 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Membership Inference Attacks
Feb 18, 2026Modern AI models are not static. They go through multiple updates in their lifecycles. Thus, exploiting the model dynamics to create stronger Membership Inference (MI) attacks and tighter privacy audits are timely questions. Though the literature empirically shows that using a sequence of model updates can increase the power of MI attacks, rigorous analysis of the `optimal' MI attacks is limited to static models with infinite samples. Hence, we develop an `optimal' MI attack, SeMI*, that uses the sequence of model updates to identify the presence of a target inserted at a certain update step. For the empirical mean computation, we derive the optimal power of SeMI*, while accessing a finite number of samples with or without privacy. Our results retrieve the existing asymptotic analysis. We observe that having access to the model sequence avoids the dilution of MI signals unlike the existing attacks on the final model, where the MI signal vanishes as training data accumulates. Furthermore, an adversary can use SeMI* to tune both the insertion time and the canary to yield tighter privacy audits. Finally, we conduct experiments across data distributions and models trained or fine-tuned with DP-SGD demonstrating that practical variants of SeMI* lead to tighter privacy audits than the baselines.
DP-SPRT: Differentially Private Sequential Probability Ratio Tests
Aug 08, 2025We revisit Wald's celebrated Sequential Probability Ratio Test for sequential tests of two simple hypotheses, under privacy constraints. We propose DP-SPRT, a wrapper that can be calibrated to achieve desired error probabilities and privacy constraints, addressing a significant gap in previous work. DP-SPRT relies on a private mechanism that processes a sequence of queries and stops after privately determining when the query results fall outside a predefined interval. This OutsideInterval mechanism improves upon naive composition of existing techniques like AboveThreshold, potentially benefiting other sequential algorithms. We prove generic upper bounds on the error and sample complexity of DP-SPRT that can accommodate various noise distributions based on the practitioner's privacy needs. We exemplify them in two settings: Laplace noise (pure Differential Privacy) and Gaussian noise (R\'enyi differential privacy). In the former setting, by providing a lower bound on the sample complexity of any $\epsilon$-DP test with prescribed type I and type II errors, we show that DP-SPRT is near optimal when both errors are small and the two hypotheses are close. Moreover, we conduct an experimental study revealing its good practical performance.
Constrained Pareto Set Identification with Bandit Feedback
Jun 09, 2025In this paper, we address the problem of identifying the Pareto Set under feasibility constraints in a multivariate bandit setting. Specifically, given a $K$-armed bandit with unknown means $\mu_1, \dots, \mu_K \in \mathbb{R}^d$, the goal is to identify the set of arms whose mean is not uniformly worse than that of another arm (i.e., not smaller for all objectives), while satisfying some known set of linear constraints, expressing, for example, some minimal performance on each objective. Our focus lies in fixed-confidence identification, for which we introduce an algorithm that significantly outperforms racing-like algorithms and the intuitive two-stage approach that first identifies feasible arms and then their Pareto Set. We further prove an information-theoretic lower bound on the sample complexity of any algorithm for constrained Pareto Set identification, showing that the sample complexity of our approach is near-optimal. Our theoretical results are supported by an extensive empirical evaluation on a series of benchmarks.
Pareto Set Identification With Posterior Sampling
Nov 07, 2024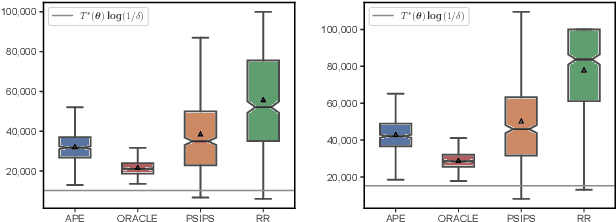

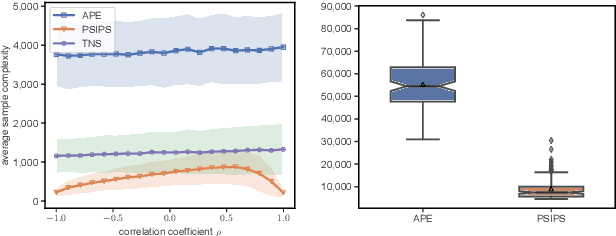

The problem of identifying the best answer among a collection of items having real-valued distribution is well-understood. Despite its practical relevance for many applications, fewer works have studied its extension when multiple and potentially conflicting metrics are available to assess an item's quality. Pareto set identification (PSI) aims to identify the set of answers whose means are not uniformly worse than another. This paper studies PSI in the transductive linear setting with potentially correlated objectives. Building on posterior sampling in both the stopping and the sampling rules, we propose the PSIPS algorithm that deals simultaneously with structure and correlation without paying the computational cost of existing oracle-based algorithms. Both from a frequentist and Bayesian perspective, PSIPS is asymptotically optimal. We demonstrate its good empirical performance in real-world and synthetic instances.
Best-Arm Identification in Unimodal Bandits
Nov 04, 2024We study the fixed-confidence best-arm identification problem in unimodal bandits, in which the means of the arms increase with the index of the arm up to their maximum, then decrease. We derive two lower bounds on the stopping time of any algorithm. The instance-dependent lower bound suggests that due to the unimodal structure, only three arms contribute to the leading confidence-dependent cost. However, a worst-case lower bound shows that a linear dependence on the number of arms is unavoidable in the confidence-independent cost. We propose modifications of Track-and-Stop and a Top Two algorithm that leverage the unimodal structure. Both versions of Track-and-Stop are asymptotically optimal for one-parameter exponential families. The Top Two algorithm is asymptotically near-optimal for Gaussian distributions and we prove a non-asymptotic guarantee matching the worse-case lower bound. The algorithms can be implemented efficiently and we demonstrate their competitive empirical performance.
Optimal Multi-Fidelity Best-Arm Identification
Jun 05, 2024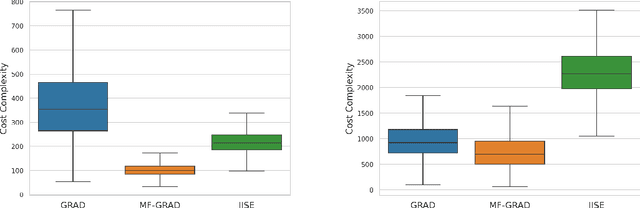

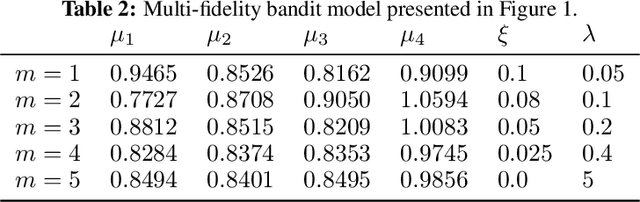
In bandit best-arm identification, an algorithm is tasked with finding the arm with highest mean reward with a specified accuracy as fast as possible. We study multi-fidelity best-arm identification, in which the algorithm can choose to sample an arm at a lower fidelity (less accurate mean estimate) for a lower cost. Several methods have been proposed for tackling this problem, but their optimality remain elusive, notably due to loose lower bounds on the total cost needed to identify the best arm. Our first contribution is a tight, instance-dependent lower bound on the cost complexity. The study of the optimization problem featured in the lower bound provides new insights to devise computationally efficient algorithms, and leads us to propose a gradient-based approach with asymptotically optimal cost complexity. We demonstrate the benefits of the new algorithm compared to existing methods in experiments. Our theoretical and empirical findings also shed light on an intriguing concept of optimal fidelity for each arm.
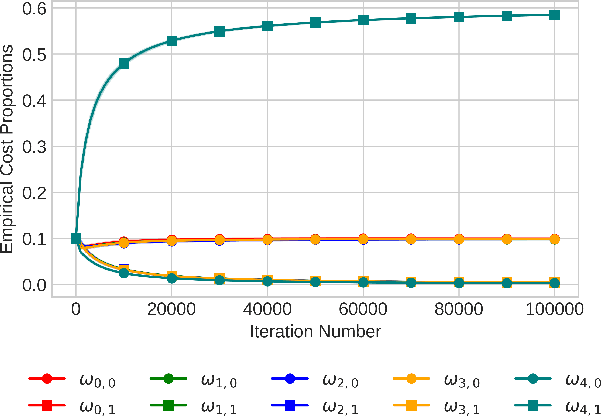
Power Mean Estimation in Stochastic Monte-Carlo Tree_Search
Jun 04, 2024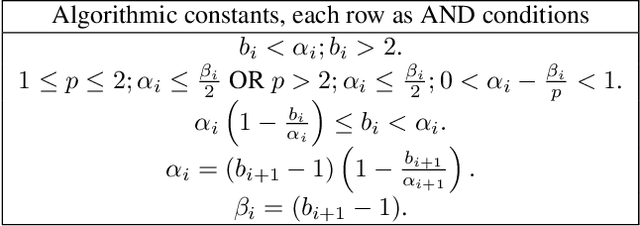
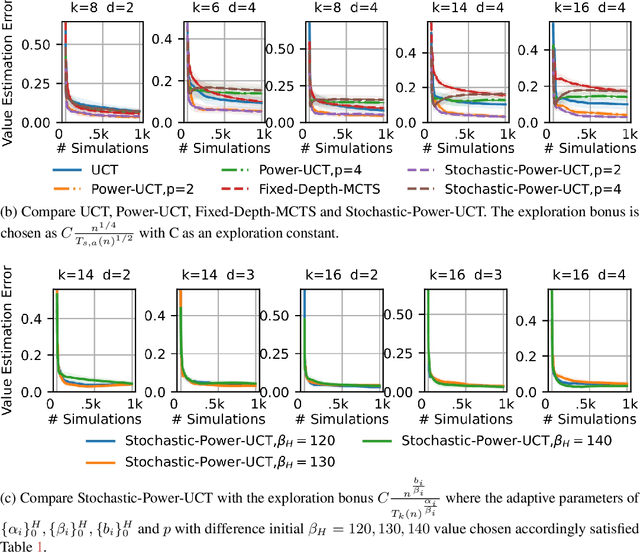
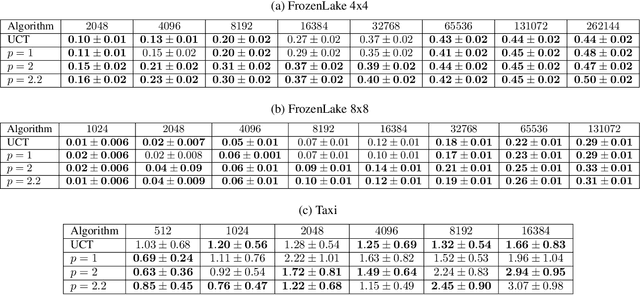
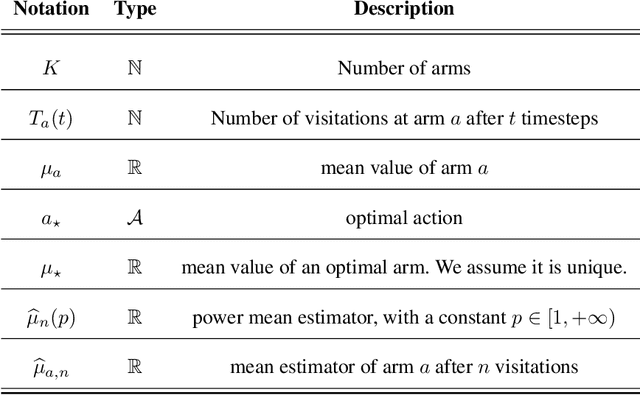
Monte-Carlo Tree Search (MCTS) is a widely-used strategy for online planning that combines Monte-Carlo sampling with forward tree search. Its success relies on the Upper Confidence bound for Trees (UCT) algorithm, an extension of the UCB method for multi-arm bandits. However, the theoretical foundation of UCT is incomplete due to an error in the logarithmic bonus term for action selection, leading to the development of Fixed-Depth-MCTS with a polynomial exploration bonus to balance exploration and exploitation~\citep{shah2022journal}. Both UCT and Fixed-Depth-MCTS suffer from biased value estimation: the weighted sum underestimates the optimal value, while the maximum valuation overestimates it~\citep{coulom2006efficient}. The power mean estimator offers a balanced solution, lying between the average and maximum values. Power-UCT~\citep{dam2019generalized} incorporates this estimator for more accurate value estimates but its theoretical analysis remains incomplete. This paper introduces Stochastic-Power-UCT, an MCTS algorithm using the power mean estimator and tailored for stochastic MDPs. We analyze its polynomial convergence in estimating root node values and show that it shares the same convergence rate of $\mathcal{O}(n^{-1/2})$, with $n$ is the number of visited trajectories, as Fixed-Depth-MCTS, with the latter being a special case of the former. Our theoretical results are validated with empirical tests across various stochastic MDP environments.
Finding good policies in average-reward Markov Decision Processes without prior knowledge
May 27, 2024We revisit the identification of an $\varepsilon$-optimal policy in average-reward Markov Decision Processes (MDP). In such MDPs, two measures of complexity have appeared in the literature: the diameter, $D$, and the optimal bias span, $H$, which satisfy $H\leq D$. Prior work have studied the complexity of $\varepsilon$-optimal policy identification only when a generative model is available. In this case, it is known that there exists an MDP with $D \simeq H$ for which the sample complexity to output an $\varepsilon$-optimal policy is $\Omega(SAD/\varepsilon^2)$ where $S$ and $A$ are the sizes of the state and action spaces. Recently, an algorithm with a sample complexity of order $SAH/\varepsilon^2$ has been proposed, but it requires the knowledge of $H$. We first show that the sample complexity required to estimate $H$ is not bounded by any function of $S,A$ and $H$, ruling out the possibility to easily make the previous algorithm agnostic to $H$. By relying instead on a diameter estimation procedure, we propose the first algorithm for $(\varepsilon,\delta)$-PAC policy identification that does not need any form of prior knowledge on the MDP. Its sample complexity scales in $SAD/\varepsilon^2$ in the regime of small $\varepsilon$, which is near-optimal. In the online setting, our first contribution is a lower bound which implies that a sample complexity polynomial in $H$ cannot be achieved in this setting. Then, we propose an online algorithm with a sample complexity in $SAD^2/\varepsilon^2$, as well as a novel approach based on a data-dependent stopping rule that we believe is promising to further reduce this bound.
Bandit Pareto Set Identification: the Fixed Budget Setting
Nov 07, 2023We study a multi-objective pure exploration problem in a multi-armed bandit model. Each arm is associated to an unknown multi-variate distribution and the goal is to identify the distributions whose mean is not uniformly worse than that of another distribution: the Pareto optimal set. We propose and analyze the first algorithms for the \emph{fixed budget} Pareto Set Identification task. We propose Empirical Gap Elimination, a family of algorithms combining a careful estimation of the ``hardness to classify'' each arm in or out of the Pareto set with a generic elimination scheme. We prove that two particular instances, EGE-SR and EGE-SH, have a probability of error that decays exponentially fast with the budget, with an exponent supported by an information theoretic lower-bound. We complement these findings with an empirical study using real-world and synthetic datasets, which showcase the good performance of our algorithms.
Towards Instance-Optimality in Online PAC Reinforcement Learning
Oct 31, 2023Several recent works have proposed instance-dependent upper bounds on the number of episodes needed to identify, with probability $1-\delta$, an $\varepsilon$-optimal policy in finite-horizon tabular Markov Decision Processes (MDPs). These upper bounds feature various complexity measures for the MDP, which are defined based on different notions of sub-optimality gaps. However, as of now, no lower bound has been established to assess the optimality of any of these complexity measures, except for the special case of MDPs with deterministic transitions. In this paper, we propose the first instance-dependent lower bound on the sample complexity required for the PAC identification of a near-optimal policy in any tabular episodic MDP. Additionally, we demonstrate that the sample complexity of the PEDEL algorithm of \cite{Wagenmaker22linearMDP} closely approaches this lower bound. Considering the intractability of PEDEL, we formulate an open question regarding the possibility of achieving our lower bound using a computationally-efficient algorithm.