 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetermined by User Needs: A Salient Object Detection Rationale Beyond Conventional Visual Stimuli
Apr 04, 2026Existing \textbf{s}alient \textbf{o}bject \textbf{d}etection (SOD) methods adopt a \textbf{passive} visual stimulus-based rationale--objects with the strongest visual stimuli are perceived as the user's primary focus (i.e., salient objects). They ignore the decisive role of users' \textbf{proactive needs} in segmenting salient objects--if a user has a need before seeing an image, the user's salient objects align with their needs, e.g., if a user's need is ``white apple'', when this user sees an image, the user's primary focus is on the ``white apple'' or ``the most white apple-like'' objects in the image. Such an oversight not only \textbf{fails to satisfy users}, but also \textbf{limits the development of downstream tasks}. For instance, in salient object ranking tasks, focusing solely on visual stimuli-based salient objects is insufficient for conducting an analysis of fine-grained relationships between users' viewing order (usually determined by user's needs) and scenes, which may result in wrong ranking results. Clearly, it is essential to detect salient objects based on user needs. Thus, we advocate a \textbf{User} \textbf{S}alient \textbf{O}bject \textbf{D}etection (UserSOD) task, which focuses on \textbf{detecting salient objects align with users' proactive needs when user have needs}. The main challenge for this new task is the lack of datasets for model training and testing.
CriticLean: Critic-Guided Reinforcement Learning for Mathematical Formalization
Jul 08, 2025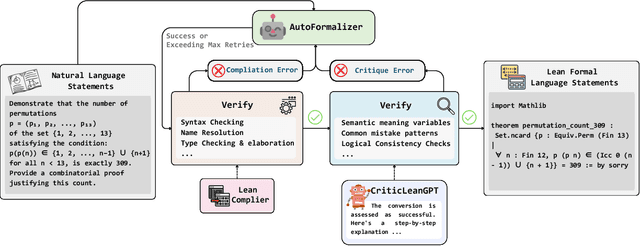

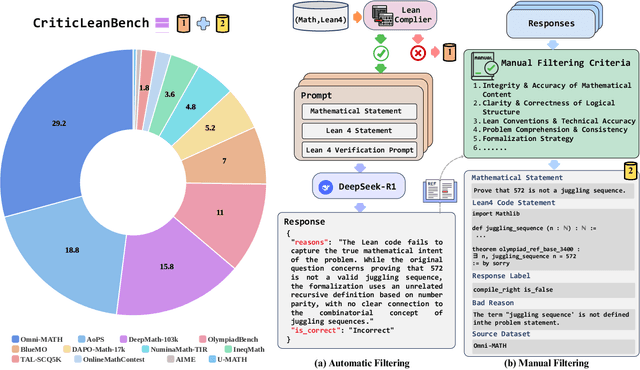
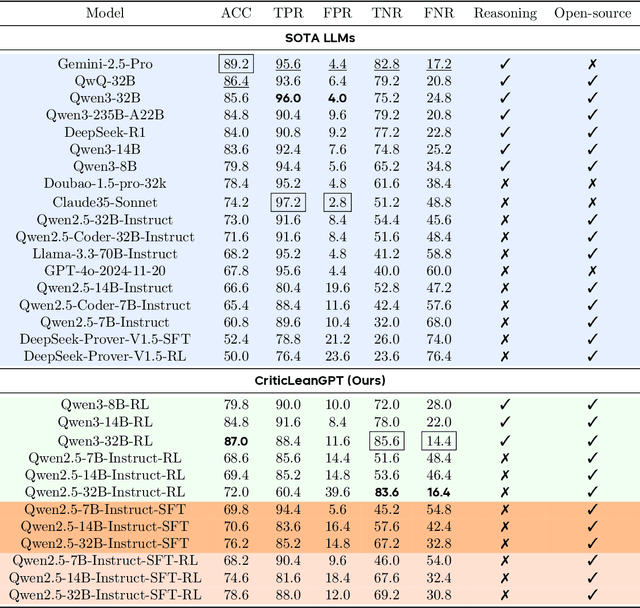
Translating natural language mathematical statements into formal, executable code is a fundamental challenge in automated theorem proving. While prior work has focused on generation and compilation success, little attention has been paid to the critic phase-the evaluation of whether generated formalizations truly capture the semantic intent of the original problem. In this paper, we introduce CriticLean, a novel critic-guided reinforcement learning framework that elevates the role of the critic from a passive validator to an active learning component. Specifically, first, we propose the CriticLeanGPT, trained via supervised fine-tuning and reinforcement learning, to rigorously assess the semantic fidelity of Lean 4 formalizations. Then, we introduce CriticLeanBench, a benchmark designed to measure models' ability to distinguish semantically correct from incorrect formalizations, and demonstrate that our trained CriticLeanGPT models can significantly outperform strong open- and closed-source baselines. Building on the CriticLean framework, we construct FineLeanCorpus, a dataset comprising over 285K problems that exhibits rich domain diversity, broad difficulty coverage, and high correctness based on human evaluation. Overall, our findings highlight that optimizing the critic phase is essential for producing reliable formalizations, and we hope our CriticLean will provide valuable insights for future advances in formal mathematical reasoning.
APE-Bench I: Towards File-level Automated Proof Engineering of Formal Math Libraries
Apr 27, 2025Recent progress in large language models (LLMs) has shown promise in formal theorem proving, yet existing benchmarks remain limited to isolated, static proof tasks, failing to capture the iterative, engineering-intensive workflows of real-world formal mathematics libraries. Motivated by analogous advances in software engineering, we introduce the paradigm of Automated Proof Engineering (APE), which aims to automate proof engineering tasks such as feature addition, proof refactoring, and bug fixing using LLMs. To facilitate research in this direction, we present APE-Bench I, the first realistic benchmark built from real-world commit histories of Mathlib4, featuring diverse file-level tasks described in natural language and verified via a hybrid approach combining the Lean compiler and LLM-as-a-Judge. We further develop Eleanstic, a scalable parallel verification infrastructure optimized for proof checking across multiple versions of Mathlib. Empirical results on state-of-the-art LLMs demonstrate strong performance on localized edits but substantial degradation on handling complex proof engineering. This work lays the foundation for developing agentic workflows in proof engineering, with future benchmarks targeting multi-file coordination, project-scale verification, and autonomous agents capable of planning, editing, and repairing formal libraries.
Unveiling Context-Related Anomalies: Knowledge Graph Empowered Decoupling of Scene and Action for Human-Related Video Anomaly Detection
Sep 05, 2024Detecting anomalies in human-related videos is crucial for surveillance applications. Current methods primarily include appearance-based and action-based techniques. Appearance-based methods rely on low-level visual features such as color, texture, and shape. They learn a large number of pixel patterns and features related to known scenes during training, making them effective in detecting anomalies within these familiar contexts. However, when encountering new or significantly changed scenes, i.e., unknown scenes, they often fail because existing SOTA methods do not effectively capture the relationship between actions and their surrounding scenes, resulting in low generalization. In contrast, action-based methods focus on detecting anomalies in human actions but are usually less informative because they tend to overlook the relationship between actions and their scenes, leading to incorrect detection. For instance, the normal event of running on the beach and the abnormal event of running on the street might both be considered normal due to the lack of scene information. In short, current methods struggle to integrate low-level visual and high-level action features, leading to poor anomaly detection in varied and complex scenes. To address this challenge, we propose a novel decoupling-based architecture for human-related video anomaly detection (DecoAD). DecoAD significantly improves the integration of visual and action features through the decoupling and interweaving of scenes and actions, thereby enabling a more intuitive and accurate understanding of complex behaviors and scenes. DecoAD supports fully supervised, weakly supervised, and unsupervised settings.
Automatic Sleep Stage Classification with Cross-modal Self-supervised Features from Deep Brain Signals
Feb 07, 2023The detection of human sleep stages is widely used in the diagnosis and intervention of neurological and psychiatric diseases. Some patients with deep brain stimulator implanted could have their neural activities recorded from the deep brain. Sleep stage classification based on deep brain recording has great potential to provide more precise treatment for patients. The accuracy and generalizability of existing sleep stage classifiers based on local field potentials are still limited. We proposed an applicable cross-modal transfer learning method for sleep stage classification with implanted devices. This end-to-end deep learning model contained cross-modal self-supervised feature representation, self-attention, and classification framework. We tested the model with deep brain recording data from 12 patients with Parkinson's disease. The best total accuracy reached 83.2% for sleep stage classification. Results showed speech self-supervised features catch the conversion pattern of sleep stages effectively. We provide a new method on transfer learning from acoustic signals to local field potentials. This method supports an effective solution for the insufficient scale of clinical data. This sleep stage classification model could be adapted to chronic and continuous monitor sleep for Parkinson's patients in daily life, and potentially utilized for more precise treatment in deep brain-machine interfaces, such as closed-loop deep brain stimulation.
Parkinsonian Chinese Speech Analysis towards Automatic Classification of Parkinson's Disease
May 31, 2021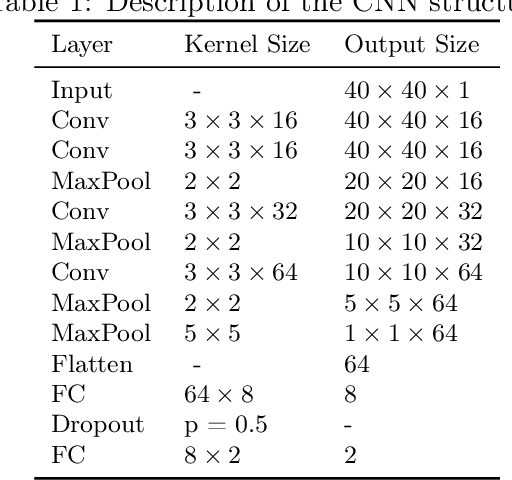
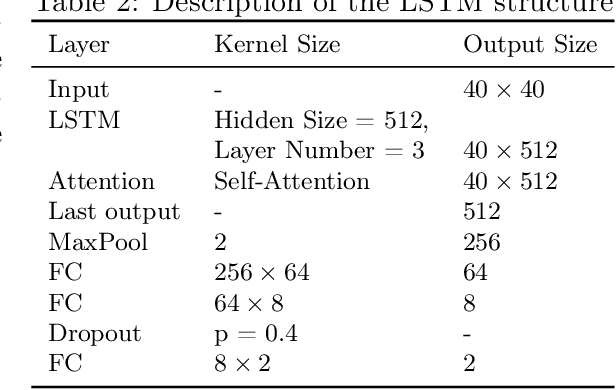

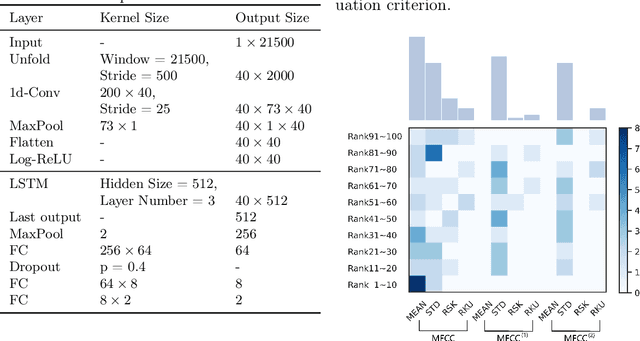
Speech disorders often occur at the early stage of Parkinson's disease (PD). The speech impairments could be indicators of the disorder for early diagnosis, while motor symptoms are not obvious. In this study, we constructed a new speech corpus of Mandarin Chinese and addressed classification of patients with PD. We implemented classical machine learning methods with ranking algorithms for feature selection, convolutional and recurrent deep networks, and an end to end system. Our classification accuracy significantly surpassed state-of-the-art studies. The result suggests that free talk has stronger classification power than standard speech tasks, which could help the design of future speech tasks for efficient early diagnosis of the disease. Based on existing classification methods and our natural speech study, the automatic detection of PD from daily conversation could be accessible to the majority of the clinical population.
Deepfakes for Medical Video De-Identification: Privacy Protection and Diagnostic Information Preservation
Feb 07, 2020
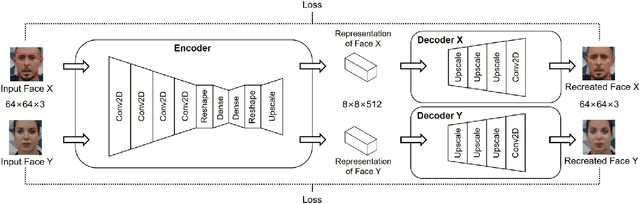
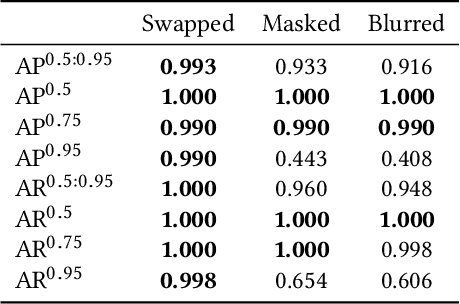

Data sharing for medical research has been difficult as open-sourcing clinical data may violate patient privacy. Traditional methods for face de-identification wipe out facial information entirely, making it impossible to analyze facial behavior. Recent advancements on whole-body keypoints detection also rely on facial input to estimate body keypoints. Both facial and body keypoints are critical in some medical diagnoses, and keypoints invariability after de-identification is of great importance. Here, we propose a solution using deepfake technology, the face swapping technique. While this swapping method has been criticized for invading privacy and portraiture right, it could conversely protect privacy in medical video: patients' faces could be swapped to a proper target face and become unrecognizable. However, it remained an open question that to what extent the swapping de-identification method could affect the automatic detection of body keypoints. In this study, we apply deepfake technology to Parkinson's disease examination videos to de-identify subjects, and quantitatively show that: face-swapping as a de-identification approach is reliable, and it keeps the keypoints almost invariant, significantly better than traditional methods. This study proposes a pipeline for video de-identification and keypoint preservation, clearing up some ethical restrictions for medical data sharing. This work could make open-source high quality medical video datasets more feasible and promote future medical research that benefits our society.