 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREAD-Net: Clarifying Emotional Ambiguity via Adaptive Feature Recalibration for Audio-Visual Depression Detection
Jan 21, 2026Depression is a severe global mental health issue that impairs daily functioning and overall quality of life. Although recent audio-visual approaches have improved automatic depression detection, methods that ignore emotional cues often fail to capture subtle depressive signals hidden within emotional expressions. Conversely, those incorporating emotions frequently confuse transient emotional expressions with stable depressive symptoms in feature representations, a phenomenon termed \emph{Emotional Ambiguity}, thereby leading to detection errors. To address this critical issue, we propose READ-Net, the first audio-visual depression detection framework explicitly designed to resolve Emotional Ambiguity through Adaptive Feature Recalibration (AFR). The core insight of AFR is to dynamically adjust the weights of emotional features to enhance depression-related signals. Rather than merely overlooking or naively combining emotional information, READ-Net innovatively identifies and preserves depressive-relevant cues within emotional features, while adaptively filtering out irrelevant emotional noise. This recalibration strategy significantly clarifies feature representations, and effectively mitigates the persistent challenge of emotional interference. Additionally, READ-Net can be easily integrated into existing frameworks for improved performance. Extensive evaluations on three publicly available datasets show that READ-Net outperforms state-of-the-art methods, with average gains of 4.55\% in accuracy and 1.26\% in F1-score, demonstrating its robustness to emotional disturbances and improving audio-visual depression detection.
Soft Conflict-Resolution Decision Transformer for Offline Multi-Task Reinforcement Learning
Nov 17, 2025Multi-task reinforcement learning (MTRL) seeks to learn a unified policy for diverse tasks, but often suffers from gradient conflicts across tasks. Existing masking-based methods attempt to mitigate such conflicts by assigning task-specific parameter masks. However, our empirical study shows that coarse-grained binary masks have the problem of over-suppressing key conflicting parameters, hindering knowledge sharing across tasks. Moreover, different tasks exhibit varying conflict levels, yet existing methods use a one-size-fits-all fixed sparsity strategy to keep training stability and performance, which proves inadequate. These limitations hinder the model's generalization and learning efficiency. To address these issues, we propose SoCo-DT, a Soft Conflict-resolution method based by parameter importance. By leveraging Fisher information, mask values are dynamically adjusted to retain important parameters while suppressing conflicting ones. In addition, we introduce a dynamic sparsity adjustment strategy based on the Interquartile Range (IQR), which constructs task-specific thresholding schemes using the distribution of conflict and harmony scores during training. To enable adaptive sparsity evolution throughout training, we further incorporate an asymmetric cosine annealing schedule to continuously update the threshold. Experimental results on the Meta-World benchmark show that SoCo-DT outperforms the state-of-the-art method by 7.6% on MT50 and by 10.5% on the suboptimal dataset, demonstrating its effectiveness in mitigating gradient conflicts and improving overall multi-task performance.
Unveiling Context-Related Anomalies: Knowledge Graph Empowered Decoupling of Scene and Action for Human-Related Video Anomaly Detection
Sep 05, 2024Detecting anomalies in human-related videos is crucial for surveillance applications. Current methods primarily include appearance-based and action-based techniques. Appearance-based methods rely on low-level visual features such as color, texture, and shape. They learn a large number of pixel patterns and features related to known scenes during training, making them effective in detecting anomalies within these familiar contexts. However, when encountering new or significantly changed scenes, i.e., unknown scenes, they often fail because existing SOTA methods do not effectively capture the relationship between actions and their surrounding scenes, resulting in low generalization. In contrast, action-based methods focus on detecting anomalies in human actions but are usually less informative because they tend to overlook the relationship between actions and their scenes, leading to incorrect detection. For instance, the normal event of running on the beach and the abnormal event of running on the street might both be considered normal due to the lack of scene information. In short, current methods struggle to integrate low-level visual and high-level action features, leading to poor anomaly detection in varied and complex scenes. To address this challenge, we propose a novel decoupling-based architecture for human-related video anomaly detection (DecoAD). DecoAD significantly improves the integration of visual and action features through the decoupling and interweaving of scenes and actions, thereby enabling a more intuitive and accurate understanding of complex behaviors and scenes. DecoAD supports fully supervised, weakly supervised, and unsupervised settings.
An Efficient Style Virtual Try on Network for Clothing Business Industry
May 30, 2021
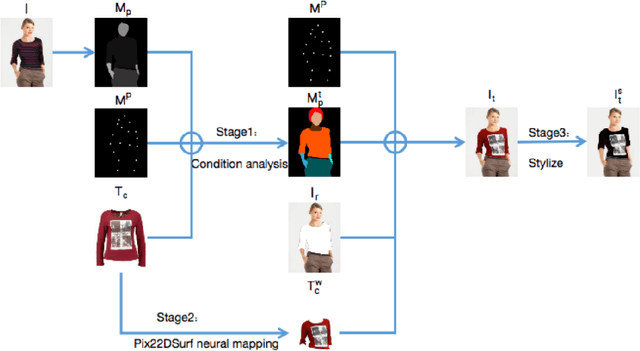

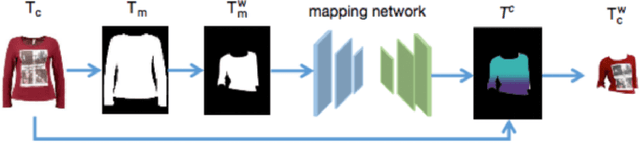
With the increasing development of garment manufacturing industry, the method of combining neural network with industry to reduce product redundancy has been paid more and more attention.In order to reduce garment redundancy and achieve personalized customization, more researchers have appeared in the field of virtual trying on.They try to transfer the target clothing to the reference figure, and then stylize the clothes to meet user's requirements for fashion.But the biggest problem of virtual try on is that the shape and motion blocking distort the clothes, causing the patterns and texture on the clothes to be impossible to restore. This paper proposed a new stylized virtual try on network, which can not only retain the authenticity of clothing texture and pattern, but also obtain the undifferentiated stylized try on. The network is divided into three sub-networks, the first is the user image, the front of the target clothing image, the semantic segmentation image and the posture heat map to generate a more detailed human parsing map. Second, UV position map and dense correspondence are used to map patterns and textures to the deformed silhouettes in real time, so that they can be retained in real time, and the rationality of spatial structure can be guaranteed on the basis of improving the authenticity of images. Third,Stylize and adjust the generated virtual try on image. Through the most subtle changes, users can choose the texture, color and style of clothing to improve the user's experience.
IUP: An Intelligent Utility Prediction Scheme for Solid-State Fermentation in 5G IoT
Mar 28, 2021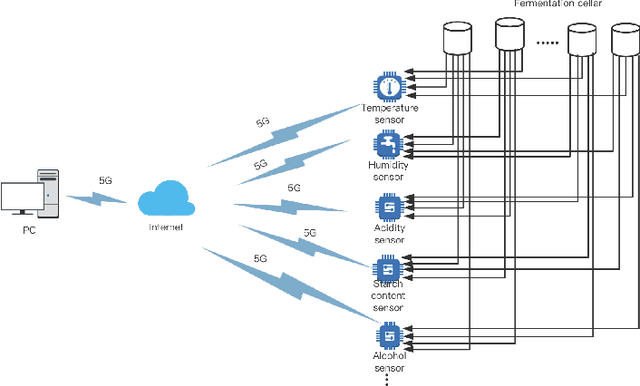
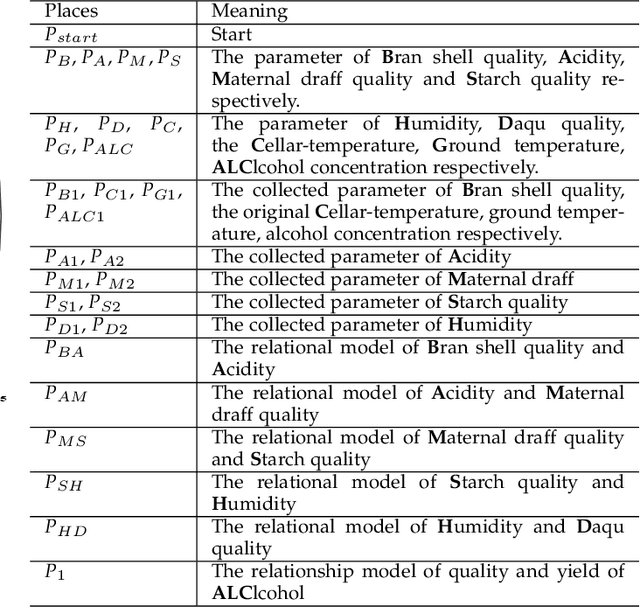
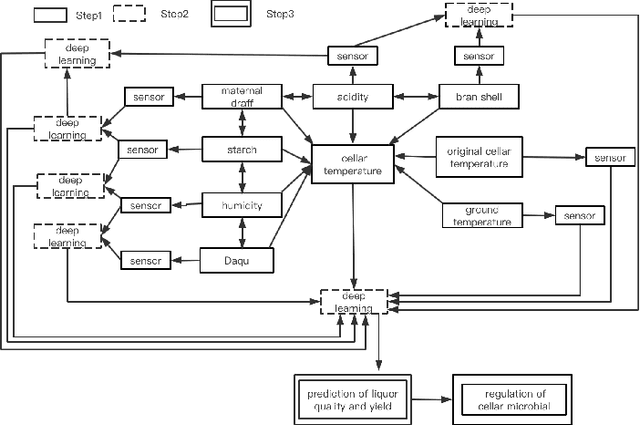
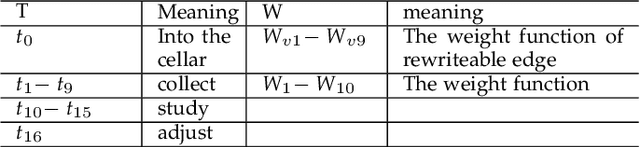
At present, SOILD-STATE Fermentation (SSF) is mainly controlled by artificial experience, and the product quality and yield are not stable. Accurately predicting the quality and yield of SSF is of great significance for improving human food security and supply. In this paper, we propose an Intelligent Utility Prediction (IUP) scheme for SSF in 5G Industrial Internet of Things (IoT), including parameter collection and utility prediction of SSF process. This IUP scheme is based on the environmental perception and intelligent learning algorithms of the 5G Industrial IoT. We build a workflow model based on rewritable petri net to verify the correctness of the system model function and process. In addition, we design a utility prediction model for SSF based on the Generative Adversarial Networks (GAN) and Fully Connected Neural Network (FCNN). We design a GAN with constraint of mean square error (MSE-GAN) to solve the problem of few-shot learning of SSF, and then combine with the FCNN to realize the utility prediction (usually use the alcohol) of SSF. Based on the production of liquor in laboratory, the experiments show that the proposed method is more accurate than the other prediction methods in the utility prediction of SSF, and provide the basis for the numerical analysis of the proportion of preconfigured raw materials and the appropriate setting of cellar temperature.
Automatic Detection of Cardiac Chambers Using an Attention-based YOLOv4 Framework from Four-chamber View of Fetal Echocardiography
Dec 13, 2020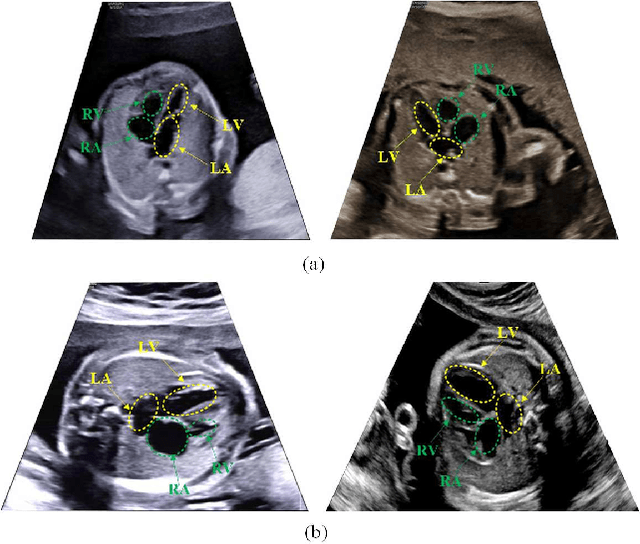
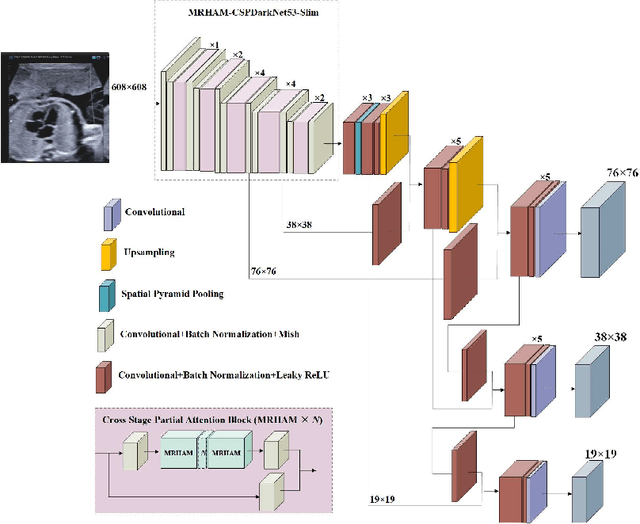
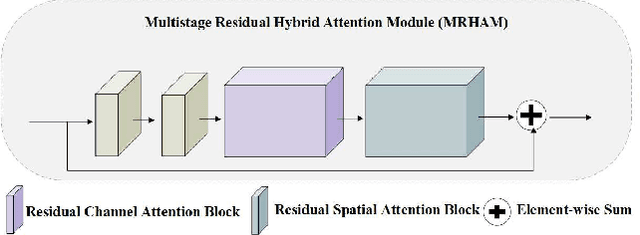
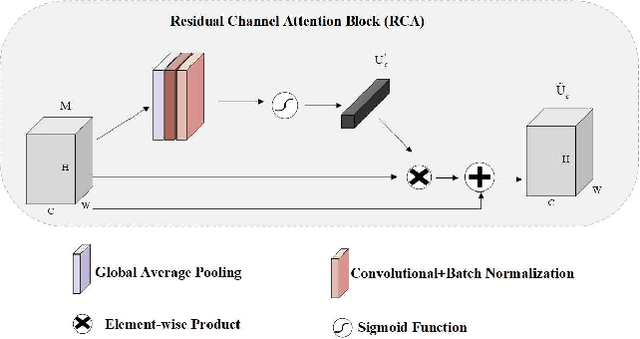
Echocardiography is a powerful prenatal examination tool for early diagnosis of fetal congenital heart diseases (CHDs). The four-chamber (FC) view is a crucial and easily accessible ultrasound (US) image among echocardiography images. Automatic analysis of FC views contributes significantly to the early diagnosis of CHDs. The first step to automatically analyze fetal FC views is locating the fetal four crucial chambers of heart in a US image. However, it is a greatly challenging task due to several key factors, such as numerous speckles in US images, the fetal cardiac chambers with small size and unfixed positions, and category indistinction caused by the similarity of cardiac chambers. These factors hinder the process of capturing robust and discriminative features, hence destroying fetal cardiac anatomical chambers precise localization. Therefore, we first propose a multistage residual hybrid attention module (MRHAM) to improve the feature learning. Then, we present an improved YOLOv4 detection model, namely MRHAM-YOLOv4-Slim. Specially, the residual identity mapping is replaced with the MRHAM in the backbone of MRHAM-YOLOv4-Slim, accurately locating the four important chambers in fetal FC views. Extensive experiments demonstrate that our proposed method outperforms current state-of-the-art, including the precision of 0.919, the recall of 0.971, the F1 score of 0.944, the mAP of 0.953, and the frames per second (FPS) of 43.