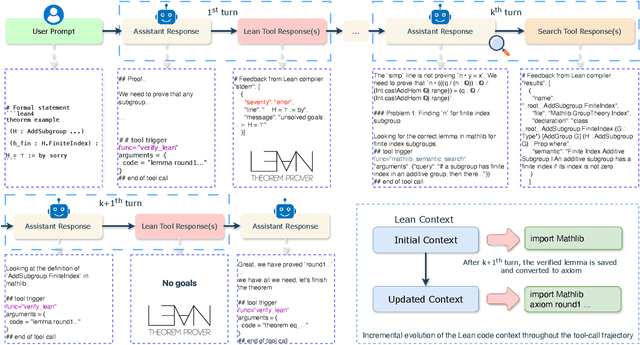

Large language models have recently made significant progress to generate rigorous mathematical proofs. In contrast, utilizing LLMs for theorem proving in formal languages (such as Lean) remains challenging and computationally expensive, particularly when addressing problems at the undergraduate level and beyond. In this work, we present \textbf{Seed-Prover 1.5}, a formal theorem-proving model trained via large-scale agentic reinforcement learning, alongside an efficient test-time scaling (TTS) workflow. Through extensive interactions with Lean and other tools, the model continuously accumulates experience during the RL process, substantially enhancing the capability and efficiency of formal theorem proving. Furthermore, leveraging recent advancements in natural language proving, our TTS workflow efficiently bridges the gap between natural and formal languages. Compared to state-of-the-art methods, Seed-Prover 1.5 achieves superior performance with a smaller compute budget. It solves \textbf{88\% of PutnamBench} (undergraduate-level), \textbf{80\% of Fate-H} (graduate-level), and \textbf{33\% of Fate-X} (PhD-level) problems. Notably, using our system, we solved \textbf{11 out of 12 problems} from Putnam 2025 within 9 hours. Our findings suggest that scaling learning from experience, driven by high-quality formal feedback, holds immense potential for the future of formal mathematical reasoning.
Seed-Prover: Deep and Broad Reasoning for Automated Theorem Proving
Aug 01, 2025LLMs have demonstrated strong mathematical reasoning abilities by leveraging reinforcement learning with long chain-of-thought, yet they continue to struggle with theorem proving due to the lack of clear supervision signals when solely using natural language. Dedicated domain-specific languages like Lean provide clear supervision via formal verification of proofs, enabling effective training through reinforcement learning. In this work, we propose \textbf{Seed-Prover}, a lemma-style whole-proof reasoning model. Seed-Prover can iteratively refine its proof based on Lean feedback, proved lemmas, and self-summarization. To solve IMO-level contest problems, we design three test-time inference strategies that enable both deep and broad reasoning. Seed-Prover proves $78.1\%$ of formalized past IMO problems, saturates MiniF2F, and achieves over 50\% on PutnamBench, outperforming the previous state-of-the-art by a large margin. To address the lack of geometry support in Lean, we introduce a geometry reasoning engine \textbf{Seed-Geometry}, which outperforms previous formal geometry engines. We use these two systems to participate in IMO 2025 and fully prove 5 out of 6 problems. This work represents a significant advancement in automated mathematical reasoning, demonstrating the effectiveness of formal verification with long chain-of-thought reasoning.
APE-Bench I: Towards File-level Automated Proof Engineering of Formal Math Libraries
Apr 27, 2025Recent progress in large language models (LLMs) has shown promise in formal theorem proving, yet existing benchmarks remain limited to isolated, static proof tasks, failing to capture the iterative, engineering-intensive workflows of real-world formal mathematics libraries. Motivated by analogous advances in software engineering, we introduce the paradigm of Automated Proof Engineering (APE), which aims to automate proof engineering tasks such as feature addition, proof refactoring, and bug fixing using LLMs. To facilitate research in this direction, we present APE-Bench I, the first realistic benchmark built from real-world commit histories of Mathlib4, featuring diverse file-level tasks described in natural language and verified via a hybrid approach combining the Lean compiler and LLM-as-a-Judge. We further develop Eleanstic, a scalable parallel verification infrastructure optimized for proof checking across multiple versions of Mathlib. Empirical results on state-of-the-art LLMs demonstrate strong performance on localized edits but substantial degradation on handling complex proof engineering. This work lays the foundation for developing agentic workflows in proof engineering, with future benchmarks targeting multi-file coordination, project-scale verification, and autonomous agents capable of planning, editing, and repairing formal libraries.
ReFT: Reasoning with Reinforced Fine-Tuning
Jan 17, 2024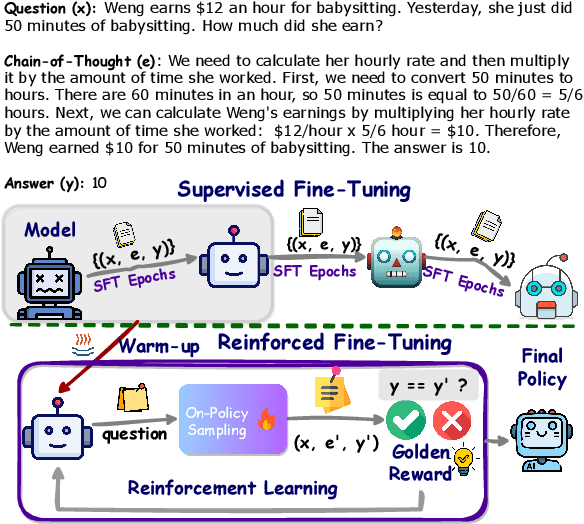
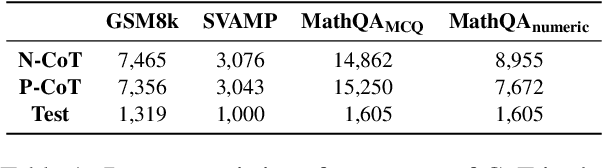
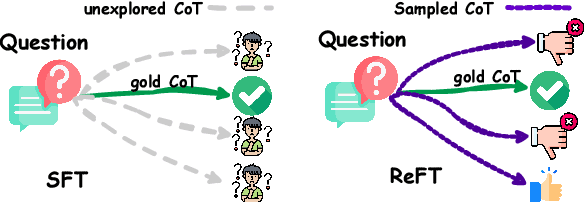
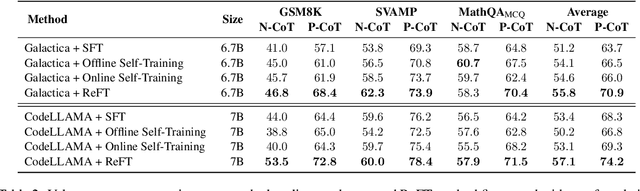
One way to enhance the reasoning capability of Large Language Models (LLMs) is to conduct Supervised Fine-Tuning (SFT) using Chain-of-Thought (CoT) annotations. This approach does not show sufficiently strong generalization ability, however, because the training only relies on the given CoT data. In math problem-solving, for example, there is usually only one annotated reasoning path for each question in the training data. Intuitively, it would be better for the algorithm to learn from multiple annotated reasoning paths given a question. To address this issue, we propose a simple yet effective approach called Reinforced Fine-Tuning (ReFT) to enhance the generalizability of learning LLMs for reasoning, with math problem-solving as an example. ReFT first warmups the model with SFT, and then employs on-line reinforcement learning, specifically the PPO algorithm in this paper, to further fine-tune the model, where an abundance of reasoning paths are automatically sampled given the question and the rewards are naturally derived from the ground-truth answers. Extensive experiments on GSM8K, MathQA, and SVAMP datasets show that ReFT significantly outperforms SFT, and the performance can be potentially further boosted by combining inference-time strategies such as majority voting and re-ranking. Note that ReFT obtains the improvement by learning from the same training questions as SFT, without relying on extra or augmented training questions. This indicates a superior generalization ability for ReFT.
Design of Chain-of-Thought in Math Problem Solving
Sep 30, 2023Chain-of-Thought (CoT) plays a crucial role in reasoning for math problem solving. We conduct a comprehensive examination of methods for designing CoT, comparing conventional natural language CoT with various program CoTs, including the self-describing program, the comment-describing program, and the non-describing program. Furthermore, we investigate the impact of programming language on program CoTs, comparing Python and Wolfram Language. Through extensive experiments on GSM8K, MATHQA, and SVAMP, we find that program CoTs often have superior effectiveness in math problem solving. Notably, the best performing combination with 30B parameters beats GPT-3.5-turbo by a significant margin. The results show that self-describing program offers greater diversity and thus can generally achieve higher performance. We also find that Python is a better choice of language than Wolfram for program CoTs. The experimental results provide a valuable guideline for future CoT designs that take into account both programming language and coding style for further advancements. Our datasets and code are publicly available.
Sequence-to-Sequence Pre-training with Unified Modality Masking for Visual Document Understanding
May 16, 2023



This paper presents GenDoc, a general sequence-to-sequence document understanding model pre-trained with unified masking across three modalities: text, image, and layout. The proposed model utilizes an encoder-decoder architecture, which allows for increased adaptability to a wide range of downstream tasks with diverse output formats, in contrast to the encoder-only models commonly employed in document understanding. In addition to the traditional text infilling task used in previous encoder-decoder models, our pre-training extends to include tasks of masked image token prediction and masked layout prediction. We also design modality-specific instruction and adopt both disentangled attention and the mixture-of-modality-experts strategy to effectively capture the information leveraged by each modality. Evaluation of the proposed model through extensive experiments on several downstream tasks in document understanding demonstrates its ability to achieve superior or competitive performance compared to state-of-the-art approaches. Our analysis further suggests that GenDoc is more robust than the encoder-only models in scenarios where the OCR quality is imperfect.