 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajSurv: Learning Continuous Latent Trajectories from Electronic Health Records for Trustworthy Survival Prediction
Aug 01, 2025Trustworthy survival prediction is essential for clinical decision making. Longitudinal electronic health records (EHRs) provide a uniquely powerful opportunity for the prediction. However, it is challenging to accurately model the continuous clinical progression of patients underlying the irregularly sampled clinical features and to transparently link the progression to survival outcomes. To address these challenges, we develop TrajSurv, a model that learns continuous latent trajectories from longitudinal EHR data for trustworthy survival prediction. TrajSurv employs a neural controlled differential equation (NCDE) to extract continuous-time latent states from the irregularly sampled data, forming continuous latent trajectories. To ensure the latent trajectories reflect the clinical progression, TrajSurv aligns the latent state space with patient state space through a time-aware contrastive learning approach. To transparently link clinical progression to the survival outcome, TrajSurv uses latent trajectories in a two-step divide-and-conquer interpretation process. First, it explains how the changes in clinical features translate into the latent trajectory's evolution using a learned vector field. Second, it clusters these latent trajectories to identify key clinical progression patterns associated with different survival outcomes. Evaluations on two real-world medical datasets, MIMIC-III and eICU, show TrajSurv's competitive accuracy and superior transparency over existing deep learning methods.
MDD-LLM: Towards Accuracy Large Language Models for Major Depressive Disorder Diagnosis
Apr 28, 2025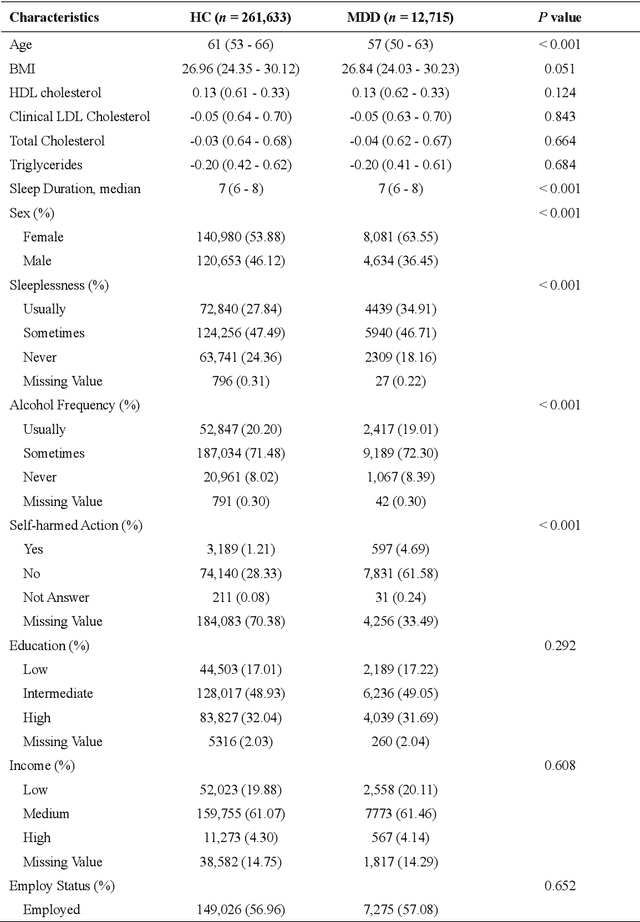
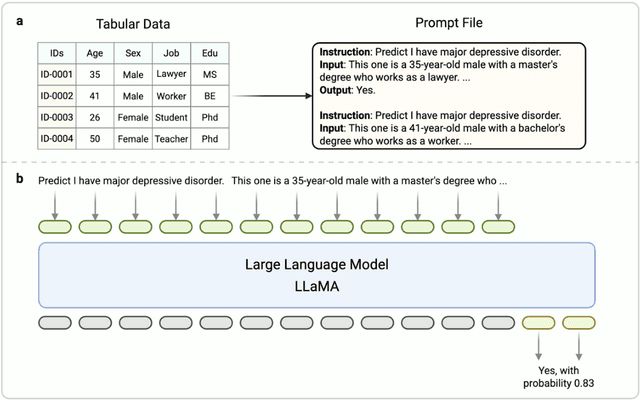

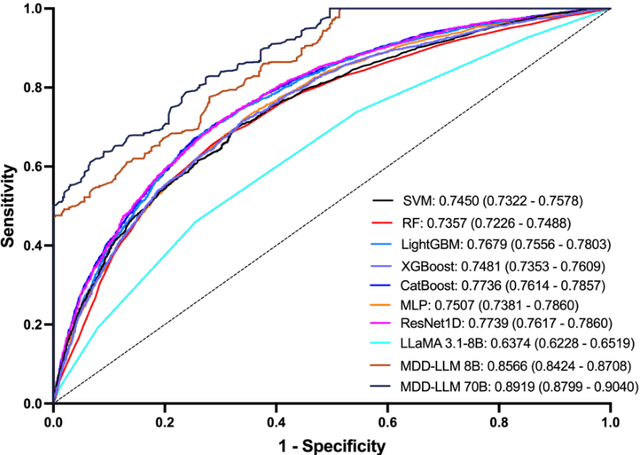
Major depressive disorder (MDD) impacts more than 300 million people worldwide, highlighting a significant public health issue. However, the uneven distribution of medical resources and the complexity of diagnostic methods have resulted in inadequate attention to this disorder in numerous countries and regions. This paper introduces a high-performance MDD diagnosis tool named MDD-LLM, an AI-driven framework that utilizes fine-tuned large language models (LLMs) and extensive real-world samples to tackle challenges in MDD diagnosis. Therefore, we select 274,348 individual information from the UK Biobank cohort to train and evaluate the proposed method. Specifically, we select 274,348 individual records from the UK Biobank cohort and design a tabular data transformation method to create a large corpus for training and evaluating the proposed approach. To illustrate the advantages of MDD-LLM, we perform comprehensive experiments and provide several comparative analyses against existing model-based solutions across multiple evaluation metrics. Experimental results show that MDD-LLM (70B) achieves an accuracy of 0.8378 and an AUC of 0.8919 (95% CI: 0.8799 - 0.9040), significantly outperforming existing machine learning and deep learning frameworks for MDD diagnosis. Given the limited exploration of LLMs in MDD diagnosis, we examine numerous factors that may influence the performance of our proposed method, such as tabular data transformation techniques and different fine-tuning strategies.
Can ChatGPT assist visually impaired people with micro-navigation?
Jul 31, 2024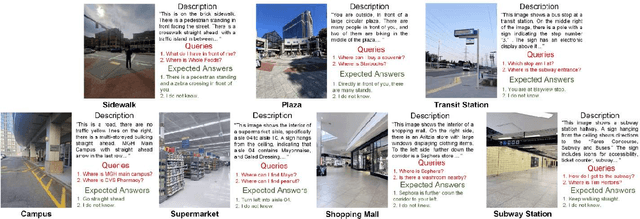



Objective: Micro-navigation poses challenges for blind and visually impaired individuals. They often need to ask for sighted assistance. We explored the feasibility of utilizing ChatGPT as a virtual assistant to provide navigation directions. Methods: We created a test set of outdoor and indoor micro-navigation scenarios consisting of 113 scene images and their human-generated text descriptions. A total of 412 way-finding queries and their expected responses were compiled based on the scenarios. Not all queries are answerable based on the information available in the scene image. "I do not know"response was expected for unanswerable queries, which served as negative cases. High level orientation responses were expected, and step-by-step guidance was not required. ChatGPT 4o was evaluated based on sensitivity (SEN) and specificity (SPE) under different conditions. Results: The default ChatGPT 4o, with scene images as inputs, resulted in SEN and SPE values of 64.8% and 75.9%, respectively. Instruction on how to respond to unanswerable questions did not improve SEN substantially but SPE increased by around 14 percentage points. SEN and SPE both improved substantially, by about 17 and 16 percentage points on average respectively, when human written descriptions of the scenes were provided as input instead of images. Providing further prompt instructions to the assistants when the input was text description did not substantially change the SEN and SPE values. Conclusion: Current native ChatGPT 4o is still unable to provide correct micro-navigation guidance in some cases, probably because its scene understanding is not optimized for navigation purposes. If multi-modal chatbots could interpret scenes with a level of clarity comparable to humans, and also guided by appropriate prompts, they may have the potential to provide assistance to visually impaired for micro-navigation.
Forecasting Daily COVID-19 Related Calls in VA Health Care System: Predictive Model Development
Nov 30, 2021

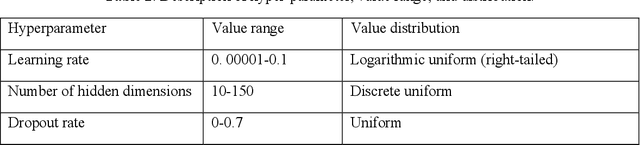
Background: COVID-19 has become a challenge worldwide and properly planning of medical resources is the key to combating COVID-19. In the US Veteran Affairs Health Care System (VA), many of the enrollees are susceptible to COVID-19. Predicting the COVID-19 to allocate medical resources promptly becomes a critical issue. When the VA enrollees have COVID-19 symptoms, it is recommended that their first step should be to call the VA Call Center. For confirmed COVID-19 patients, the median time from the first symptom to hospital admission was seven days. By predicting the number of COVID-19 related calls, we could predict imminent surges in healthcare use and plan medical resources ahead. Objective: The study aims to develop a method to forecast the daily number of COVID-19 related calls for each of the 110 VA medical centers. Methods: In the proposed method, we pre-trained a model using a cluster of medical centers and fine-tuned it for individual medical centers. At the cluster level, we performed feature selection to select significant features and automatic hyper-parameter search to select optimal hyper-parameter value combinations for the model. Conclusions: This study proposed an accurate method to forecast the daily number of COVID-19 related calls for VA medical centers. The proposed method was able to overcome modeling challenges by grouping similar medical centers into clusters to enlarge the dataset for training models, and using hyper-parameter search to automatically find optimal hyper-parameter value combinations for models. With the proposed method, surges in health care can be predicted ahead. This allows health care practitioners to better plan medical resources and combat COVID-19.
Automatic Detection of Cardiac Chambers Using an Attention-based YOLOv4 Framework from Four-chamber View of Fetal Echocardiography
Dec 13, 2020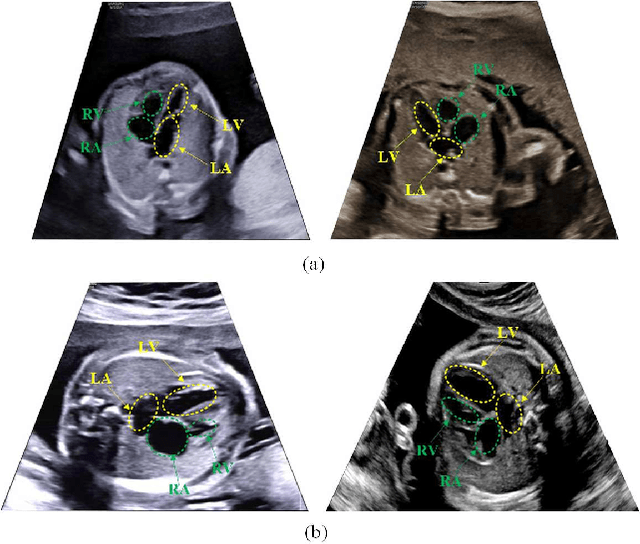
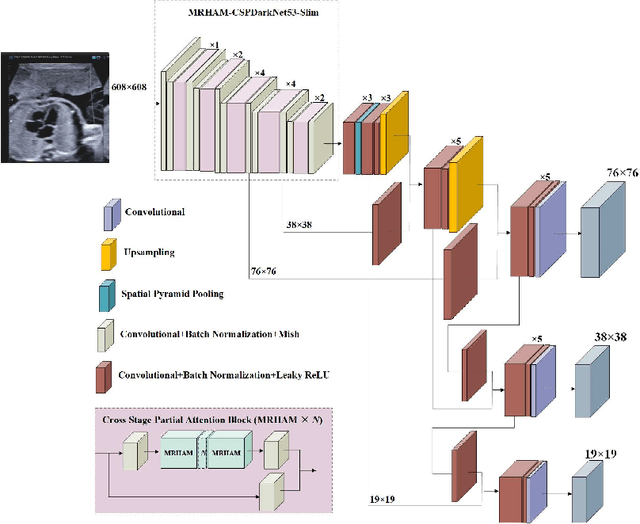
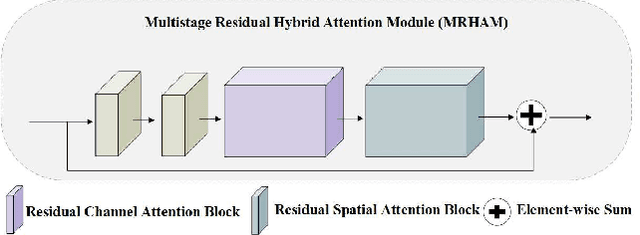
Echocardiography is a powerful prenatal examination tool for early diagnosis of fetal congenital heart diseases (CHDs). The four-chamber (FC) view is a crucial and easily accessible ultrasound (US) image among echocardiography images. Automatic analysis of FC views contributes significantly to the early diagnosis of CHDs. The first step to automatically analyze fetal FC views is locating the fetal four crucial chambers of heart in a US image. However, it is a greatly challenging task due to several key factors, such as numerous speckles in US images, the fetal cardiac chambers with small size and unfixed positions, and category indistinction caused by the similarity of cardiac chambers. These factors hinder the process of capturing robust and discriminative features, hence destroying fetal cardiac anatomical chambers precise localization. Therefore, we first propose a multistage residual hybrid attention module (MRHAM) to improve the feature learning. Then, we present an improved YOLOv4 detection model, namely MRHAM-YOLOv4-Slim. Specially, the residual identity mapping is replaced with the MRHAM in the backbone of MRHAM-YOLOv4-Slim, accurately locating the four important chambers in fetal FC views. Extensive experiments demonstrate that our proposed method outperforms current state-of-the-art, including the precision of 0.919, the recall of 0.971, the F1 score of 0.944, the mAP of 0.953, and the frames per second (FPS) of 43.
Progressive Sampling-Based Bayesian Optimization for Efficient and Automatic Machine Learning Model Selection
Dec 06, 2018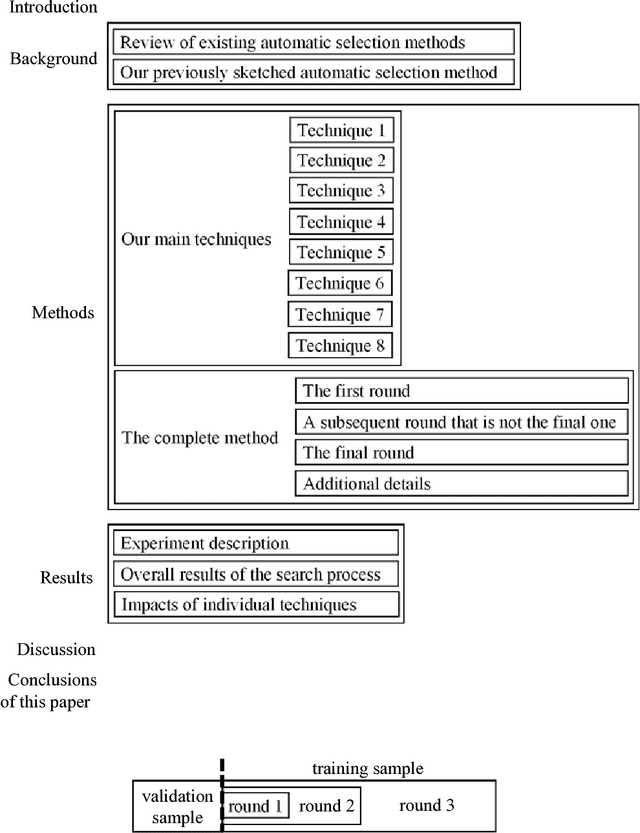
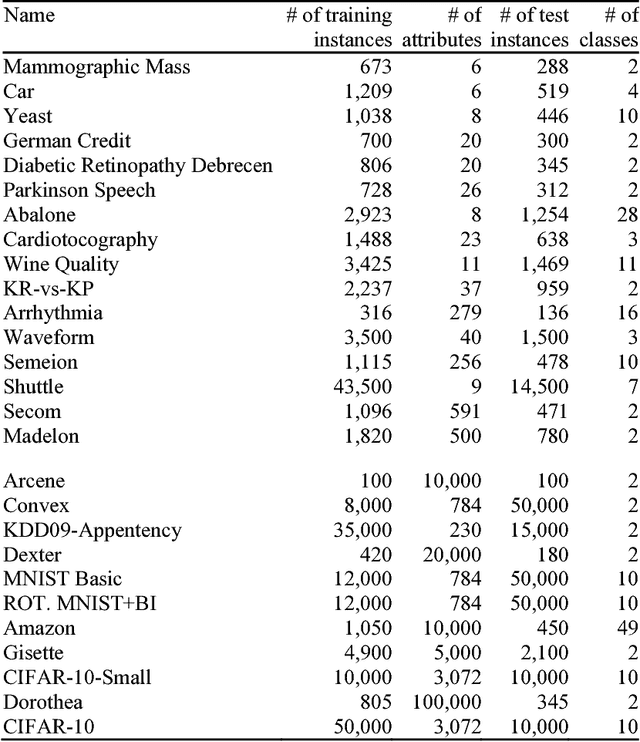
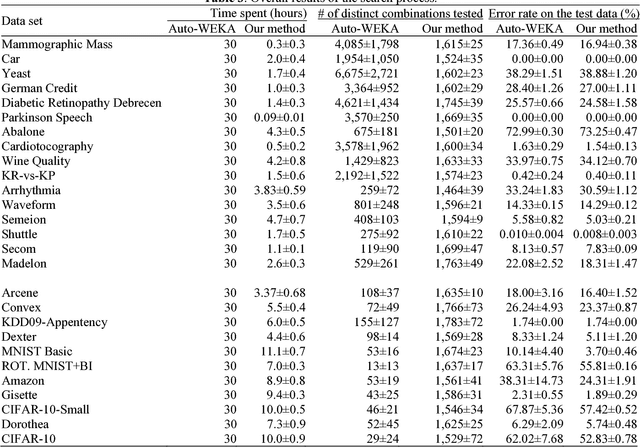
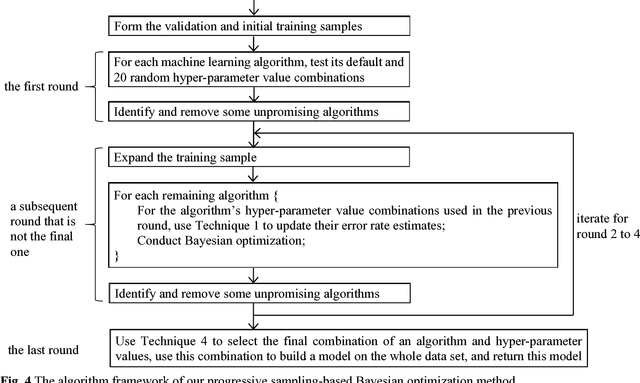
Purpose: Machine learning is broadly used for clinical data analysis. Before training a model, a machine learning algorithm must be selected. Also, the values of one or more model parameters termed hyper-parameters must be set. Selecting algorithms and hyper-parameter values requires advanced machine learning knowledge and many labor-intensive manual iterations. To lower the bar to machine learning, miscellaneous automatic selection methods for algorithms and/or hyper-parameter values have been proposed. Existing automatic selection methods are inefficient on large data sets. This poses a challenge for using machine learning in the clinical big data era. Methods: To address the challenge, this paper presents progressive sampling-based Bayesian optimization, an efficient and automatic selection method for both algorithms and hyper-parameter values. Results: We report an implementation of the method. We show that compared to a state of the art automatic selection method, our method can significantly reduce search time, classification error rate, and standard deviation of error rate due to randomization. Conclusions: This is major progress towards enabling fast turnaround in identifying high-quality solutions required by many machine learning-based clinical data analysis tasks.
Automatically Explaining Machine Learning Prediction Results: A Demonstration on Type 2 Diabetes Risk Prediction
Dec 06, 2018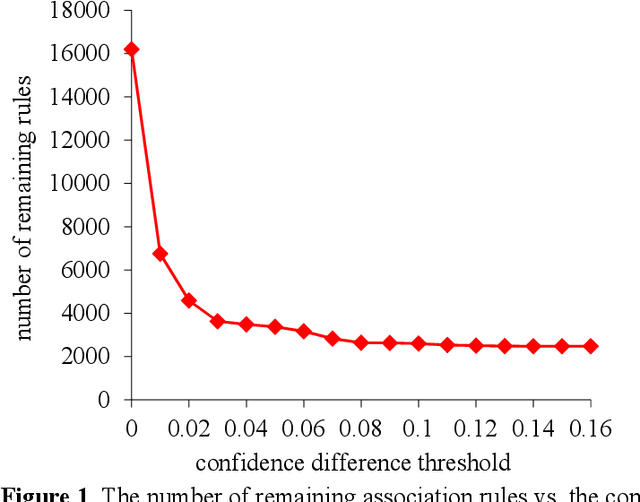
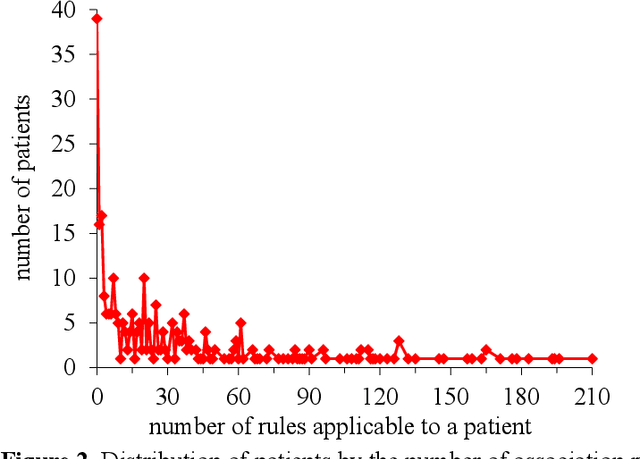
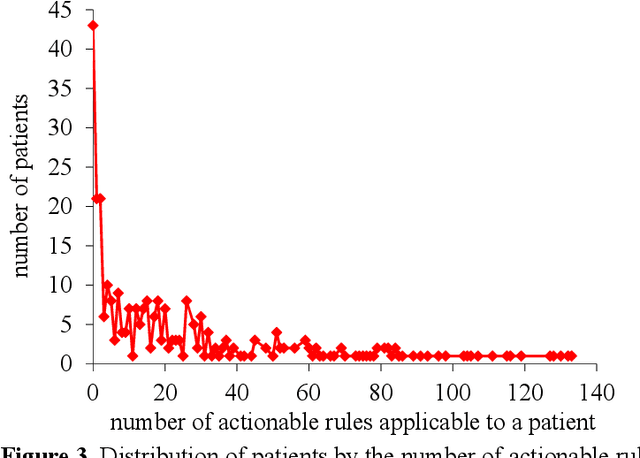
Background: Predictive modeling is a key component of solutions to many healthcare problems. Among all predictive modeling approaches, machine learning methods often achieve the highest prediction accuracy, but suffer from a long-standing open problem precluding their widespread use in healthcare. Most machine learning models give no explanation for their prediction results, whereas interpretability is essential for a predictive model to be adopted in typical healthcare settings. Methods: This paper presents the first complete method for automatically explaining results for any machine learning predictive model without degrading accuracy. We did a computer coding implementation of the method. Using the electronic medical record data set from the Practice Fusion diabetes classification competition containing patient records from all 50 states in the United States, we demonstrated the method on predicting type 2 diabetes diagnosis within the next year. Results: For the champion machine learning model of the competition, our method explained prediction results for 87.4% of patients who were correctly predicted by the model to have type 2 diabetes diagnosis within the next year. Conclusions: Our demonstration showed the feasibility of automatically explaining results for any machine learning predictive model without degrading accuracy.