 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Multi-Agent Video Fast-Forwarding
May 27, 2023Multi-agent applications have recently gained significant popularity. In many computer vision tasks, a network of agents, such as a team of robots with cameras, could work collaboratively to perceive the environment for efficient and accurate situation awareness. However, these agents often have limited computation, communication, and storage resources. Thus, reducing resource consumption while still providing an accurate perception of the environment becomes an important goal when deploying multi-agent systems. To achieve this goal, we identify and leverage the overlap among different camera views in multi-agent systems for reducing the processing, transmission and storage of redundant/unimportant video frames. Specifically, we have developed two collaborative multi-agent video fast-forwarding frameworks in distributed and centralized settings, respectively. In these frameworks, each individual agent can selectively process or skip video frames at adjustable paces based on multiple strategies via reinforcement learning. Multiple agents then collaboratively sense the environment via either 1) a consensus-based distributed framework called DMVF that periodically updates the fast-forwarding strategies of agents by establishing communication and consensus among connected neighbors, or 2) a centralized framework called MFFNet that utilizes a central controller to decide the fast-forwarding strategies for agents based on collected data. We demonstrate the efficacy and efficiency of our proposed frameworks on a real-world surveillance video dataset VideoWeb and a new simulated driving dataset CarlaSim, through extensive simulations and deployment on an embedded platform with TCP communication. We show that compared with other approaches in the literature, our frameworks achieve better coverage of important frames, while significantly reducing the number of frames processed at each agent.
Distributed Multi-agent Video Fast-forwarding
Aug 10, 2020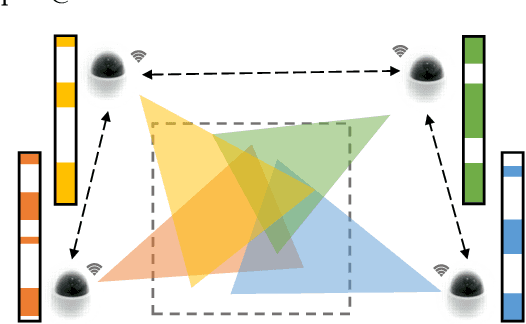

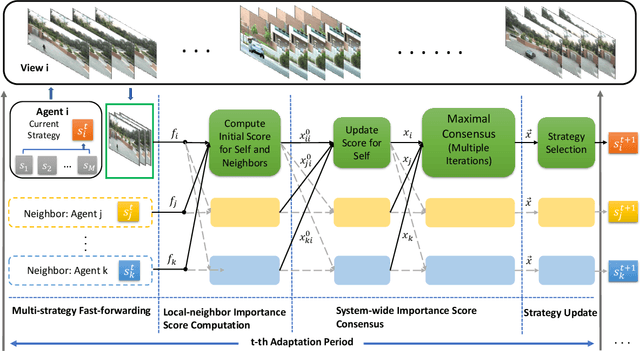
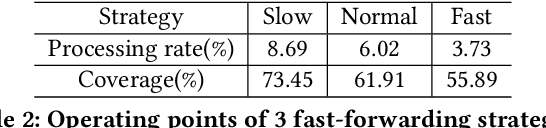
In many intelligent systems, a network of agents collaboratively perceives the environment for better and more efficient situation awareness. As these agents often have limited resources, it could be greatly beneficial to identify the content overlapping among camera views from different agents and leverage it for reducing the processing, transmission and storage of redundant/unimportant video frames. This paper presents a consensus-based distributed multi-agent video fast-forwarding framework, named DMVF, that fast-forwards multi-view video streams collaboratively and adaptively. In our framework, each camera view is addressed by a reinforcement learning based fast-forwarding agent, which periodically chooses from multiple strategies to selectively process video frames and transmits the selected frames at adjustable paces. During every adaptation period, each agent communicates with a number of neighboring agents, evaluates the importance of the selected frames from itself and those from its neighbors, refines such evaluation together with other agents via a system-wide consensus algorithm, and uses such evaluation to decide their strategy for the next period. Compared with approaches in the literature on a real-world surveillance video dataset VideoWeb, our method significantly improves the coverage of important frames and also reduces the number of frames processed in the system.
MaskPlus: Improving Mask Generation for Instance Segmentation
Sep 05, 2019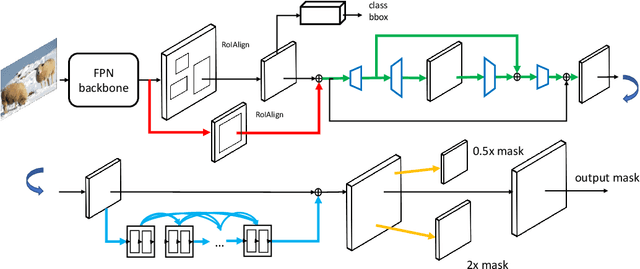
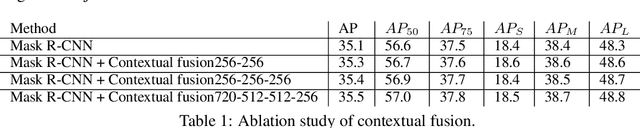
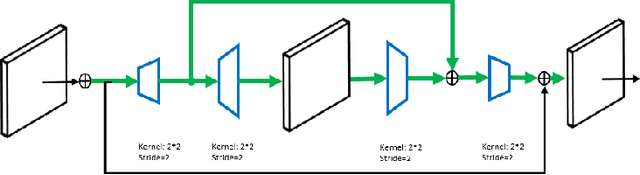
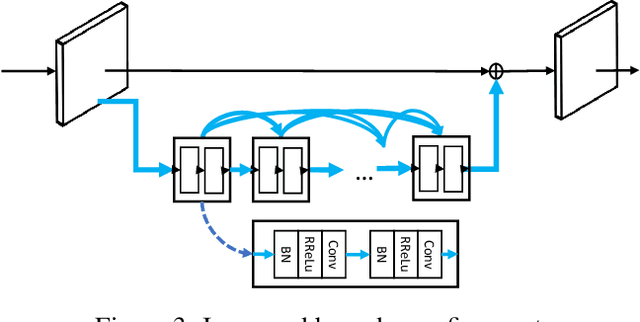
Instance segmentation is a promising yet challenging topic in computer vision. Recent approaches such as Mask R-CNN typically divide this problem into two parts -- a detection component and a mask generation branch, and mostly focus on the improvement of the detection part. In this paper, we present an approach that extends Mask R-CNN with five novel optimization techniques for improving the mask generation branch and reducing the conflicts between the mask branch and the detection component in training. These five techniques are independent to each other and can be flexibly utilized in building various instance segmentation architectures for increasing the overall accuracy. We demonstrate the effectiveness of our approach with tests on the COCO dataset.
FFNet: Video Fast-Forwarding via Reinforcement Learning
May 08, 2018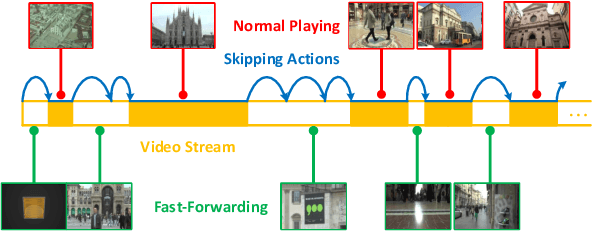
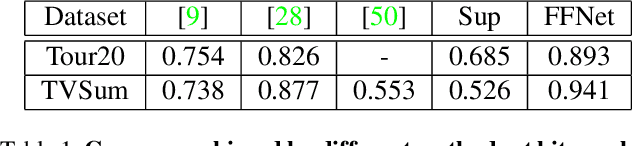
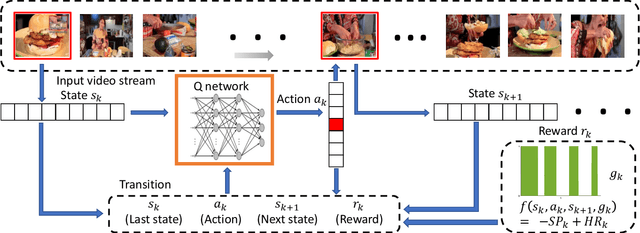
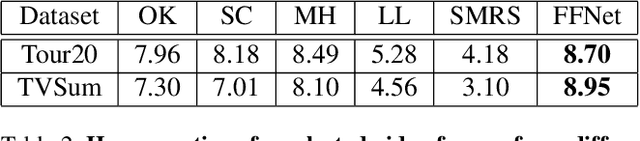
For many applications with limited computation, communication, storage and energy resources, there is an imperative need of computer vision methods that could select an informative subset of the input video for efficient processing at or near real time. In the literature, there are two relevant groups of approaches: generating a trailer for a video or fast-forwarding while watching/processing the video. The first group is supported by video summarization techniques, which require processing of the entire video to select an important subset for showing to users. In the second group, current fast-forwarding methods depend on either manual control or automatic adaptation of playback speed, which often do not present an accurate representation and may still require processing of every frame. In this paper, we introduce FastForwardNet (FFNet), a reinforcement learning agent that gets inspiration from video summarization and does fast-forwarding differently. It is an online framework that automatically fast-forwards a video and presents a representative subset of frames to users on the fly. It does not require processing the entire video, but just the portion that is selected by the fast-forward agent, which makes the process very computationally efficient. The online nature of our proposed method also enables the users to begin fast-forwarding at any point of the video. Experiments on two real-world datasets demonstrate that our method can provide better representation of the input video with much less processing requirement.