 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking mBad! Supervised Fine-tuning for Cross-Lingual Detoxification
May 22, 2025As large language models (LLMs) become increasingly prevalent in global applications, ensuring that they are toxicity-free across diverse linguistic contexts remains a critical challenge. We explore "Cross-lingual Detoxification", a cross-lingual paradigm that mitigates toxicity, enabling detoxification capabilities to transfer between high and low-resource languages across different script families. We analyze cross-lingual detoxification's effectiveness through 504 extensive settings to evaluate toxicity reduction in cross-distribution settings with limited data and investigate how mitigation impacts model performance on non-toxic tasks, revealing trade-offs between safety and knowledge preservation. Our code and dataset are publicly available at https://github.com/himanshubeniwal/Breaking-mBad.
Beyond Factual Accuracy: Evaluating Coverage of Diverse Factual Information in Long-form Text Generation
Jan 07, 2025



This paper presents ICAT, an evaluation framework for measuring coverage of diverse factual information in long-form text generation. ICAT breaks down a long output text into a list of atomic claims and not only verifies each claim through retrieval from a (reliable) knowledge source, but also computes the alignment between the atomic factual claims and various aspects expected to be presented in the output. We study three implementations of the ICAT framework, each with a different assumption on the availability of aspects and alignment method. By adopting data from the diversification task in the TREC Web Track and the ClueWeb corpus, we evaluate the ICAT framework. We demonstrate strong correlation with human judgments and provide comprehensive evaluation across multiple state-of-the-art LLMs. Our framework further offers interpretable and fine-grained analysis of diversity and coverage. Its modular design allows for easy adaptation to different domains and datasets, making it a valuable tool for evaluating the qualitative aspects of long-form responses produced by LLMs.
Discovering Biases in Information Retrieval Models Using Relevance Thesaurus as Global Explanation
Oct 04, 2024



Most efforts in interpreting neural relevance models have focused on local explanations, which explain the relevance of a document to a query but are not useful in predicting the model's behavior on unseen query-document pairs. We propose a novel method to globally explain neural relevance models by constructing a "relevance thesaurus" containing semantically relevant query and document term pairs. This thesaurus is used to augment lexical matching models such as BM25 to approximate the neural model's predictions. Our method involves training a neural relevance model to score the relevance of partial query and document segments, which is then used to identify relevant terms across the vocabulary space. We evaluate the obtained thesaurus explanation based on ranking effectiveness and fidelity to the target neural ranking model. Notably, our thesaurus reveals the existence of brand name bias in ranking models, demonstrating one advantage of our explanation method.
Explaining Documents' Relevance to Search Queries
Nov 02, 2021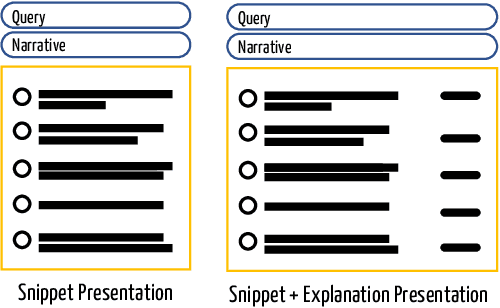

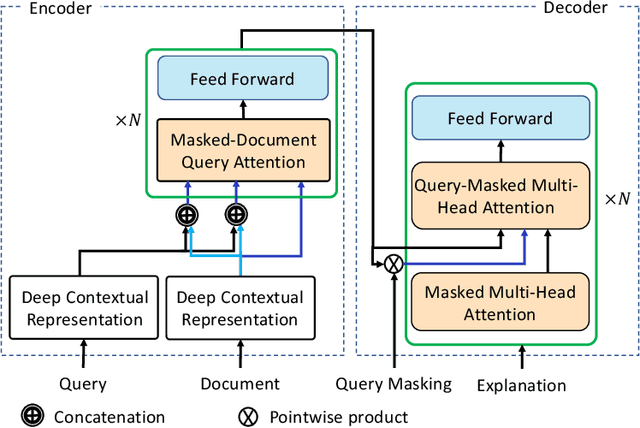
We present GenEx, a generative model to explain search results to users beyond just showing matches between query and document words. Adding GenEx explanations to search results greatly impacts user satisfaction and search performance. Search engines mostly provide document titles, URLs, and snippets for each result. Existing model-agnostic explanation methods similarly focus on word matching or content-based features. However, a recent user study shows that word matching features are quite obvious to users and thus of slight value. GenEx explains a search result by providing a terse description for the query aspect covered by that result. We cast the task as a sequence transduction problem and propose a novel model based on the Transformer architecture. To represent documents with respect to the given queries and yet not generate the queries themselves as explanations, two query-attention layers and masked-query decoding are added to the Transformer architecture. The model is trained without using any human-generated explanations. Training data are instead automatically constructed to ensure a tolerable noise level and a generalizable learned model. Experimental evaluation shows that our explanation models significantly outperform the baseline models. Evaluation through user studies also demonstrates that our explanation model generates short yet useful explanations.
Query-driven Segment Selection for Ranking Long Documents
Sep 10, 2021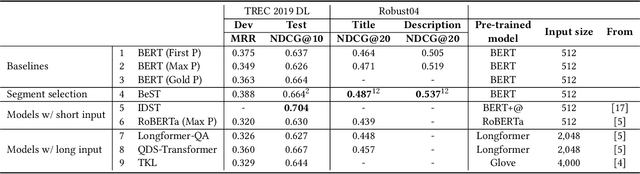
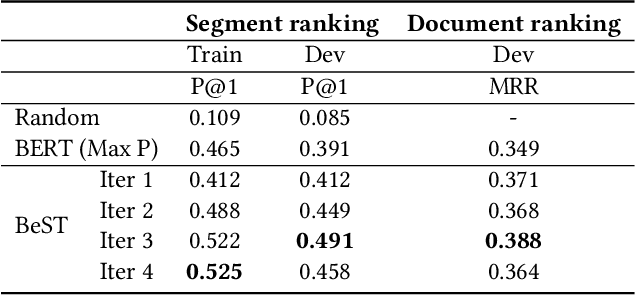
Transformer-based rankers have shown state-of-the-art performance. However, their self-attention operation is mostly unable to process long sequences. One of the common approaches to train these rankers is to heuristically select some segments of each document, such as the first segment, as training data. However, these segments may not contain the query-related parts of documents. To address this problem, we propose query-driven segment selection from long documents to build training data. The segment selector provides relevant samples with more accurate labels and non-relevant samples which are harder to be predicted. The experimental results show that the basic BERT-based ranker trained with the proposed segment selector significantly outperforms that trained by the heuristically selected segments, and performs equally to the state-of-the-art model with localized self-attention that can process longer input sequences. Our findings open up new direction to design efficient transformer-based rankers.
* 5 pages, 0 figure
Supervised Learning in the Presence of Noise: Application in ICD-10 Code Classification
Mar 13, 2021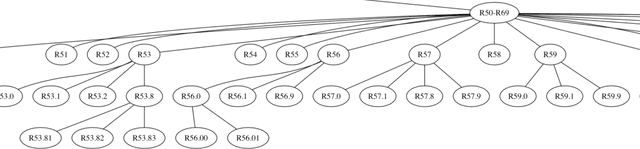

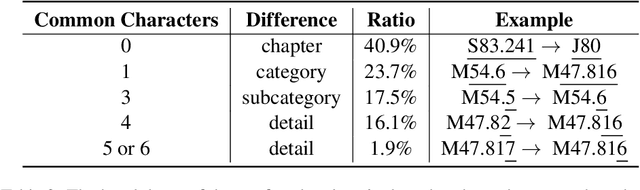
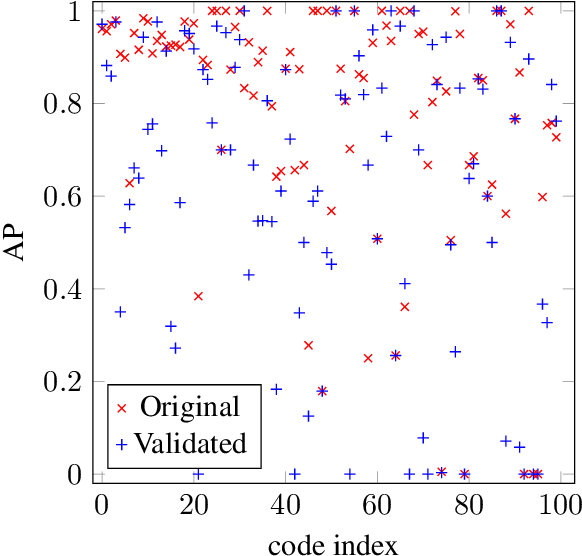
ICD coding is the international standard for capturing and reporting health conditions and diagnosis for revenue cycle management in healthcare. Manually assigning ICD codes is prone to human error due to the large code vocabulary and the similarities between codes. Since machine learning based approaches require ground truth training data, the inconsistency among human coders is manifested as noise in labeling, which makes the training and evaluation of ICD classifiers difficult in presence of such noise. This paper investigates the characteristics of such noise in manually-assigned ICD-10 codes and furthermore, proposes a method to train robust ICD-10 classifiers in the presence of labeling noise. Our research concluded that the nature of such noise is systematic. Most of the existing methods for handling label noise assume that the noise is completely random and independent of features or labels, which is not the case for ICD data. Therefore, we develop a new method for training robust classifiers in the presence of systematic noise. We first identify ICD-10 codes that human coders tend to misuse or confuse, based on the codes' locations in the ICD-10 hierarchy, the types of the codes, and baseline classifier's prediction behaviors; we then develop a novel training strategy that accounts for such noise. We compared our method with the baseline that does not handle label noise and the baseline methods that assume random noise, and demonstrated that our proposed method outperforms all baselines when evaluated on expert validated labels.