 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning Small Language Models as Efficient Enterprise Search Relevance Labelers
Jan 06, 2026In enterprise search, building high-quality datasets at scale remains a central challenge due to the difficulty of acquiring labeled data. To resolve this challenge, we propose an efficient approach to fine-tune small language models (SLMs) for accurate relevance labeling, enabling high-throughput, domain-specific labeling comparable or even better in quality to that of state-of-the-art large language models (LLMs). To overcome the lack of high-quality and accessible datasets in the enterprise domain, our method leverages on synthetic data generation. Specifically, we employ an LLM to synthesize realistic enterprise queries from a seed document, apply BM25 to retrieve hard negatives, and use a teacher LLM to assign relevance scores. The resulting dataset is then distilled into an SLM, producing a compact relevance labeler. We evaluate our approach on a high-quality benchmark consisting of 923 enterprise query-document pairs annotated by trained human annotators, and show that the distilled SLM achieves agreement with human judgments on par with or better than the teacher LLM. Furthermore, our fine-tuned labeler substantially improves throughput, achieving 17 times increase while also being 19 times more cost-effective. This approach enables scalable and cost-effective relevance labeling for enterprise-scale retrieval applications, supporting rapid offline evaluation and iteration in real-world settings.
Leveraging User Behavior History for Personalized Email Search
Mar 17, 2021

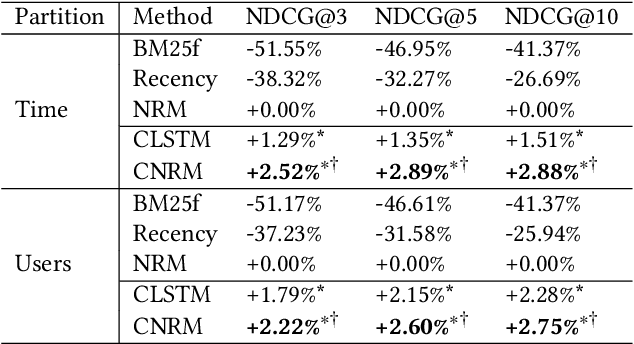

An effective email search engine can facilitate users' search tasks and improve their communication efficiency. Users could have varied preferences on various ranking signals of an email, such as relevance and recency based on their tasks at hand and even their jobs. Thus a uniform matching pattern is not optimal for all users. Instead, an effective email ranker should conduct personalized ranking by taking users' characteristics into account. Existing studies have explored user characteristics from various angles to make email search results personalized. However, little attention has been given to users' search history for characterizing users. Although users' historical behaviors have been shown to be beneficial as context in Web search, their effect in email search has not been studied and remains unknown. Given these observations, we propose to leverage user search history as query context to characterize users and build a context-aware ranking model for email search. In contrast to previous context-dependent ranking techniques that are based on raw texts, we use ranking features in the search history. This frees us from potential privacy leakage while giving a better generalization power to unseen users. Accordingly, we propose a context-dependent neural ranking model (CNRM) that encodes the ranking features in users' search history as query context and show that it can significantly outperform the baseline neural model without using the context. We also investigate the benefit of the query context vectors obtained from CNRM on the state-of-the-art learning-to-rank model LambdaMart by clustering the vectors and incorporating the cluster information. Experimental results show that significantly better results can be achieved on LambdaMart as well, indicating that the query clusters can characterize different users and effectively turn the ranking model personalized.
Measuring Human-perceived Similarity in Heterogeneous Collections
Feb 16, 2018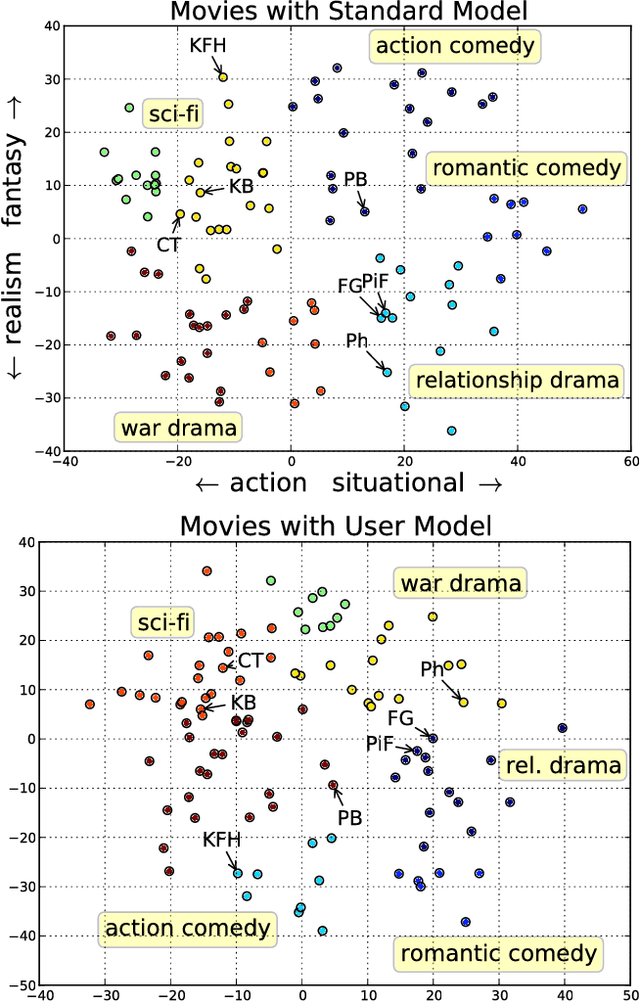


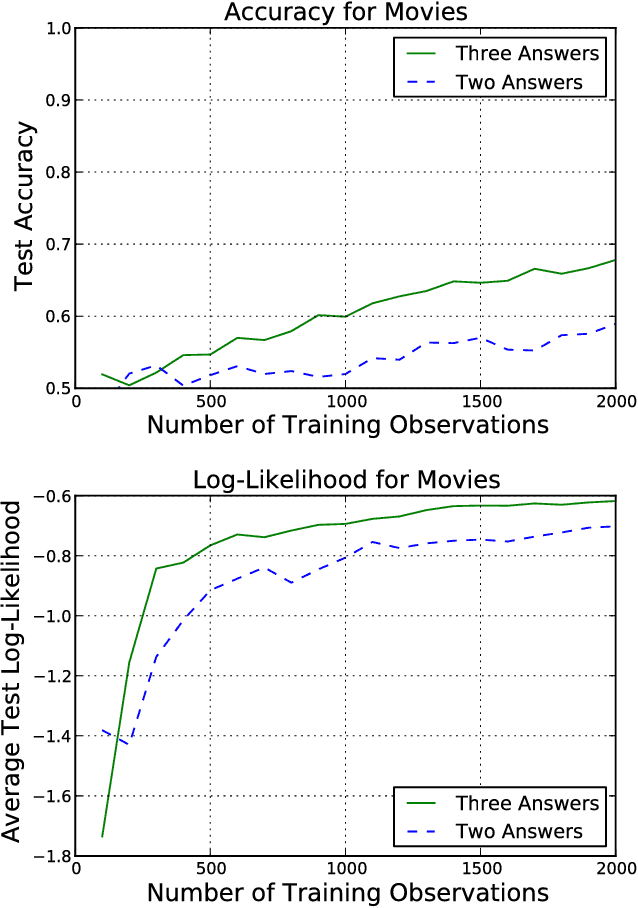
We present a technique for estimating the similarity between objects such as movies or foods whose proper representation depends on human perception. Our technique combines a modest number of human similarity assessments to infer a pairwise similarity function between the objects. This similarity function captures some human notion of similarity which may be difficult or impossible to automatically extract, such as which movie from a collection would be a better substitute when the desired one is unavailable. In contrast to prior techniques, our method does not assume that all similarity questions on the collection can be answered or that all users perceive similarity in the same way. When combined with a user model, we find how each assessor's tastes vary, affecting their perception of similarity.