 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRhetorical Text-to-Image Generation via Two-layer Diffusion Policy Optimization
May 28, 2025Generating images from rhetorical languages remains a critical challenge for text-to-image models. Even state-of-the-art (SOTA) multimodal large language models (MLLM) fail to generate images based on the hidden meaning inherent in rhetorical language--despite such content being readily mappable to visual representations by humans. A key limitation is that current models emphasize object-level word embedding alignment, causing metaphorical expressions to steer image generation towards their literal visuals and overlook the intended semantic meaning. To address this, we propose Rhet2Pix, a framework that formulates rhetorical text-to-image generation as a multi-step policy optimization problem, incorporating a two-layer MDP diffusion module. In the outer layer, Rhet2Pix converts the input prompt into incrementally elaborated sub-sentences and executes corresponding image-generation actions, constructing semantically richer visuals. In the inner layer, Rhet2Pix mitigates reward sparsity during image generation by discounting the final reward and optimizing every adjacent action pair along the diffusion denoising trajectory. Extensive experiments demonstrate the effectiveness of Rhet2Pix in rhetorical text-to-image generation. Our model outperforms SOTA MLLMs such as GPT-4o, Grok-3 and leading academic baselines across both qualitative and quantitative evaluations. The code and dataset used in this work are publicly available.
MDD-LLM: Towards Accuracy Large Language Models for Major Depressive Disorder Diagnosis
Apr 28, 2025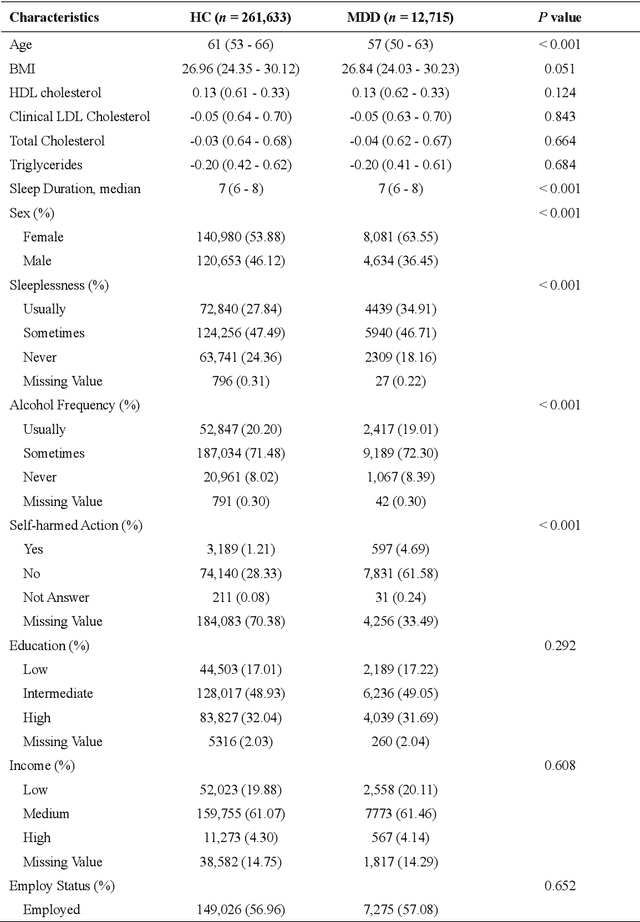
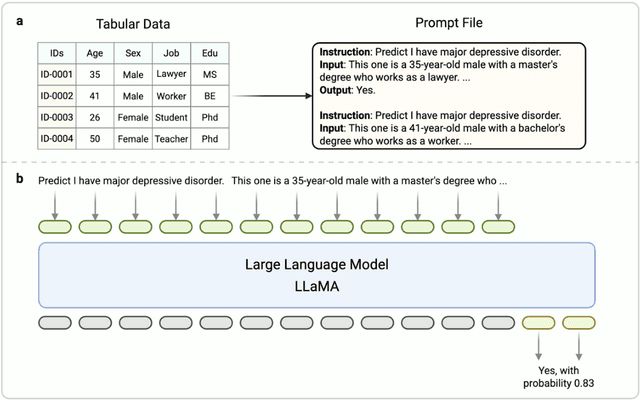

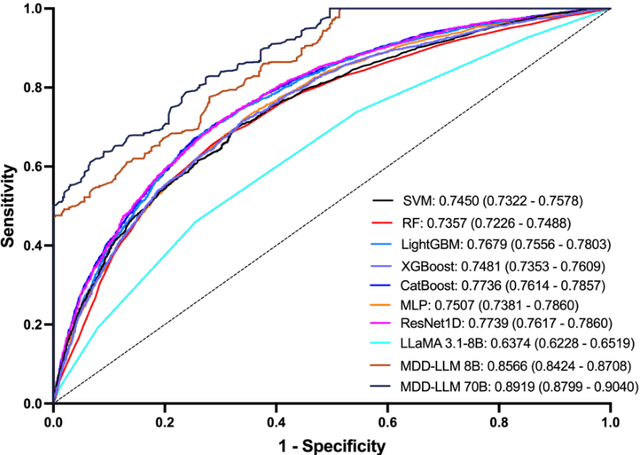
Major depressive disorder (MDD) impacts more than 300 million people worldwide, highlighting a significant public health issue. However, the uneven distribution of medical resources and the complexity of diagnostic methods have resulted in inadequate attention to this disorder in numerous countries and regions. This paper introduces a high-performance MDD diagnosis tool named MDD-LLM, an AI-driven framework that utilizes fine-tuned large language models (LLMs) and extensive real-world samples to tackle challenges in MDD diagnosis. Therefore, we select 274,348 individual information from the UK Biobank cohort to train and evaluate the proposed method. Specifically, we select 274,348 individual records from the UK Biobank cohort and design a tabular data transformation method to create a large corpus for training and evaluating the proposed approach. To illustrate the advantages of MDD-LLM, we perform comprehensive experiments and provide several comparative analyses against existing model-based solutions across multiple evaluation metrics. Experimental results show that MDD-LLM (70B) achieves an accuracy of 0.8378 and an AUC of 0.8919 (95% CI: 0.8799 - 0.9040), significantly outperforming existing machine learning and deep learning frameworks for MDD diagnosis. Given the limited exploration of LLMs in MDD diagnosis, we examine numerous factors that may influence the performance of our proposed method, such as tabular data transformation techniques and different fine-tuning strategies.
Detecting Credit Card Fraud via Heterogeneous Graph Neural Networks with Graph Attention
Apr 11, 2025This study proposes a credit card fraud detection method based on Heterogeneous Graph Neural Network (HGNN) to address fraud in complex transaction networks. Unlike traditional machine learning methods that rely solely on numerical features of transaction records, this approach constructs heterogeneous transaction graphs. These graphs incorporate multiple node types, including users, merchants, and transactions. By leveraging graph neural networks, the model captures higher-order transaction relationships. A Graph Attention Mechanism is employed to dynamically assign weights to different transaction relationships. Additionally, a Temporal Decay Mechanism is integrated to enhance the model's sensitivity to time-related fraud patterns. To address the scarcity of fraudulent transaction samples, this study applies SMOTE oversampling and Cost-sensitive Learning. These techniques strengthen the model's ability to identify fraudulent transactions. Experimental results demonstrate that the proposed method outperforms existing GNN models, including GCN, GAT, and GraphSAGE, on the IEEE-CIS Fraud Detection dataset. The model achieves notable improvements in both accuracy and OC-ROC. Future research may explore the integration of dynamic graph neural networks and reinforcement learning. Such advancements could enhance the real-time adaptability of fraud detection systems and provide more intelligent solutions for financial risk control.
Semantic Feature Learning for Universal Unsupervised Cross-Domain Retrieval
Mar 08, 2024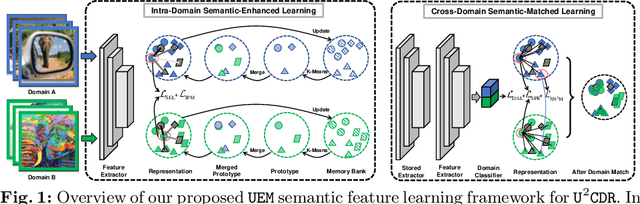
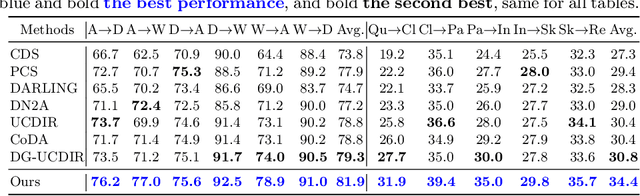
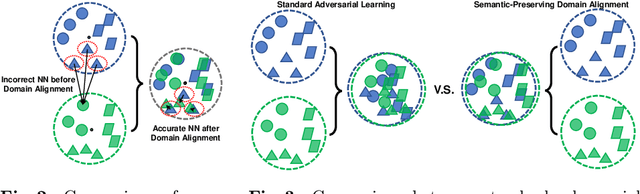
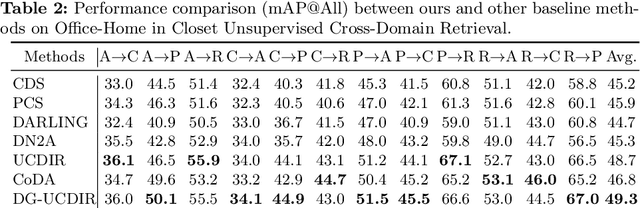
Cross-domain retrieval (CDR), as a crucial tool for numerous technologies, is finding increasingly broad applications. However, existing efforts face several major issues, with the most critical being the need for accurate supervision, which often demands costly resources and efforts. Cutting-edge studies focus on achieving unsupervised CDR but typically assume that the category spaces across domains are identical, an assumption that is often unrealistic in real-world scenarios. This is because only through dedicated and comprehensive analysis can the category spaces of different domains be confirmed as identical, which contradicts the premise of unsupervised scenarios. Therefore, in this work, we introduce the problem of Universal Unsupervised Cross-Domain Retrieval (U^2CDR) for the first time and design a two-stage semantic feature learning framework to address it. In the first stage, a cross-domain unified prototypical structure is established under the guidance of an instance-prototype-mixed contrastive loss and a semantic-enhanced loss, to counteract category space differences. In the second stage, through a modified adversarial training mechanism, we ensure minimal changes for the established prototypical structure during domain alignment, enabling more accurate nearest-neighbor searching. Extensive experiments across multiple datasets and scenarios, including closet, partial, and open-set CDR, demonstrate that our approach significantly outperforms existing state-of-the-art CDR works and some potentially effective studies from other topics in solving U^2CDR challenges.
DACR: Distribution-Augmented Contrastive Reconstruction for Time-Series Anomaly Detection
Jan 20, 2024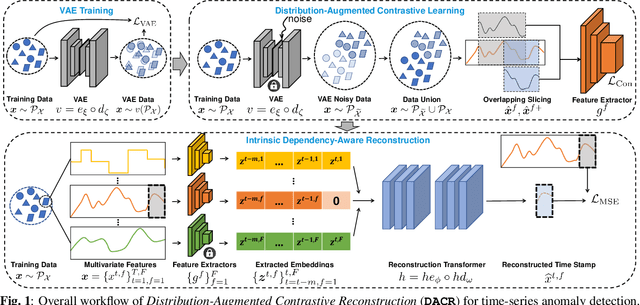
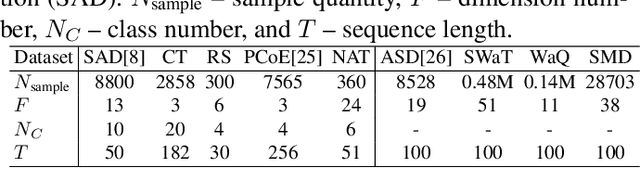
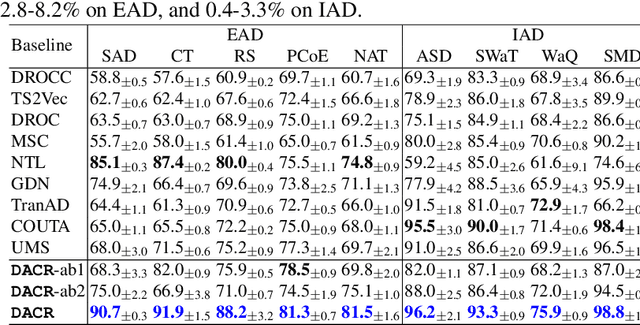
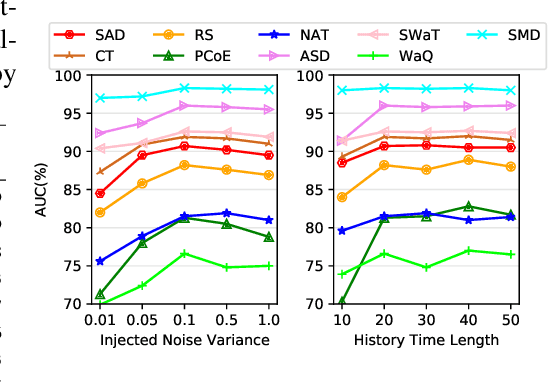
Anomaly detection in time-series data is crucial for identifying faults, failures, threats, and outliers across a range of applications. Recently, deep learning techniques have been applied to this topic, but they often struggle in real-world scenarios that are complex and highly dynamic, e.g., the normal data may consist of multiple distributions, and various types of anomalies may differ from the normal data to different degrees. In this work, to tackle these challenges, we propose Distribution-Augmented Contrastive Reconstruction (DACR). DACR generates extra data disjoint from the normal data distribution to compress the normal data's representation space, and enhances the feature extractor through contrastive learning to better capture the intrinsic semantics from time-series data. Furthermore, DACR employs an attention mechanism to model the semantic dependencies among multivariate time-series features, thereby achieving more robust reconstruction for anomaly detection. Extensive experiments conducted on nine benchmark datasets in various anomaly detection scenarios demonstrate the effectiveness of DACR in achieving new state-of-the-art time-series anomaly detection.
Contrastive Enhanced Slide Filter Mixer for Sequential Recommendation
May 07, 2023



Sequential recommendation (SR) aims to model user preferences by capturing behavior patterns from their item historical interaction data. Most existing methods model user preference in the time domain, omitting the fact that users' behaviors are also influenced by various frequency patterns that are difficult to separate in the entangled chronological items. However, few attempts have been made to train SR in the frequency domain, and it is still unclear how to use the frequency components to learn an appropriate representation for the user. To solve this problem, we shift the viewpoint to the frequency domain and propose a novel Contrastive Enhanced \textbf{SLI}de Filter \textbf{M}ixEr for Sequential \textbf{Rec}ommendation, named \textbf{SLIME4Rec}. Specifically, we design a frequency ramp structure to allow the learnable filter slide on the frequency spectrums across different layers to capture different frequency patterns. Moreover, a Dynamic Frequency Selection (DFS) and a Static Frequency Split (SFS) module are proposed to replace the self-attention module for effectively extracting frequency information in two ways. DFS is used to select helpful frequency components dynamically, and SFS is combined with the dynamic frequency selection module to provide a more fine-grained frequency division. Finally, contrastive learning is utilized to improve the quality of user embedding learned from the frequency domain. Extensive experiments conducted on five widely used benchmark datasets demonstrate our proposed model performs significantly better than the state-of-the-art approaches. Our code is available at https://github.com/sudaada/SLIME4Rec.
Frequency Enhanced Hybrid Attention Network for Sequential Recommendation
Apr 18, 2023



The self-attention mechanism, which equips with a strong capability of modeling long-range dependencies, is one of the extensively used techniques in the sequential recommendation field. However, many recent studies represent that current self-attention based models are low-pass filters and are inadequate to capture high-frequency information. Furthermore, since the items in the user behaviors are intertwined with each other, these models are incomplete to distinguish the inherent periodicity obscured in the time domain. In this work, we shift the perspective to the frequency domain, and propose a novel Frequency Enhanced Hybrid Attention Network for Sequential Recommendation, namely FEARec. In this model, we firstly improve the original time domain self-attention in the frequency domain with a ramp structure to make both low-frequency and high-frequency information could be explicitly learned in our approach. Moreover, we additionally design a similar attention mechanism via auto-correlation in the frequency domain to capture the periodic characteristics and fuse the time and frequency level attention in a union model. Finally, both contrastive learning and frequency regularization are utilized to ensure that multiple views are aligned in both the time domain and frequency domain. Extensive experiments conducted on four widely used benchmark datasets demonstrate that the proposed model performs significantly better than the state-of-the-art approaches.
Online Camera-to-ground Calibration for Autonomous Driving
Mar 31, 2023
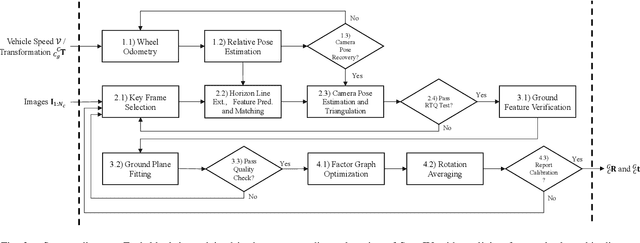
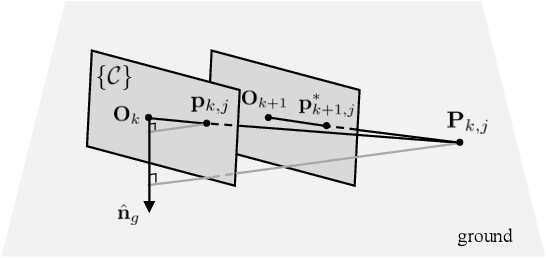
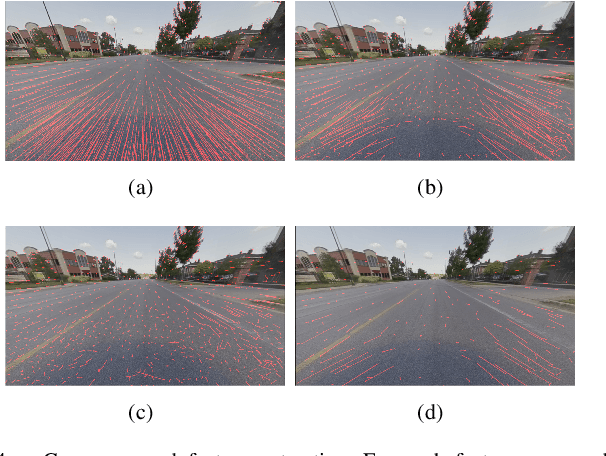
Online camera-to-ground calibration is to generate a non-rigid body transformation between the camera and the road surface in a real-time manner. Existing solutions utilize static calibration, suffering from environmental variations such as tire pressure changes, vehicle loading volume variations, and road surface diversity. Other online solutions exploit the usage of road elements or photometric consistency between overlapping views across images, which require continuous detection of specific targets on the road or assistance with multiple cameras to facilitate calibration. In our work, we propose an online monocular camera-to-ground calibration solution that does not utilize any specific targets while driving. We perform a coarse-to-fine approach for ground feature extraction through wheel odometry and estimate the camera-to-ground calibration parameters through a sliding-window-based factor graph optimization. Considering the non-rigid transformation of camera-to-ground while driving, we provide metrics to quantify calibration performance and stopping criteria to report/broadcast our satisfying calibration results. Extensive experiments using real-world data demonstrate that our algorithm is effective and outperforms state-of-the-art techniques.