 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiasing Federated Learning with Correlated Client Participation
Oct 02, 2024In cross-device federated learning (FL) with millions of mobile clients, only a small subset of clients participate in training in every communication round, and Federated Averaging (FedAvg) is the most popular algorithm in practice. Existing analyses of FedAvg usually assume the participating clients are independently sampled in each round from a uniform distribution, which does not reflect real-world scenarios. This paper introduces a theoretical framework that models client participation in FL as a Markov chain to study optimization convergence when clients have non-uniform and correlated participation across rounds. We apply this framework to analyze a more general and practical pattern: every client must wait a minimum number of $R$ rounds (minimum separation) before re-participating. We theoretically prove and empirically observe that increasing minimum separation reduces the bias induced by intrinsic non-uniformity of client availability in cross-device FL systems. Furthermore, we develop an effective debiasing algorithm for FedAvg that provably converges to the unbiased optimal solution under arbitrary minimum separation and unknown client availability distribution.
Efficient Online Unlearning via Hessian-Free Recollection of Individual Data Statistics
Apr 11, 2024Machine unlearning strives to uphold the data owners' right to be forgotten by enabling models to selectively forget specific data. Recent methods suggest that one approach of data forgetting is by precomputing and storing statistics carrying second-order information to improve computational and memory efficiency. However, they rely on restrictive assumptions and the computation/storage suffer from the curse of model parameter dimensionality, making it challenging to apply to most deep neural networks. In this work, we propose a Hessian-free online unlearning method. We propose to maintain a statistical vector for each data point, computed through affine stochastic recursion approximation of the difference between retrained and learned models. Our proposed algorithm achieves near-instantaneous online unlearning as it only requires a vector addition operation. Based on the strategy that recollecting statistics for forgetting data, the proposed method significantly reduces the unlearning runtime. Experimental studies demonstrate that the proposed scheme surpasses existing results by orders of magnitude in terms of time and memory costs, while also enhancing accuracy.
A Stochastic Quasi-Newton Method for Non-convex Optimization with Non-uniform Smoothness
Mar 22, 2024



Classical convergence analyses for optimization algorithms rely on the widely-adopted uniform smoothness assumption. However, recent experimental studies have demonstrated that many machine learning problems exhibit non-uniform smoothness, meaning the smoothness factor is a function of the model parameter instead of a universal constant. In particular, it has been observed that the smoothness grows with respect to the gradient norm along the training trajectory. Motivated by this phenomenon, the recently introduced $(L_0, L_1)$-smoothness is a more general notion, compared to traditional $L$-smoothness, that captures such positive relationship between smoothness and gradient norm. Under this type of non-uniform smoothness, existing literature has designed stochastic first-order algorithms by utilizing gradient clipping techniques to obtain the optimal $\mathcal{O}(\epsilon^{-3})$ sample complexity for finding an $\epsilon$-approximate first-order stationary solution. Nevertheless, the studies of quasi-Newton methods are still lacking. Considering higher accuracy and more robustness for quasi-Newton methods, in this paper we propose a fast stochastic quasi-Newton method when there exists non-uniformity in smoothness. Leveraging gradient clipping and variance reduction, our algorithm can achieve the best-known $\mathcal{O}(\epsilon^{-3})$ sample complexity and enjoys convergence speedup with simple hyperparameter tuning. Our numerical experiments show that our proposed algorithm outperforms the state-of-the-art approaches.
Understanding Generalization of Federated Learning via Stability: Heterogeneity Matters
Jun 06, 2023Generalization performance is a key metric in evaluating machine learning models when applied to real-world applications. Good generalization indicates the model can predict unseen data correctly when trained under a limited number of data. Federated learning (FL), which has emerged as a popular distributed learning framework, allows multiple devices or clients to train a shared model without violating privacy requirements. While the existing literature has studied extensively the generalization performances of centralized machine learning algorithms, similar analysis in the federated settings is either absent or with very restrictive assumptions on the loss functions. In this paper, we aim to analyze the generalization performances of federated learning by means of algorithmic stability, which measures the change of the output model of an algorithm when perturbing one data point. Three widely-used algorithms are studied, including FedAvg, SCAFFOLD, and FedProx, under convex and non-convex loss functions. Our analysis shows that the generalization performances of models trained by these three algorithms are closely related to the heterogeneity of clients' datasets as well as the convergence behaviors of the algorithms. Particularly, in the i.i.d. setting, our results recover the classical results of stochastic gradient descent (SGD).
Collaborative Multi-Agent Video Fast-Forwarding
May 27, 2023Multi-agent applications have recently gained significant popularity. In many computer vision tasks, a network of agents, such as a team of robots with cameras, could work collaboratively to perceive the environment for efficient and accurate situation awareness. However, these agents often have limited computation, communication, and storage resources. Thus, reducing resource consumption while still providing an accurate perception of the environment becomes an important goal when deploying multi-agent systems. To achieve this goal, we identify and leverage the overlap among different camera views in multi-agent systems for reducing the processing, transmission and storage of redundant/unimportant video frames. Specifically, we have developed two collaborative multi-agent video fast-forwarding frameworks in distributed and centralized settings, respectively. In these frameworks, each individual agent can selectively process or skip video frames at adjustable paces based on multiple strategies via reinforcement learning. Multiple agents then collaboratively sense the environment via either 1) a consensus-based distributed framework called DMVF that periodically updates the fast-forwarding strategies of agents by establishing communication and consensus among connected neighbors, or 2) a centralized framework called MFFNet that utilizes a central controller to decide the fast-forwarding strategies for agents based on collected data. We demonstrate the efficacy and efficiency of our proposed frameworks on a real-world surveillance video dataset VideoWeb and a new simulated driving dataset CarlaSim, through extensive simulations and deployment on an embedded platform with TCP communication. We show that compared with other approaches in the literature, our frameworks achieve better coverage of important frames, while significantly reducing the number of frames processed at each agent.
Attrition-Aware Adaptation for Multi-Agent Patrolling
Apr 03, 2023Multi-agent patrolling is a key problem in a variety of domains such as intrusion detection, area surveillance, and policing which involves repeated visits by a group of agents to specified points in an environment. While the problem is well-studied, most works either do not consider agent attrition or impose significant communication requirements to enable adaptation. In this work, we present the Adaptive Heuristic-based Patrolling Algorithm, which is capable of adaptation to agent loss using minimal communication by taking advantage of Voronoi partitioning. Additionally, we provide new centralized and distributed mathematical programming formulations of the patrolling problem, analyze the properties of Voronoi partitioning, and show the value of our adaptive heuristic algorithm by comparison with various benchmark algorithms using a realistic simulation environment based on the Robot Operating System (ROS) 2.
A Communication-efficient Algorithm with Linear Convergence for Federated Minimax Learning
Jun 02, 2022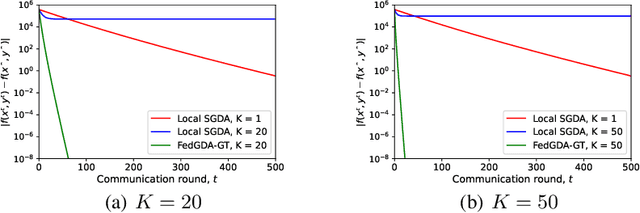
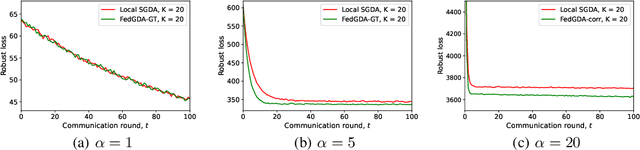
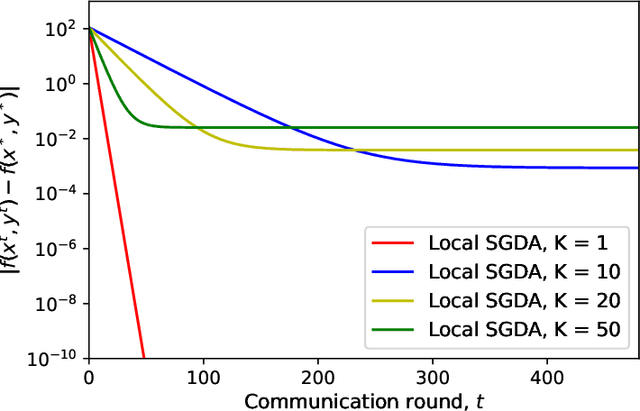
In this paper, we study a large-scale multi-agent minimax optimization problem, which models many interesting applications in statistical learning and game theory, including Generative Adversarial Networks (GANs). The overall objective is a sum of agents' private local objective functions. We first analyze an important special case, empirical minimax problem, where the overall objective approximates a true population minimax risk by statistical samples. We provide generalization bounds for learning with this objective through Rademacher complexity analysis. Then, we focus on the federated setting, where agents can perform local computation and communicate with a central server. Most existing federated minimax algorithms either require communication per iteration or lack performance guarantees with the exception of Local Stochastic Gradient Descent Ascent (SGDA), a multiple-local-update descent ascent algorithm which guarantees convergence under a diminishing stepsize. By analyzing Local SGDA under the ideal condition of no gradient noise, we show that generally it cannot guarantee exact convergence with constant stepsizes and thus suffers from slow rates of convergence. To tackle this issue, we propose FedGDA-GT, an improved Federated (Fed) Gradient Descent Ascent (GDA) method based on Gradient Tracking (GT). When local objectives are Lipschitz smooth and strongly-convex-strongly-concave, we prove that FedGDA-GT converges linearly with a constant stepsize to global $\epsilon$-approximation solution with $\mathcal{O}(\log (1/\epsilon))$ rounds of communication, which matches the time complexity of centralized GDA method. Finally, we numerically show that FedGDA-GT outperforms Local SGDA.
Faithful Edge Federated Learning: Scalability and Privacy
Jun 30, 2021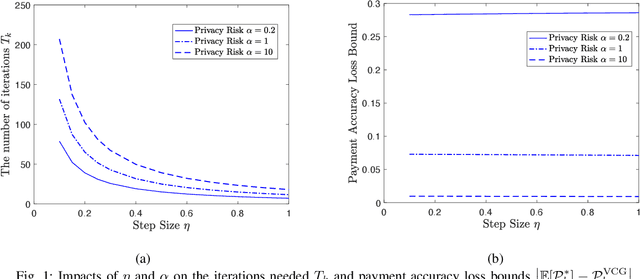
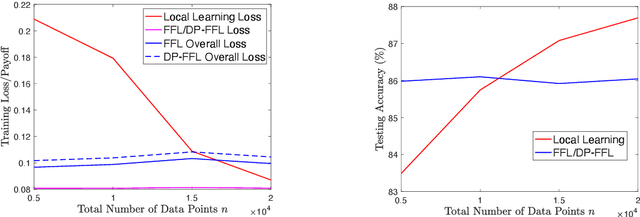
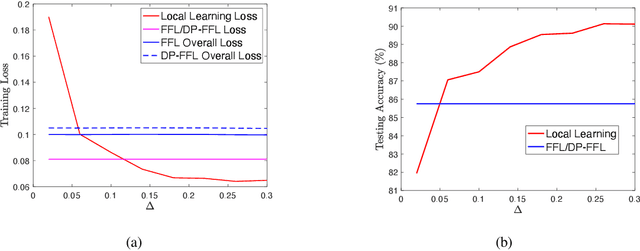
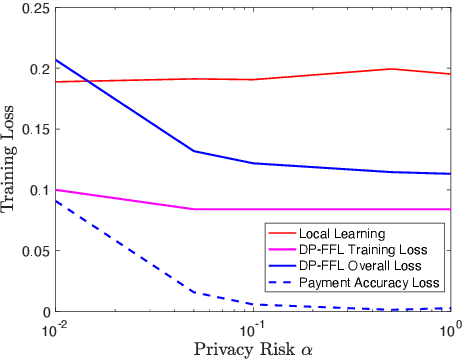
Federated learning enables machine learning algorithms to be trained over a network of multiple decentralized edge devices without requiring the exchange of local datasets. Successfully deploying federated learning requires ensuring that agents (e.g., mobile devices) faithfully execute the intended algorithm, which has been largely overlooked in the literature. In this study, we first use risk bounds to analyze how the key feature of federated learning, unbalanced and non-i.i.d. data, affects agents' incentives to voluntarily participate and obediently follow traditional federated learning algorithms. To be more specific, our analysis reveals that agents with less typical data distributions and relatively more samples are more likely to opt out of or tamper with federated learning algorithms. To this end, we formulate the first faithful implementation problem of federated learning and design two faithful federated learning mechanisms which satisfy economic properties, scalability, and privacy. Further, the time complexity of computing all agents' payments in the number of agents is $\mathcal{O}(1)$. First, we design a Faithful Federated Learning (FFL) mechanism which approximates the Vickrey-Clarke-Groves (VCG) payments via an incremental computation. We show that it achieves (probably approximate) optimality, faithful implementation, voluntary participation, and some other economic properties (such as budget balance). Second, by partitioning agents into several subsets, we present a scalable VCG mechanism approximation. We further design a scalable and Differentially Private FFL (DP-FFL) mechanism, the first differentially private faithful mechanism, that maintains the economic properties. Our mechanism enables one to make three-way performance tradeoffs among privacy, the iterations needed, and payment accuracy loss.
Distributed Multi-agent Video Fast-forwarding
Aug 10, 2020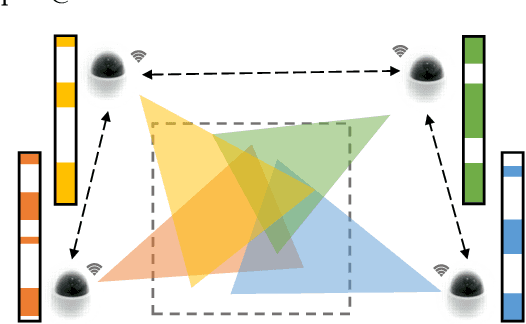

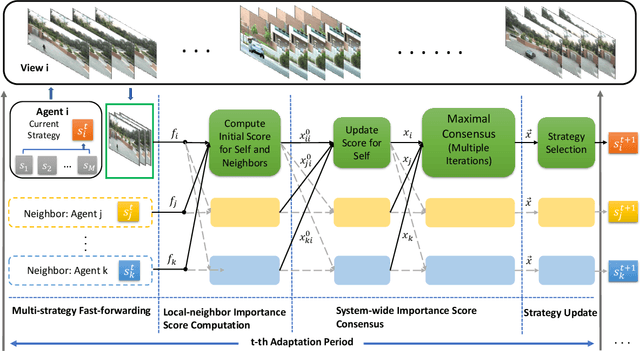
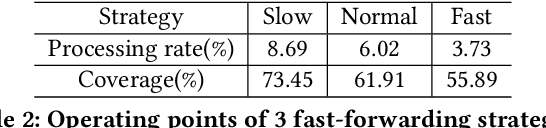
In many intelligent systems, a network of agents collaboratively perceives the environment for better and more efficient situation awareness. As these agents often have limited resources, it could be greatly beneficial to identify the content overlapping among camera views from different agents and leverage it for reducing the processing, transmission and storage of redundant/unimportant video frames. This paper presents a consensus-based distributed multi-agent video fast-forwarding framework, named DMVF, that fast-forwards multi-view video streams collaboratively and adaptively. In our framework, each camera view is addressed by a reinforcement learning based fast-forwarding agent, which periodically chooses from multiple strategies to selectively process video frames and transmits the selected frames at adjustable paces. During every adaptation period, each agent communicates with a number of neighboring agents, evaluates the importance of the selected frames from itself and those from its neighbors, refines such evaluation together with other agents via a system-wide consensus algorithm, and uses such evaluation to decide their strategy for the next period. Compared with approaches in the literature on a real-world surveillance video dataset VideoWeb, our method significantly improves the coverage of important frames and also reduces the number of frames processed in the system.