 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRanking-Based Autoencoder for Extreme Multi-label Classification
Apr 11, 2019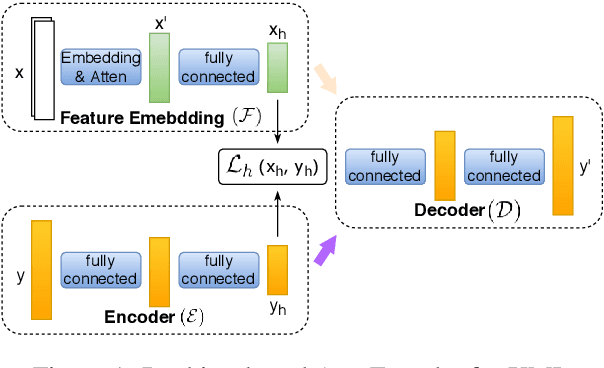
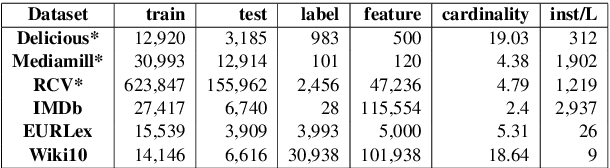
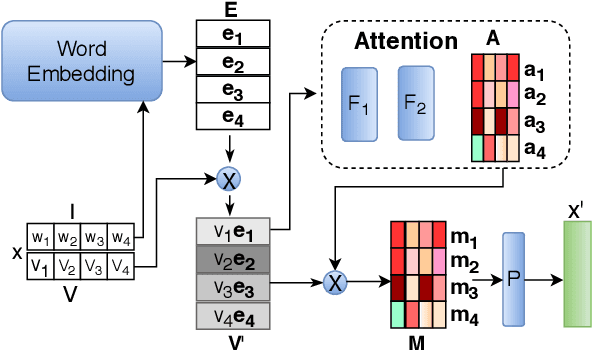
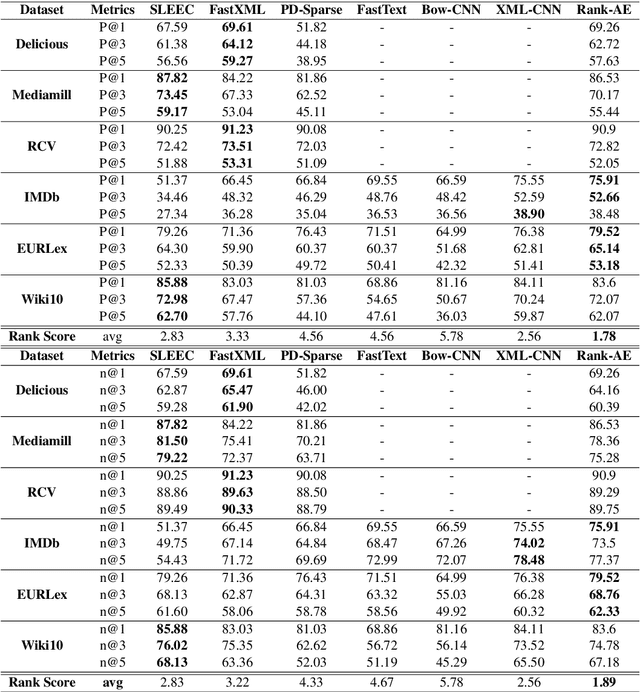
Extreme Multi-label classification (XML) is an important yet challenging machine learning task, that assigns to each instance its most relevant candidate labels from an extremely large label collection, where the numbers of labels, features and instances could be thousands or millions. XML is more and more on demand in the Internet industries, accompanied with the increasing business scale / scope and data accumulation. The extremely large label collections yield challenges such as computational complexity, inter-label dependency and noisy labeling. Many methods have been proposed to tackle these challenges, based on different mathematical formulations. In this paper, we propose a deep learning XML method, with a word-vector-based self-attention, followed by a ranking-based AutoEncoder architecture. The proposed method has three major advantages: 1) the autoencoder simultaneously considers the inter-label dependencies and the feature-label dependencies, by projecting labels and features onto a common embedding space; 2) the ranking loss not only improves the training efficiency and accuracy but also can be extended to handle noisy labeled data; 3) the efficient attention mechanism improves feature representation by highlighting feature importance. Experimental results on benchmark datasets show the proposed method is competitive to state-of-the-art methods.
Regularizing Model Complexity and Label Structure for Multi-Label Text Classification
May 01, 2017
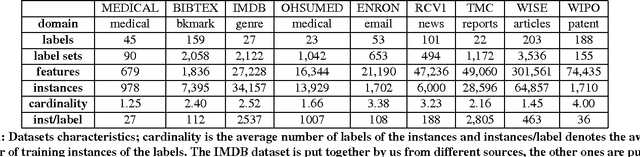
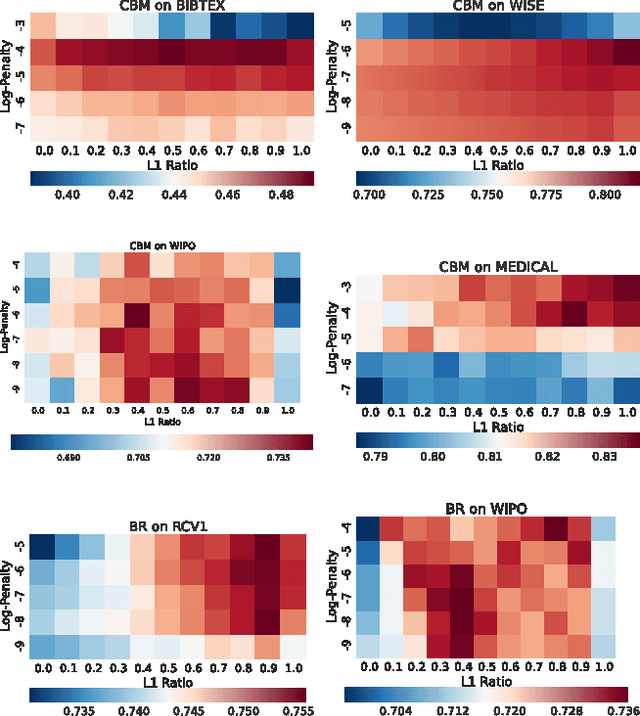
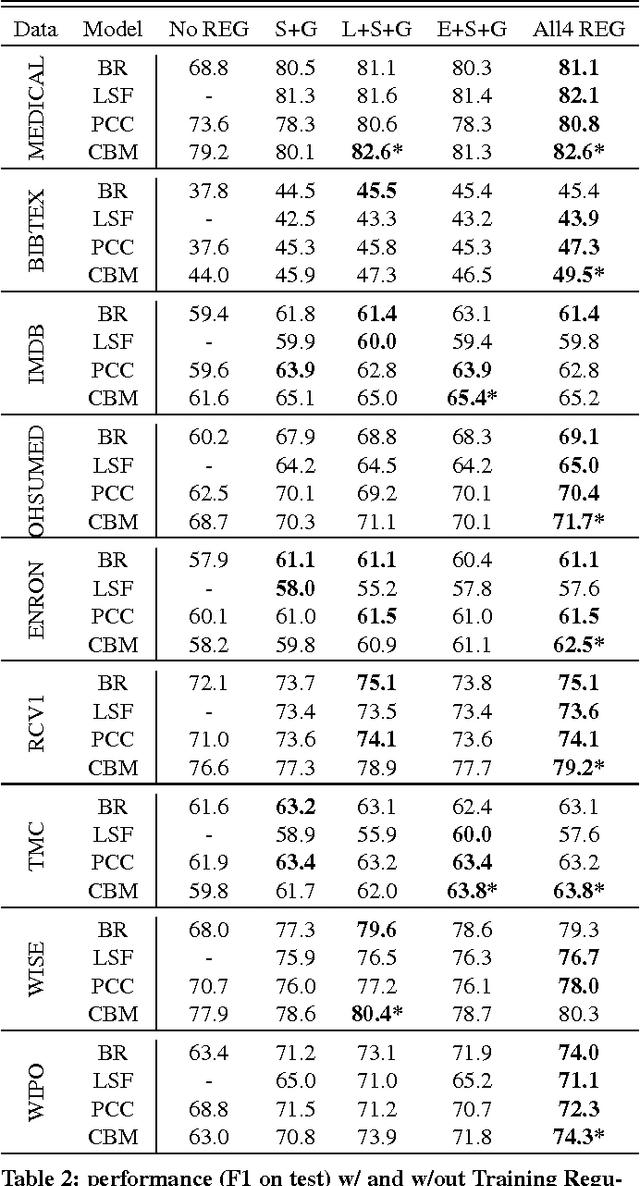
Multi-label text classification is a popular machine learning task where each document is assigned with multiple relevant labels. This task is challenging due to high dimensional features and correlated labels. Multi-label text classifiers need to be carefully regularized to prevent the severe over-fitting in the high dimensional space, and also need to take into account label dependencies in order to make accurate predictions under uncertainty. We demonstrate significant and practical improvement by carefully regularizing the model complexity during training phase, and also regularizing the label search space during prediction phase. Specifically, we regularize the classifier training using Elastic-net (L1+L2) penalty for reducing model complexity/size, and employ early stopping to prevent overfitting. At prediction time, we apply support inference to restrict the search space to label sets encountered in the training set, and F-optimizer GFM to make optimal predictions for the F1 metric. We show that although support inference only provides density estimations on existing label combinations, when combined with GFM predictor, the algorithm can output unseen label combinations. Taken collectively, our experiments show state of the art results on many benchmark datasets. Beyond performance and practical contributions, we make some interesting observations. Contrary to the prior belief, which deems support inference as purely an approximate inference procedure, we show that support inference acts as a strong regularizer on the label prediction structure. It allows the classifier to take into account label dependencies during prediction even if the classifiers had not modeled any label dependencies during training.