 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dual Modality Approach For Multi-Label Classification
Paper and Code
Aug 19, 2022

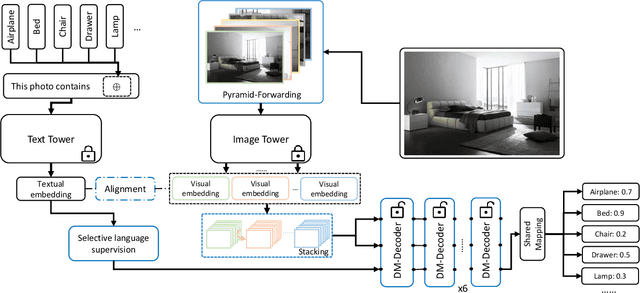
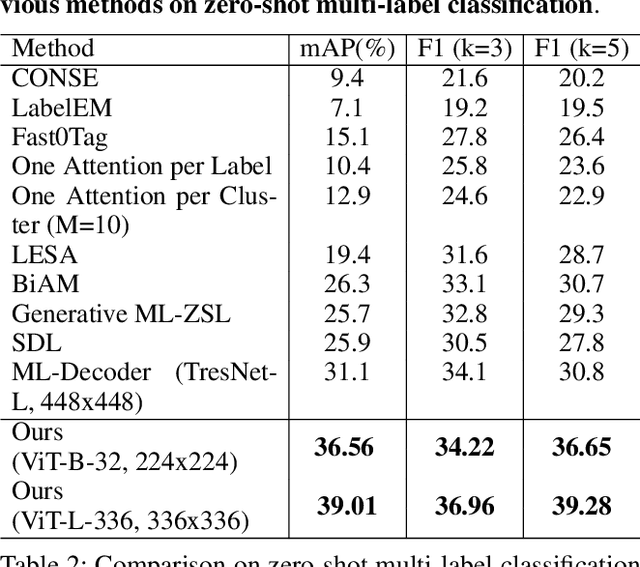
In computer vision, multi-label classification, including zero-shot multi-label classification are important tasks with many real-world applications. In this paper, we propose a novel algorithm, Aligned Dual moDality ClaSsifier (ADDS), which includes a Dual-Modal decoder (DM-decoder) with alignment between visual and textual features, for multi-label classification tasks. Moreover, we design a simple and yet effective method called Pyramid-Forwarding to enhance the performance for inputs with high resolutions. Extensive experiments conducted on standard multi-label benchmark datasets, MS-COCO and NUS-WIDE, demonstrate that our approach significantly outperforms previous methods and provides state-of-the-art performance for conventional multi-label classification, zero-shot multi-label classification, and an extreme case called single-to-multi label classification where models trained on single-label datasets (ImageNet-1k, ImageNet-21k) are tested on multi-label ones (MS-COCO and NUS-WIDE). We also analyze how visual-textual alignment contributes to the proposed approach, validate the significance of the DM-decoder, and demonstrate the effectiveness of Pyramid-Forwarding on vision transformer.