 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Learning in the Presence of Noise: Application in ICD-10 Code Classification
Mar 13, 2021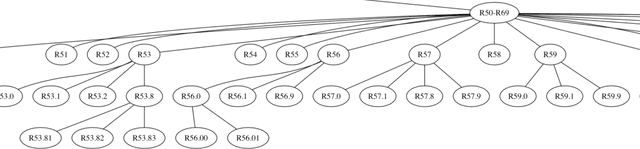

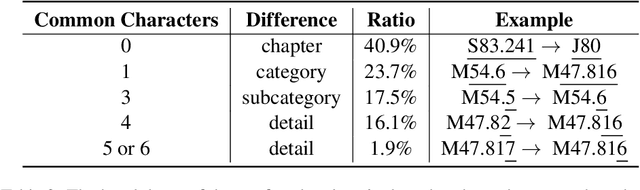
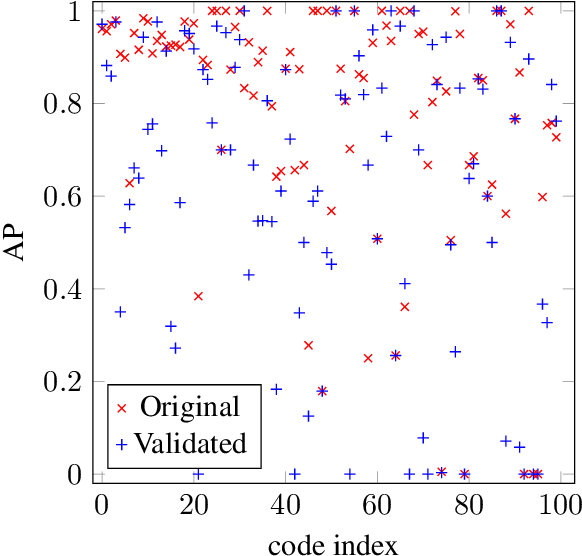
ICD coding is the international standard for capturing and reporting health conditions and diagnosis for revenue cycle management in healthcare. Manually assigning ICD codes is prone to human error due to the large code vocabulary and the similarities between codes. Since machine learning based approaches require ground truth training data, the inconsistency among human coders is manifested as noise in labeling, which makes the training and evaluation of ICD classifiers difficult in presence of such noise. This paper investigates the characteristics of such noise in manually-assigned ICD-10 codes and furthermore, proposes a method to train robust ICD-10 classifiers in the presence of labeling noise. Our research concluded that the nature of such noise is systematic. Most of the existing methods for handling label noise assume that the noise is completely random and independent of features or labels, which is not the case for ICD data. Therefore, we develop a new method for training robust classifiers in the presence of systematic noise. We first identify ICD-10 codes that human coders tend to misuse or confuse, based on the codes' locations in the ICD-10 hierarchy, the types of the codes, and baseline classifier's prediction behaviors; we then develop a novel training strategy that accounts for such noise. We compared our method with the baseline that does not handle label noise and the baseline methods that assume random noise, and demonstrated that our proposed method outperforms all baselines when evaluated on expert validated labels.
From Extreme Multi-label to Multi-class: A Hierarchical Approach for Automated ICD-10 Coding Using Phrase-level Attention
Feb 18, 2021



Clinical coding is the task of assigning a set of alphanumeric codes, referred to as ICD (International Classification of Diseases), to a medical event based on the context captured in a clinical narrative. The latest version of ICD, ICD-10, includes more than 70,000 codes. As this is a labor-intensive and error-prone task, automatic ICD coding of medical reports using machine learning has gained significant interest in the last decade. Existing literature has modeled this problem as a multi-label task. Nevertheless, such multi-label approach is challenging due to the extremely large label set size. Furthermore, the interpretability of the predictions is essential for the endusers (e.g., healthcare providers and insurance companies). In this paper, we propose a novel approach for automatic ICD coding by reformulating the extreme multi-label problem into a simpler multi-class problem using a hierarchical solution. We made this approach viable through extensive data collection to acquire phrase-level human coder annotations to supervise our models on learning the specific relations between the input text and predicted ICD codes. Our approach employs two independently trained networks, the sentence tagger and the ICD classifier, stacked hierarchically to predict a codeset for a medical report. The sentence tagger identifies focus sentences containing a medical event or concept relevant to an ICD coding. Using a supervised attention mechanism, the ICD classifier then assigns each focus sentence with an ICD code. The proposed approach outperforms strong baselines by large margins of 23% in subset accuracy, 18% in micro-F1, and 15% in instance based F-1. With our proposed approach, interpretability is achieved not through implicitly learned attention scores but by attributing each prediction to a particular sentence and words selected by human coders.
An Ensemble Approach for Automatic Structuring of Radiology Reports
Oct 11, 2020
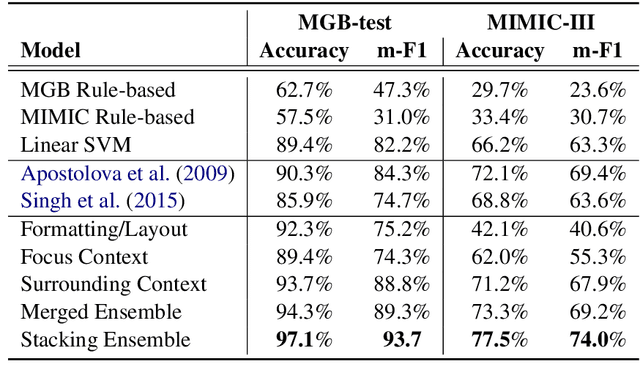
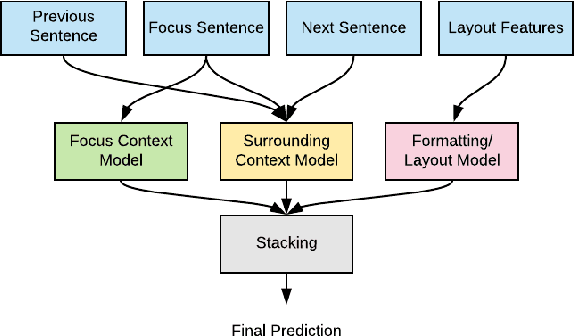

Automatic structuring of electronic medical records is of high demand for clinical workflow solutions to facilitate extraction, storage, and querying of patient care information. However, developing a scalable solution is extremely challenging, specifically for radiology reports, as most healthcare institutes use either no template or department/institute specific templates. Moreover, radiologists' reporting style varies from one to another as sentences are telegraphic and do not follow general English grammar rules. We present an ensemble method that consolidates the predictions of three models, capturing various attributes of textual information for automatic labeling of sentences with section labels. These three models are: 1) Focus Sentence model, capturing context of the target sentence; 2) Surrounding Context model, capturing the neighboring context of the target sentence; and finally, 3) Formatting/Layout model, aimed at learning report formatting cues. We utilize Bi-directional LSTMs, followed by sentence encoders, to acquire the context. Furthermore, we define several features that incorporate the structure of reports. We compare our proposed approach against multiple baselines and state-of-the-art approaches on a proprietary dataset as well as 100 manually annotated radiology notes from the MIMIC-III dataset, which we are making publicly available. Our proposed approach significantly outperforms other approaches by achieving 97.1% accuracy.
Pure-Exploration for Infinite-Armed Bandits with General Arm Reservoirs
Nov 15, 2018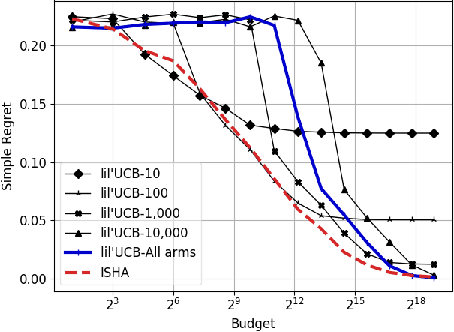
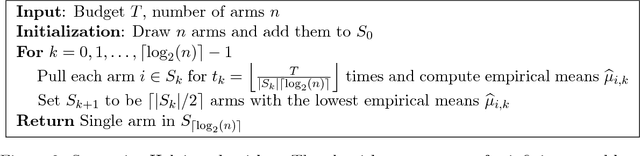
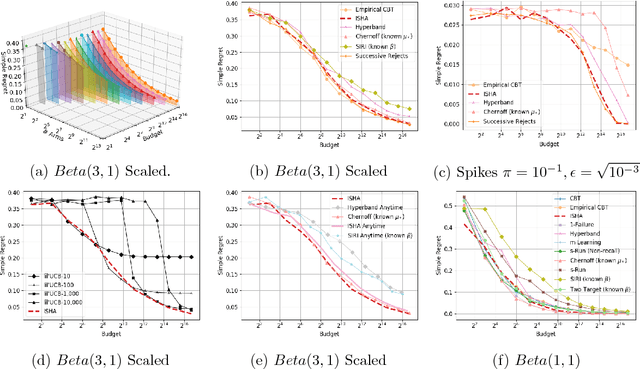
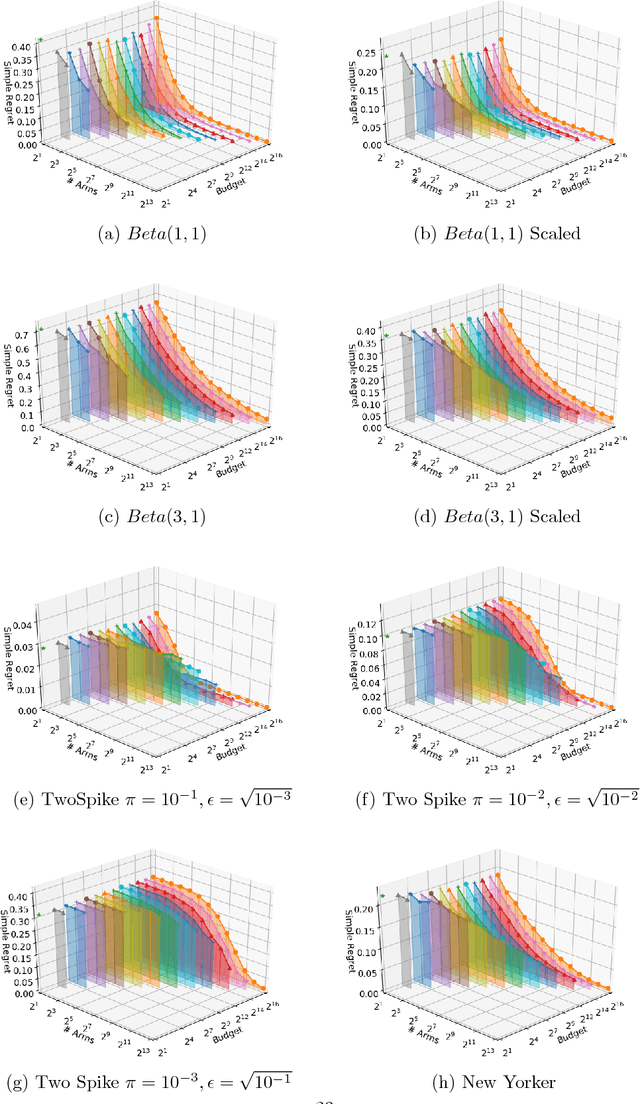
This paper considers a multi-armed bandit game where the number of arms is much larger than the maximum budget and is effectively infinite. We characterize necessary and sufficient conditions on the total budget for an algorithm to return an {\epsilon}-good arm with probability at least 1 - {\delta}. In such situations, the sample complexity depends on {\epsilon}, {\delta} and the so-called reservoir distribution {\nu} from which the means of the arms are drawn iid. While a substantial literature has developed around analyzing specific cases of {\nu} such as the beta distribution, our analysis makes no assumption about the form of {\nu}. Our algorithm is based on successive halving with the surprising exception that arms start to be discarded after just a single pull, requiring an analysis that goes beyond concentration alone. The provable correctness of this algorithm also provides an explanation for the empirical observation that the most aggressive bracket of the Hyperband algorithm of Li et al. (2017) for hyperparameter tuning is almost always best.
Adaptively Pruning Features for Boosted Decision Trees
May 19, 2018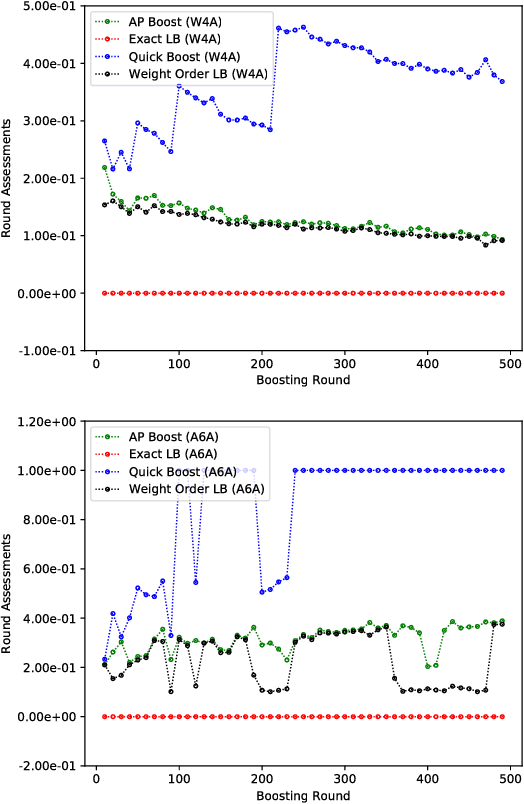

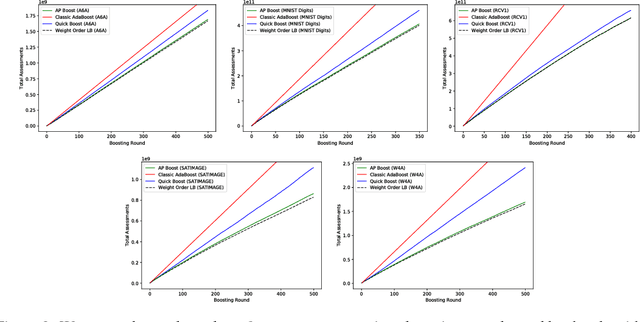

Boosted decision trees enjoy popularity in a variety of applications; however, for large-scale datasets, the cost of training a decision tree in each round can be prohibitively expensive. Inspired by ideas from the multi-arm bandit literature, we develop a highly efficient algorithm for computing exact greedy-optimal decision trees, outperforming the state-of-the-art Quick Boost method. We further develop a framework for deriving lower bounds on the problem that applies to a wide family of conceivable algorithms for the task (including our algorithm and Quick Boost), and we demonstrate empirically on a wide variety of data sets that our algorithm is near-optimal within this family of algorithms. We also derive a lower bound applicable to any algorithm solving the task, and we demonstrate that our algorithm empirically achieves performance close to this best-achievable lower bound.
Pure Exploration in Infinitely-Armed Bandit Models with Fixed-Confidence
Mar 13, 2018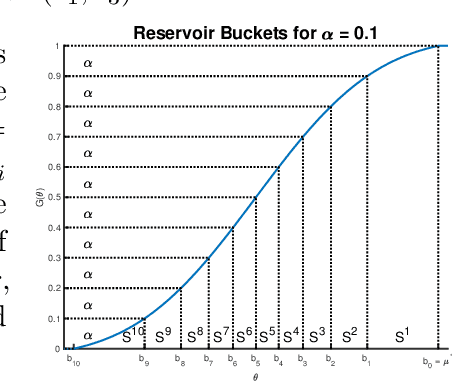
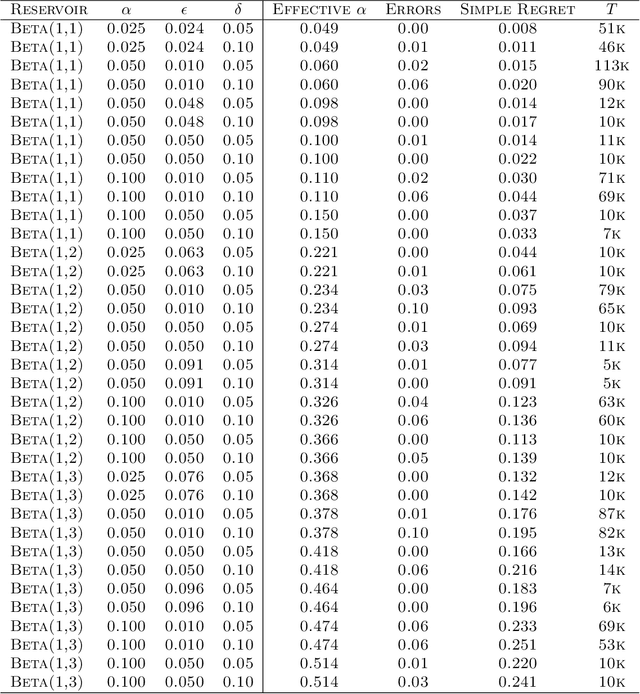
We consider the problem of near-optimal arm identification in the fixed confidence setting of the infinitely armed bandit problem when nothing is known about the arm reservoir distribution. We (1) introduce a PAC-like framework within which to derive and cast results; (2) derive a sample complexity lower bound for near-optimal arm identification; (3) propose an algorithm that identifies a nearly-optimal arm with high probability and derive an upper bound on its sample complexity which is within a log factor of our lower bound; and (4) discuss whether our log^2(1/delta) dependence is inescapable for "two-phase" (select arms first, identify the best later) algorithms in the infinite setting. This work permits the application of bandit models to a broader class of problems where fewer assumptions hold.
Measuring Human-perceived Similarity in Heterogeneous Collections
Feb 16, 2018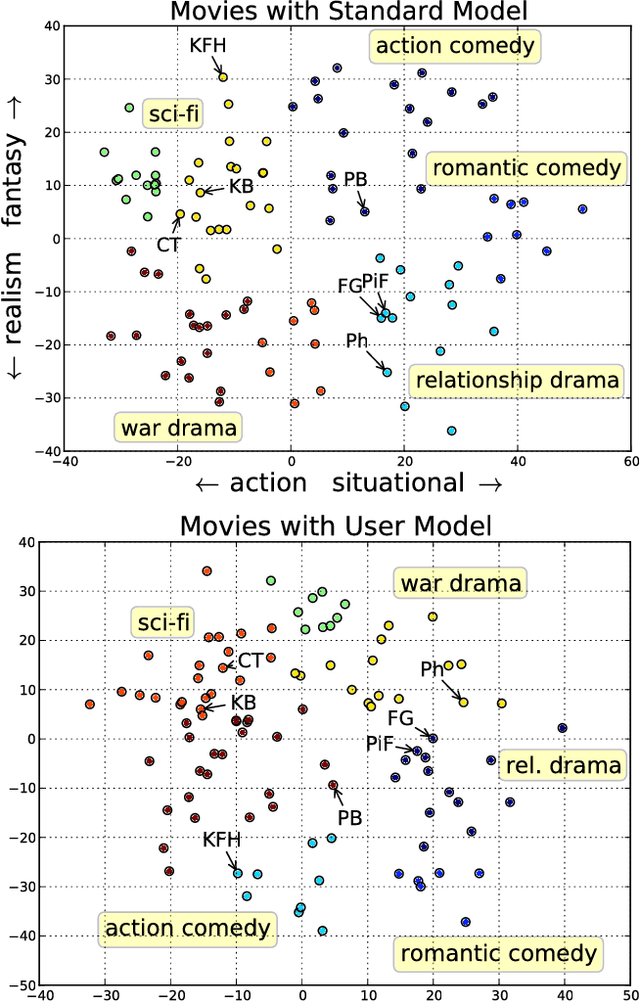


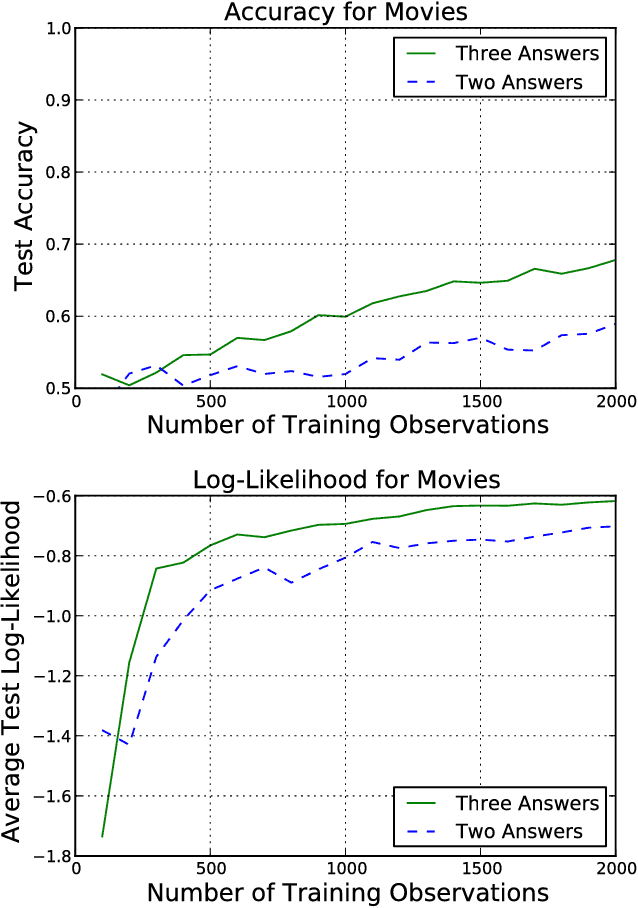
We present a technique for estimating the similarity between objects such as movies or foods whose proper representation depends on human perception. Our technique combines a modest number of human similarity assessments to infer a pairwise similarity function between the objects. This similarity function captures some human notion of similarity which may be difficult or impossible to automatically extract, such as which movie from a collection would be a better substitute when the desired one is unavailable. In contrast to prior techniques, our method does not assume that all similarity questions on the collection can be answered or that all users perceive similarity in the same way. When combined with a user model, we find how each assessor's tastes vary, affecting their perception of similarity.
Regularizing Model Complexity and Label Structure for Multi-Label Text Classification
May 01, 2017
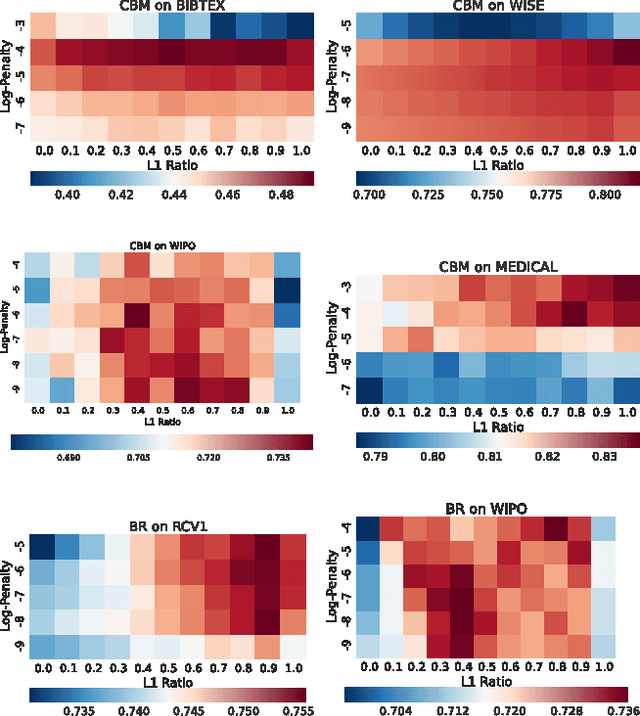
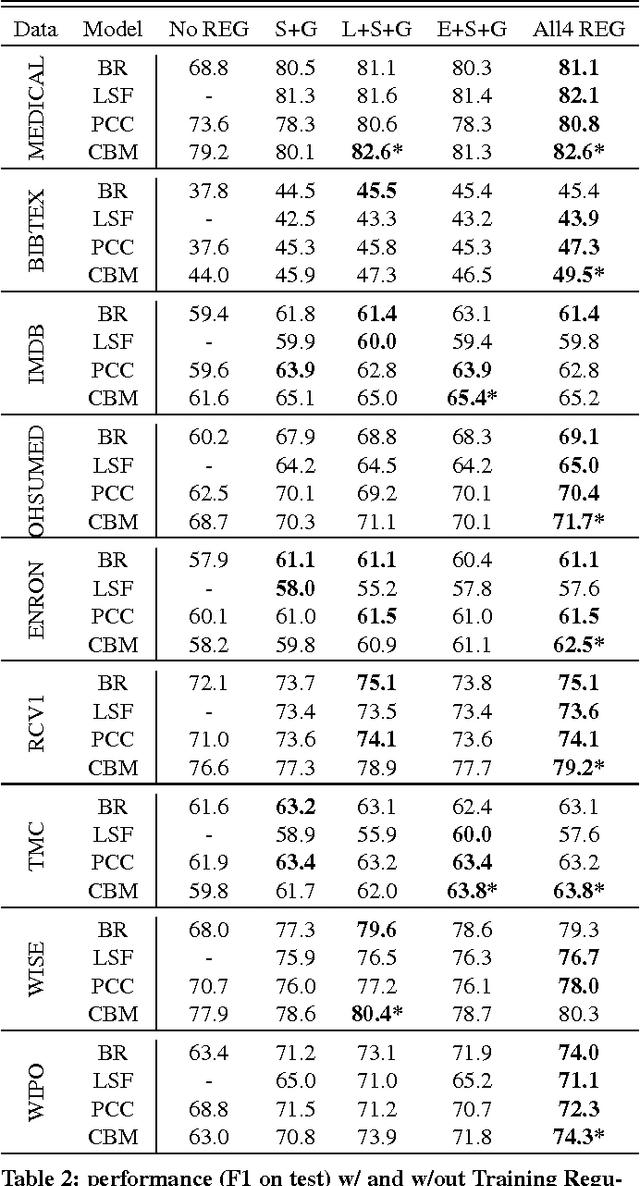
Multi-label text classification is a popular machine learning task where each document is assigned with multiple relevant labels. This task is challenging due to high dimensional features and correlated labels. Multi-label text classifiers need to be carefully regularized to prevent the severe over-fitting in the high dimensional space, and also need to take into account label dependencies in order to make accurate predictions under uncertainty. We demonstrate significant and practical improvement by carefully regularizing the model complexity during training phase, and also regularizing the label search space during prediction phase. Specifically, we regularize the classifier training using Elastic-net (L1+L2) penalty for reducing model complexity/size, and employ early stopping to prevent overfitting. At prediction time, we apply support inference to restrict the search space to label sets encountered in the training set, and F-optimizer GFM to make optimal predictions for the F1 metric. We show that although support inference only provides density estimations on existing label combinations, when combined with GFM predictor, the algorithm can output unseen label combinations. Taken collectively, our experiments show state of the art results on many benchmark datasets. Beyond performance and practical contributions, we make some interesting observations. Contrary to the prior belief, which deems support inference as purely an approximate inference procedure, we show that support inference acts as a strong regularizer on the label prediction structure. It allows the classifier to take into account label dependencies during prediction even if the classifiers had not modeled any label dependencies during training.
Optimal Tourist Problem and Anytime Planning of Trip Itineraries
Oct 08, 2014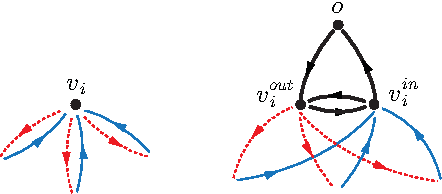
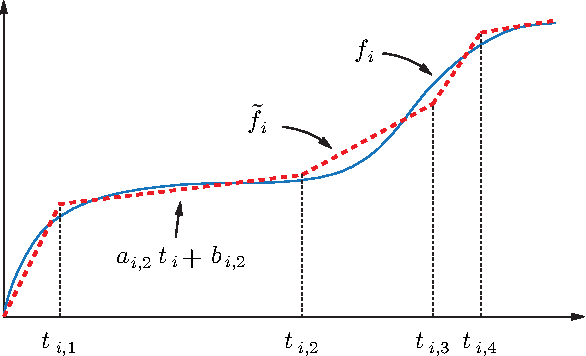
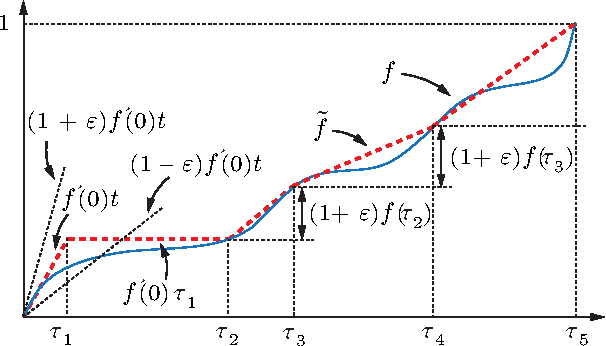
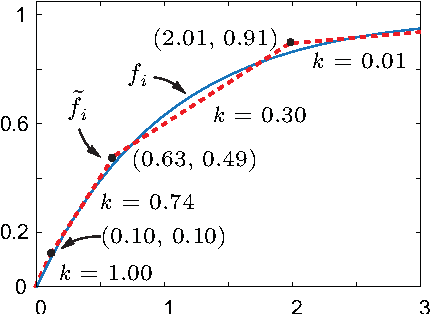
We introduce and study the problem in which a mobile sensing robot (our tourist) is tasked to travel among and gather intelligence at a set of spatially distributed point-of-interests (POIs). The quality of the information collected at each POI is characterized by some non-decreasing reward function over the time spent at the POI. With limited time budget, the robot must balance between spending time traveling to POIs and spending time at POIs for information collection (sensing) so as to maximize the total reward. Alternatively, the robot may be required to acquire a minimum mount of reward and hopes to do so with the least amount of time. We propose a mixed integer programming (MIP) based anytime algorithm for solving these two NP-hard optimization problems to arbitrary precision. The effectiveness of our algorithm is demonstrated using an extensive set of computational experiments including the planning of a realistic itinerary for a first-time tourist in Istanbul.