 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDD-LLM: Towards Accuracy Large Language Models for Major Depressive Disorder Diagnosis
Apr 28, 2025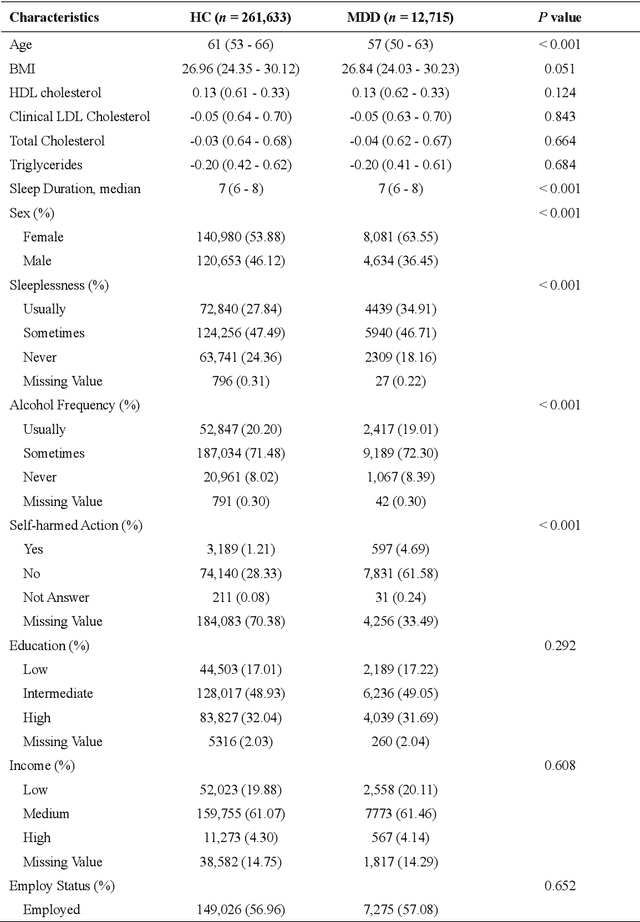
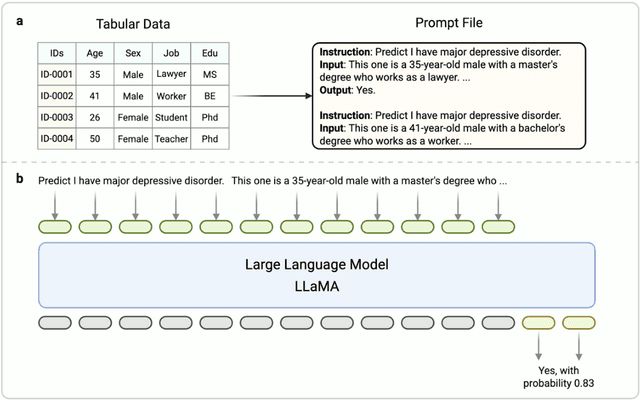

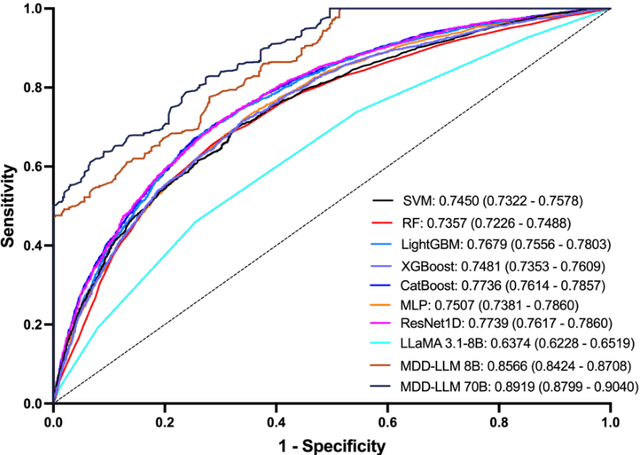
Major depressive disorder (MDD) impacts more than 300 million people worldwide, highlighting a significant public health issue. However, the uneven distribution of medical resources and the complexity of diagnostic methods have resulted in inadequate attention to this disorder in numerous countries and regions. This paper introduces a high-performance MDD diagnosis tool named MDD-LLM, an AI-driven framework that utilizes fine-tuned large language models (LLMs) and extensive real-world samples to tackle challenges in MDD diagnosis. Therefore, we select 274,348 individual information from the UK Biobank cohort to train and evaluate the proposed method. Specifically, we select 274,348 individual records from the UK Biobank cohort and design a tabular data transformation method to create a large corpus for training and evaluating the proposed approach. To illustrate the advantages of MDD-LLM, we perform comprehensive experiments and provide several comparative analyses against existing model-based solutions across multiple evaluation metrics. Experimental results show that MDD-LLM (70B) achieves an accuracy of 0.8378 and an AUC of 0.8919 (95% CI: 0.8799 - 0.9040), significantly outperforming existing machine learning and deep learning frameworks for MDD diagnosis. Given the limited exploration of LLMs in MDD diagnosis, we examine numerous factors that may influence the performance of our proposed method, such as tabular data transformation techniques and different fine-tuning strategies.
3D Virtual Garment Modeling from RGB Images
Jul 31, 2019

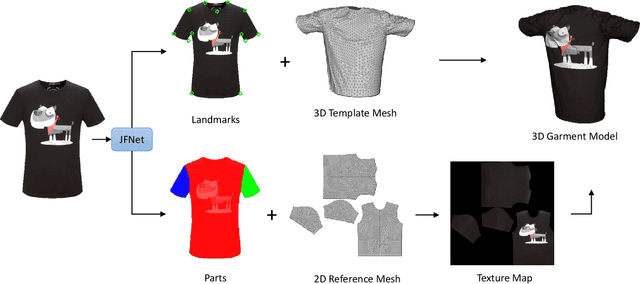

We present a novel approach that constructs 3D virtual garment models from photos. Unlike previous methods that require photos of a garment on a human model or a mannequin, our approach can work with various states of the garment: on a model, on a mannequin, or on a flat surface. To construct a complete 3D virtual model, our approach only requires two images as input, one front view and one back view. We first apply a multi-task learning network called JFNet that jointly predicts fashion landmarks and parses a garment image into semantic parts. The predicted landmarks are used for estimating sizing information of the garment. Then, a template garment mesh is deformed based on the sizing information to generate the final 3D model. The semantic parts are utilized for extracting color textures from input images. The results of our approach can be used in various Virtual Reality and Mixed Reality applications.
Ranking-Based Autoencoder for Extreme Multi-label Classification
Apr 11, 2019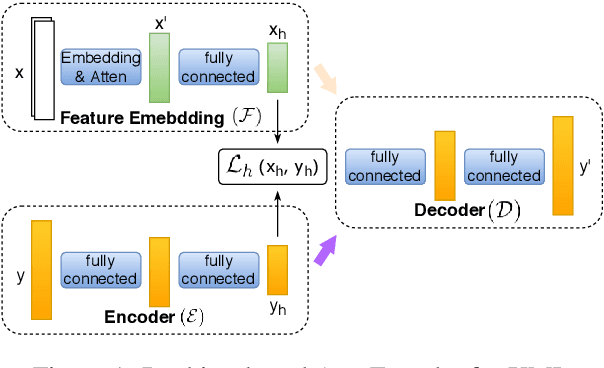
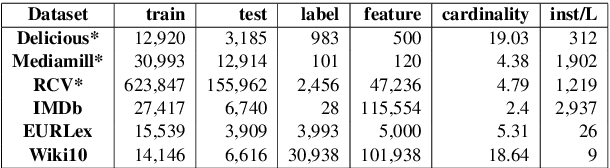
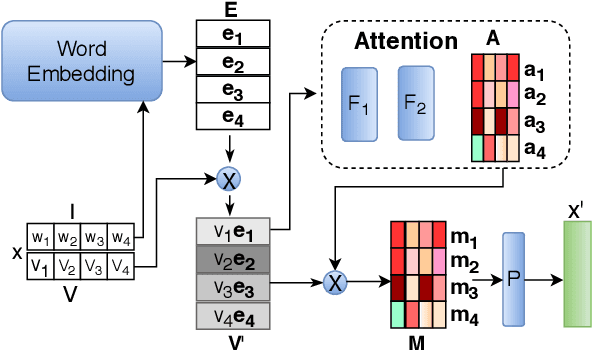
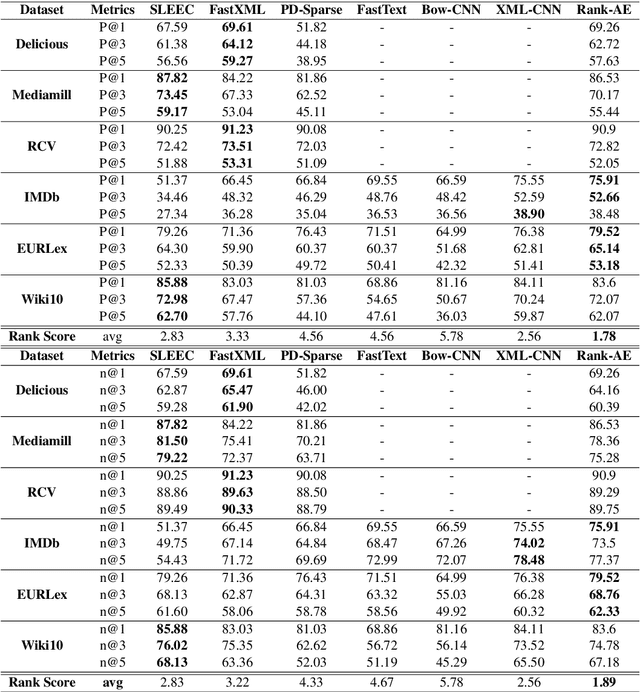
Extreme Multi-label classification (XML) is an important yet challenging machine learning task, that assigns to each instance its most relevant candidate labels from an extremely large label collection, where the numbers of labels, features and instances could be thousands or millions. XML is more and more on demand in the Internet industries, accompanied with the increasing business scale / scope and data accumulation. The extremely large label collections yield challenges such as computational complexity, inter-label dependency and noisy labeling. Many methods have been proposed to tackle these challenges, based on different mathematical formulations. In this paper, we propose a deep learning XML method, with a word-vector-based self-attention, followed by a ranking-based AutoEncoder architecture. The proposed method has three major advantages: 1) the autoencoder simultaneously considers the inter-label dependencies and the feature-label dependencies, by projecting labels and features onto a common embedding space; 2) the ranking loss not only improves the training efficiency and accuracy but also can be extended to handle noisy labeled data; 3) the efficient attention mechanism improves feature representation by highlighting feature importance. Experimental results on benchmark datasets show the proposed method is competitive to state-of-the-art methods.