 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeak Adaptation Learning -- Addressing Cross-domain Data Insufficiency with Weak Annotator
Paper and Code
Feb 15, 2021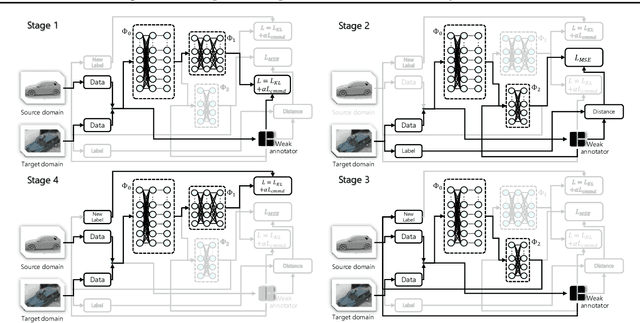
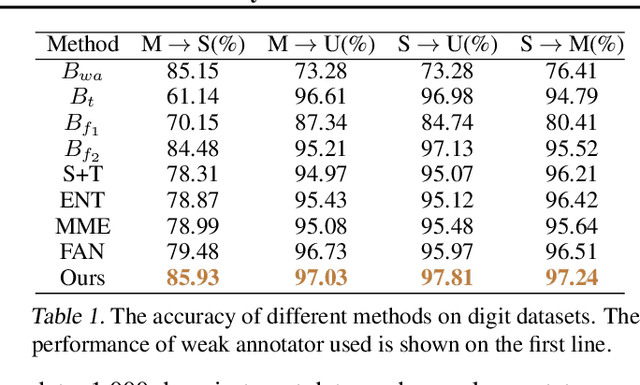
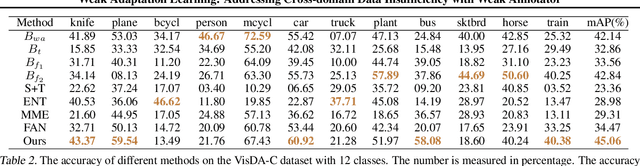
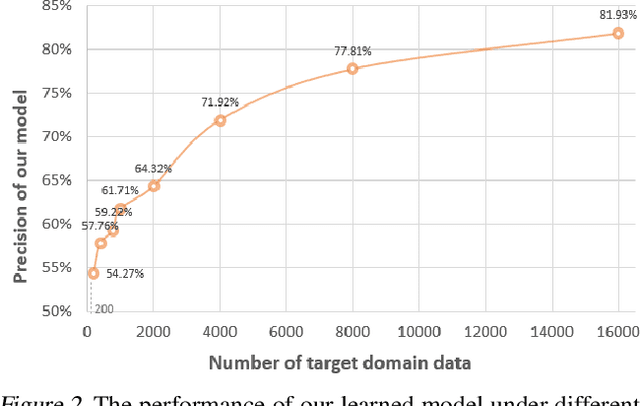
Data quantity and quality are crucial factors for data-driven learning methods. In some target problem domains, there are not many data samples available, which could significantly hinder the learning process. While data from similar domains may be leveraged to help through domain adaptation, obtaining high-quality labeled data for those source domains themselves could be difficult or costly. To address such challenges on data insufficiency for classification problem in a target domain, we propose a weak adaptation learning (WAL) approach that leverages unlabeled data from a similar source domain, a low-cost weak annotator that produces labels based on task-specific heuristics, labeling rules, or other methods (albeit with inaccuracy), and a small amount of labeled data in the target domain. Our approach first conducts a theoretical analysis on the error bound of the trained classifier with respect to the data quantity and the performance of the weak annotator, and then introduces a multi-stage weak adaptation learning method to learn an accurate classifier by lowering the error bound. Our experiments demonstrate the effectiveness of our approach in learning an accurate classifier with limited labeled data in the target domain and unlabeled data in the source domain.