 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDACR: Distribution-Augmented Contrastive Reconstruction for Time-Series Anomaly Detection
Jan 20, 2024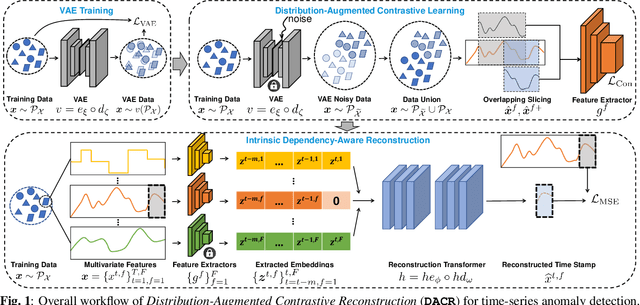
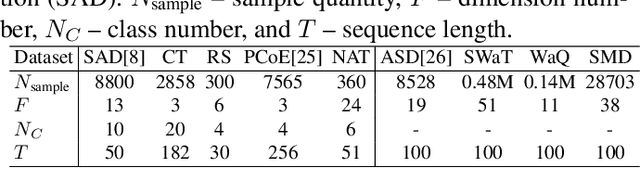
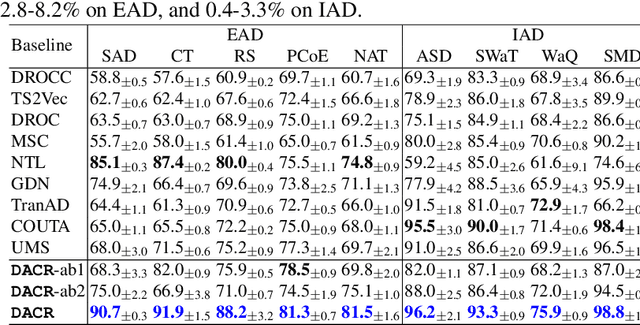
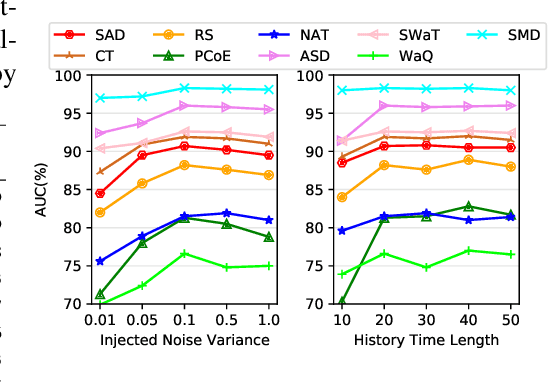
Anomaly detection in time-series data is crucial for identifying faults, failures, threats, and outliers across a range of applications. Recently, deep learning techniques have been applied to this topic, but they often struggle in real-world scenarios that are complex and highly dynamic, e.g., the normal data may consist of multiple distributions, and various types of anomalies may differ from the normal data to different degrees. In this work, to tackle these challenges, we propose Distribution-Augmented Contrastive Reconstruction (DACR). DACR generates extra data disjoint from the normal data distribution to compress the normal data's representation space, and enhances the feature extractor through contrastive learning to better capture the intrinsic semantics from time-series data. Furthermore, DACR employs an attention mechanism to model the semantic dependencies among multivariate time-series features, thereby achieving more robust reconstruction for anomaly detection. Extensive experiments conducted on nine benchmark datasets in various anomaly detection scenarios demonstrate the effectiveness of DACR in achieving new state-of-the-art time-series anomaly detection.
A Dual Modality Approach For Multi-Label Classification
Aug 19, 2022

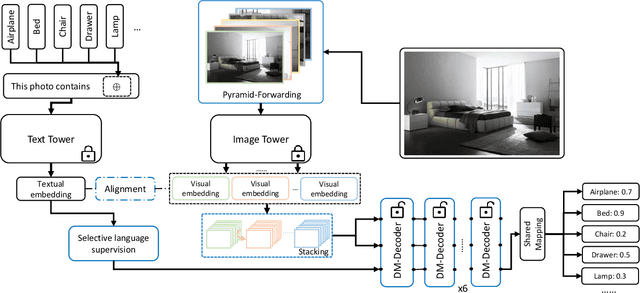
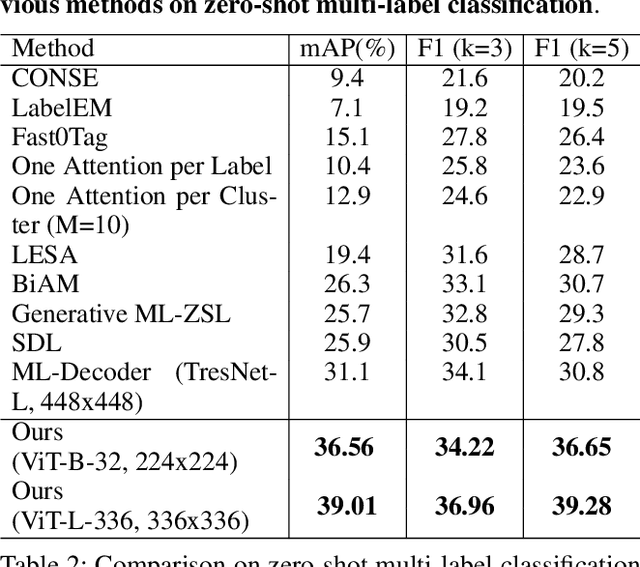
In computer vision, multi-label classification, including zero-shot multi-label classification are important tasks with many real-world applications. In this paper, we propose a novel algorithm, Aligned Dual moDality ClaSsifier (ADDS), which includes a Dual-Modal decoder (DM-decoder) with alignment between visual and textual features, for multi-label classification tasks. Moreover, we design a simple and yet effective method called Pyramid-Forwarding to enhance the performance for inputs with high resolutions. Extensive experiments conducted on standard multi-label benchmark datasets, MS-COCO and NUS-WIDE, demonstrate that our approach significantly outperforms previous methods and provides state-of-the-art performance for conventional multi-label classification, zero-shot multi-label classification, and an extreme case called single-to-multi label classification where models trained on single-label datasets (ImageNet-1k, ImageNet-21k) are tested on multi-label ones (MS-COCO and NUS-WIDE). We also analyze how visual-textual alignment contributes to the proposed approach, validate the significance of the DM-decoder, and demonstrate the effectiveness of Pyramid-Forwarding on vision transformer.
Federated Class-Incremental Learning
Mar 22, 2022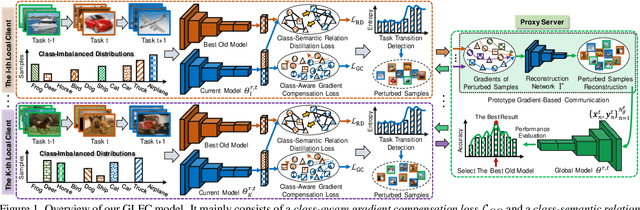
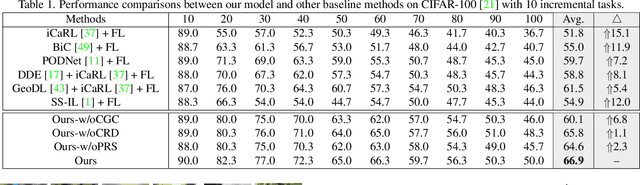

Federated learning (FL) has attracted growing attention via data-private collaborative training on decentralized clients. However, most existing methods unrealistically assume object classes of the overall framework are fixed over time. It makes the global model suffer from significant catastrophic forgetting on old classes in real-world scenarios, where local clients often collect new classes continuously and have very limited storage memory to store old classes. Moreover, new clients with unseen new classes may participate in the FL training, further aggravating the catastrophic forgetting of the global model. To address these challenges, we develop a novel Global-Local Forgetting Compensation (GLFC) model, to learn a global class incremental model for alleviating the catastrophic forgetting from both local and global perspectives. Specifically, to address local forgetting caused by class imbalance at the local clients, we design a class-aware gradient compensation loss and a class-semantic relation distillation loss to balance the forgetting of old classes and distill consistent inter-class relations across tasks. To tackle the global forgetting brought by the non-i.i.d class imbalance across clients, we propose a proxy server that selects the best old global model to assist the local relation distillation. Moreover, a prototype gradient-based communication mechanism is developed to protect privacy. Our model outperforms state-of-the-art methods by 4.4%-15.1% in terms of average accuracy on representative benchmark datasets.
Model-assisted Learning-based Framework for Sensor Fault-Tolerant Building HVAC Control
Jun 27, 2021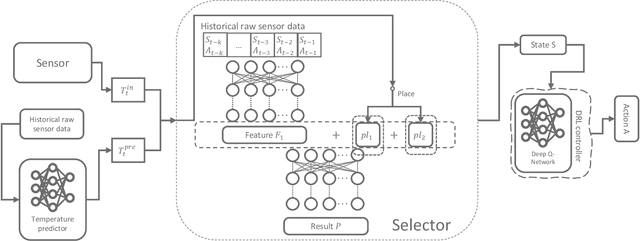
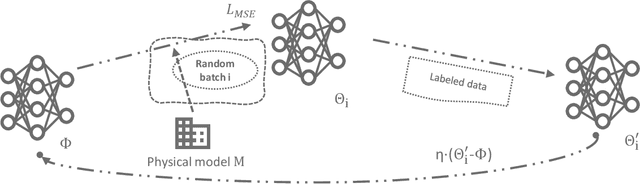
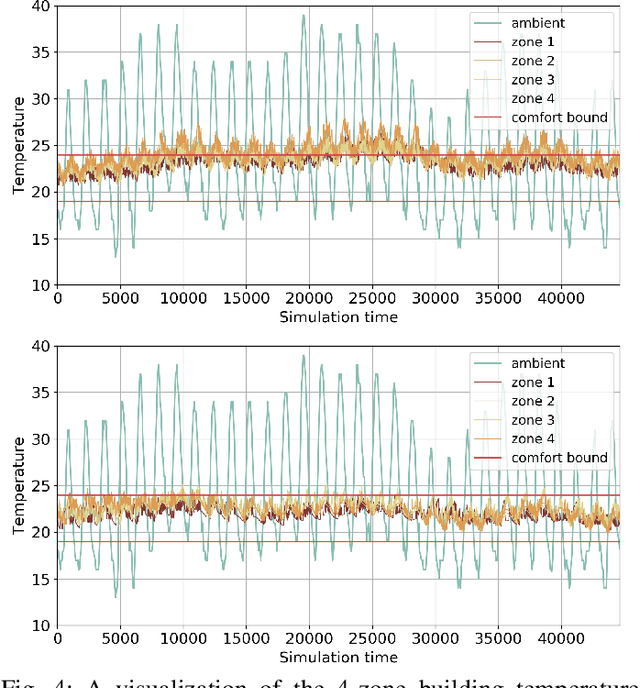
As people spend up to 87% of their time indoors, intelligent Heating, Ventilation, and Air Conditioning (HVAC) systems in buildings are essential for maintaining occupant comfort and reducing energy consumption. Those HVAC systems in modern smart buildings rely on real-time sensor readings, which in practice often suffer from various faults and could also be vulnerable to malicious attacks. Such faulty sensor inputs may lead to the violation of indoor environment requirements (e.g., temperature, humidity, etc.) and the increase of energy consumption. While many model-based approaches have been proposed in the literature for building HVAC control, it is costly to develop accurate physical models for ensuring their performance and even more challenging to address the impact of sensor faults. In this work, we present a novel learning-based framework for sensor fault-tolerant HVAC control, which includes three deep learning based components for 1) generating temperature proposals with the consideration of possible sensor faults, 2) selecting one of the proposals based on the assessment of their accuracy, and 3) applying reinforcement learning with the selected temperature proposal. Moreover, to address the challenge of training data insufficiency in building-related tasks, we propose a model-assisted learning method leveraging an abstract model of building physical dynamics. Through extensive numerical experiments, we demonstrate that the proposed fault-tolerant HVAC control framework can significantly reduce building temperature violations under a variety of sensor fault patterns while maintaining energy efficiency.
Non-Transferable Learning: A New Approach for Model Verification and Authorization
Jun 13, 2021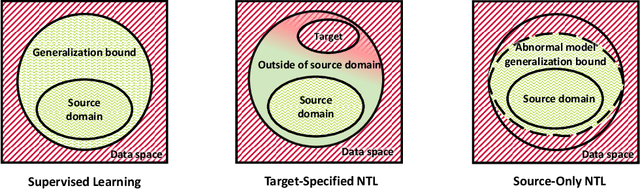

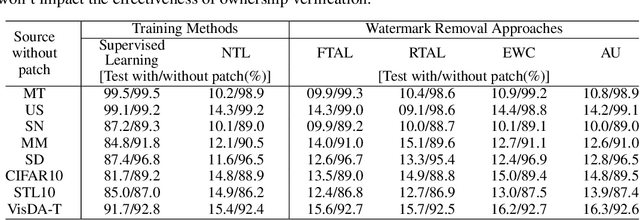

As Artificial Intelligence as a Service gains popularity, protecting well-trained models as intellectual property is becoming increasingly important. Generally speaking, there are two common protection methods: ownership verification and usage authorization. In this paper, we propose Non-Transferable Learning (NTL), a novel approach that captures the exclusive data representation in the learned model and restricts the model generalization ability to certain domains. This approach provides effective solutions to both model verification and authorization. For ownership verification, watermarking techniques are commonly used but are often vulnerable to sophisticated watermark removal methods. Our NTL-based model verification approach instead provides robust resistance to state-of-the-art watermark removal methods, as shown in extensive experiments for four of such methods over the digits, CIFAR10 & STL10, and VisDA datasets. For usage authorization, prior solutions focus on authorizing specific users to use the model, but authorized users can still apply the model to any data without restriction. Our NTL-based authorization approach instead provides data-centric usage protection by significantly degrading the performance of usage on unauthorized data. Its effectiveness is also shown through experiments on a variety of datasets.
Weak Adaptation Learning -- Addressing Cross-domain Data Insufficiency with Weak Annotator
Feb 15, 2021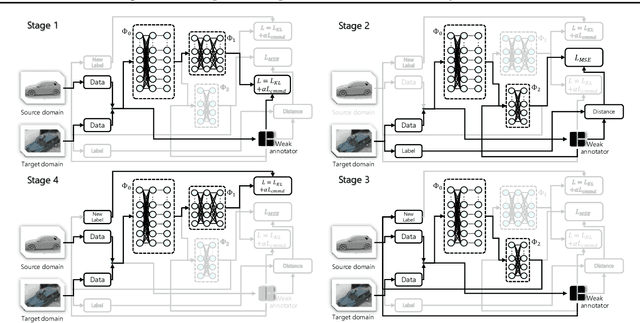
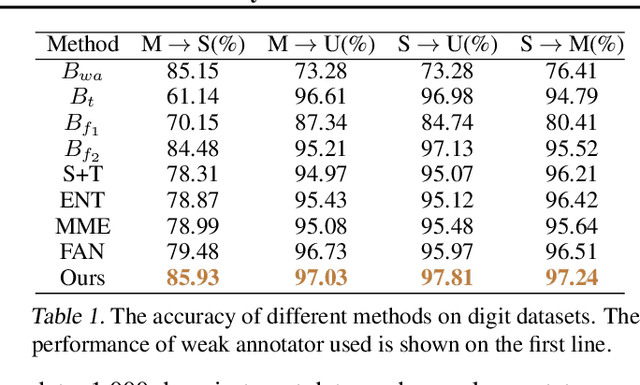
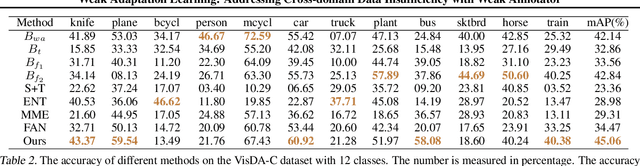
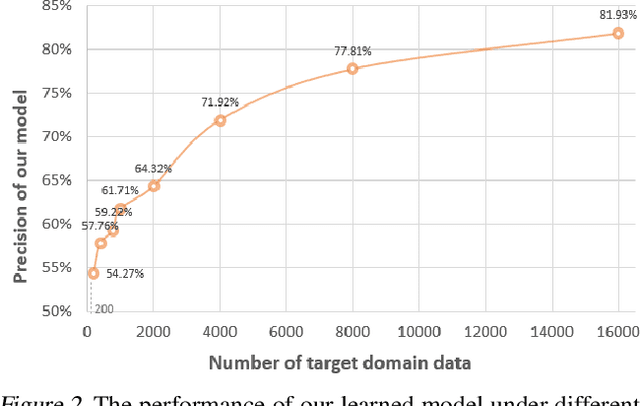
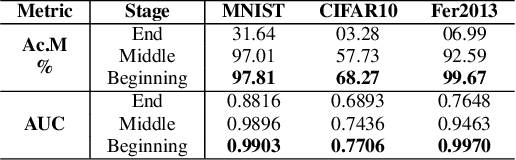
Data quantity and quality are crucial factors for data-driven learning methods. In some target problem domains, there are not many data samples available, which could significantly hinder the learning process. While data from similar domains may be leveraged to help through domain adaptation, obtaining high-quality labeled data for those source domains themselves could be difficult or costly. To address such challenges on data insufficiency for classification problem in a target domain, we propose a weak adaptation learning (WAL) approach that leverages unlabeled data from a similar source domain, a low-cost weak annotator that produces labels based on task-specific heuristics, labeling rules, or other methods (albeit with inaccuracy), and a small amount of labeled data in the target domain. Our approach first conducts a theoretical analysis on the error bound of the trained classifier with respect to the data quantity and the performance of the weak annotator, and then introduces a multi-stage weak adaptation learning method to learn an accurate classifier by lowering the error bound. Our experiments demonstrate the effectiveness of our approach in learning an accurate classifier with limited labeled data in the target domain and unlabeled data in the source domain.
Towards Class Imbalance in Federated Learning
Aug 14, 2020
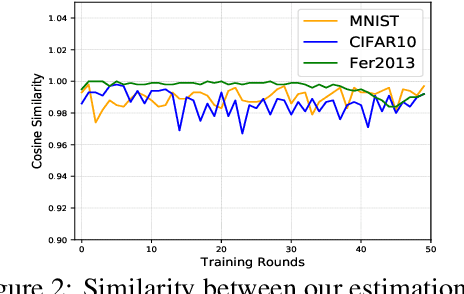

Federated learning (FL) is a promising approach for training decentralized data located on local client devices while improving efficiency and privacy. However, the distribution and quantity of the training data on the clients' side may lead to significant challenges such as data imbalance and non-IID (non-independent and identically distributed) data, which could greatly impact the performance of the common model. While much effort has been devoted to helping FL models converge when encountering non-IID data, the imbalance issue has not been sufficiently addressed. In particular, as FL training is executed by exchanging gradients in an encrypted form, the training data is not completely observable to either clients or server, and previous methods for data imbalance do not perform well for FL. Therefore, it is crucial to design new methods for detecting data imbalance in FL and mitigating its impact. In this work, we propose a monitoring scheme that can infer the composition proportion of training data for each FL round, and design a new loss function -- Ratio Loss to mitigate the impact of the imbalance. Our experiments demonstrate the importance of detecting data imbalance and taking measures as early as possible in FL training, and the effectiveness of our method in mitigating the impact. Our method is shown to significantly outperform previous methods, while maintaining client privacy.
One for Many: Transfer Learning for Building HVAC Control
Aug 09, 2020
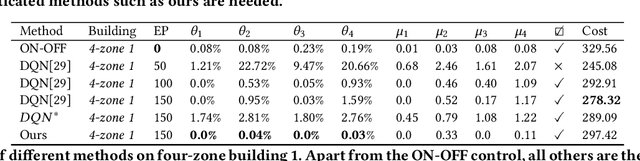
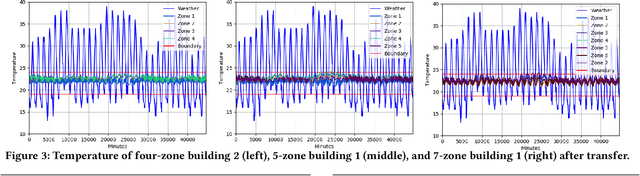
The design of building heating, ventilation, and air conditioning (HVAC) system is critically important, as it accounts for around half of building energy consumption and directly affects occupant comfort, productivity, and health. Traditional HVAC control methods are typically based on creating explicit physical models for building thermal dynamics, which often require significant effort to develop and are difficult to achieve sufficient accuracy and efficiency for runtime building control and scalability for field implementations. Recently, deep reinforcement learning (DRL) has emerged as a promising data-driven method that provides good control performance without analyzing physical models at runtime. However, a major challenge to DRL (and many other data-driven learning methods) is the long training time it takes to reach the desired performance. In this work, we present a novel transfer learning based approach to overcome this challenge. Our approach can effectively transfer a DRL-based HVAC controller trained for the source building to a controller for the target building with minimal effort and improved performance, by decomposing the design of neural network controller into a transferable front-end network that captures building-agnostic behavior and a back-end network that can be efficiently trained for each specific building. We conducted experiments on a variety of transfer scenarios between buildings with different sizes, numbers of thermal zones, materials and layouts, air conditioner types, and ambient weather conditions. The experimental results demonstrated the effectiveness of our approach in significantly reducing the training time, energy cost, and temperature violations.
Eavesdrop the Composition Proportion of Training Labels in Federated Learning
Oct 27, 2019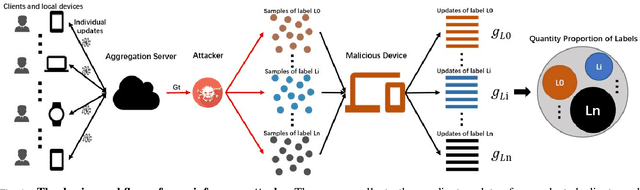
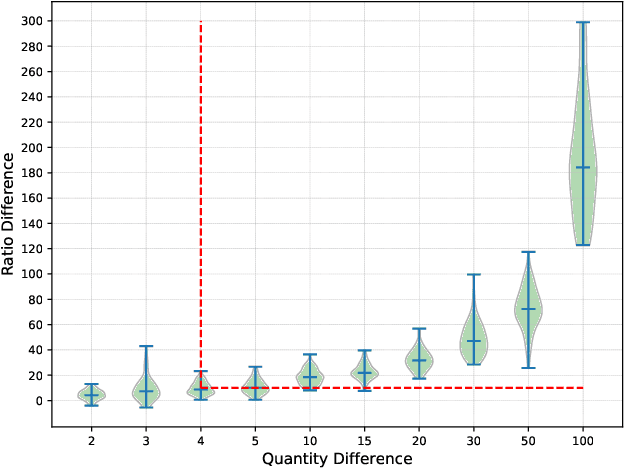
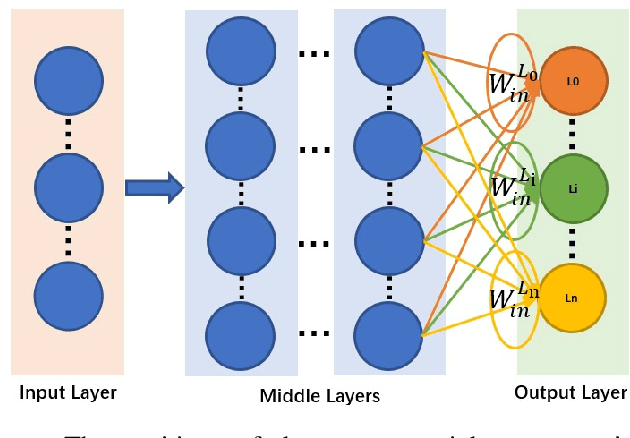

Federated learning (FL) has recently emerged as a new form of collaborative machine learning, where a common model can be learned while keeping all the training data on local devices. Although it is designed for enhancing the data privacy, we demonstrated in this paper a new direction in inference attacks in the context of FL, where valuable information about training data can be obtained by adversaries with very limited power. In particular, we proposed three new types of attacks to exploit this vulnerability. The first type of attack, Class Sniffing, can detect whether a certain label appears in training. The other two types of attacks can determine the quantity of each label, i.e., Quantity Inference attack determines the composition proportion of the training label owned by the selected clients in a single round, while Whole Determination attack determines that of the whole training process. We evaluated our attacks on a variety of tasks and datasets with different settings, and the corresponding results showed that our attacks work well generally. Finally, we analyzed the impact of major hyper-parameters to our attacks and discussed possible defenses.
MaskPlus: Improving Mask Generation for Instance Segmentation
Sep 05, 2019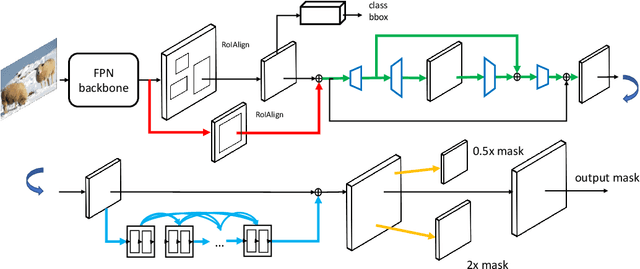
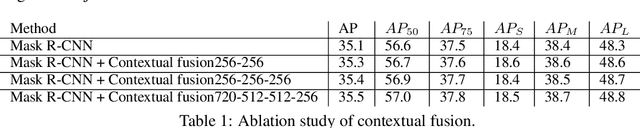
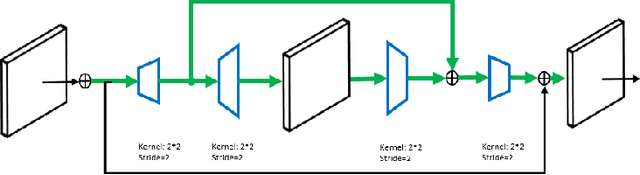
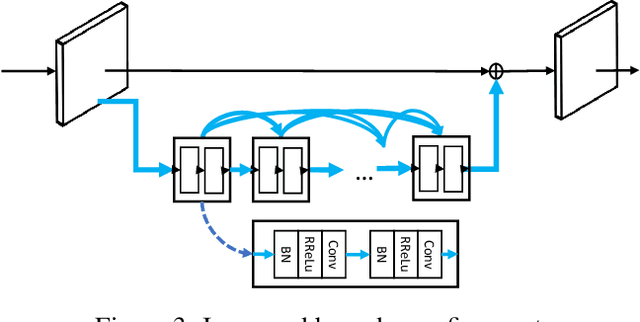
Instance segmentation is a promising yet challenging topic in computer vision. Recent approaches such as Mask R-CNN typically divide this problem into two parts -- a detection component and a mask generation branch, and mostly focus on the improvement of the detection part. In this paper, we present an approach that extends Mask R-CNN with five novel optimization techniques for improving the mask generation branch and reducing the conflicts between the mask branch and the detection component in training. These five techniques are independent to each other and can be flexibly utilized in building various instance segmentation architectures for increasing the overall accuracy. We demonstrate the effectiveness of our approach with tests on the COCO dataset.