 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProof of Time: A Benchmark for Evaluating Scientific Idea Judgments
Jan 12, 2026Large language models are increasingly being used to assess and forecast research ideas, yet we lack scalable ways to evaluate the quality of models' judgments about these scientific ideas. Towards this goal, we introduce PoT, a semi-verifiable benchmarking framework that links scientific idea judgments to downstream signals that become observable later (e.g., citations and shifts in researchers' agendas). PoT freezes a pre-cutoff snapshot of evidence in an offline sandbox and asks models to forecast post-cutoff outcomes, enabling verifiable evaluation when ground truth arrives, scalable benchmarking without exhaustive expert annotation, and analysis of human-model misalignment against signals such as peer-review awards. In addition, PoT provides a controlled testbed for agent-based research judgments that evaluate scientific ideas, comparing tool-using agents to non-agent baselines under prompt ablations and budget scaling. Across 30,000+ instances spanning four benchmark domains, we find that, compared with non-agent baselines, higher interaction budgets generally improve agent performance, while the benefit of tool use is strongly task-dependent. By combining time-partitioned, future-verifiable targets with an offline sandbox for tool use, PoT supports scalable evaluation of agents on future-facing scientific idea judgment tasks.
Linguistically Conditioned Semantic Textual Similarity
Jun 06, 2024
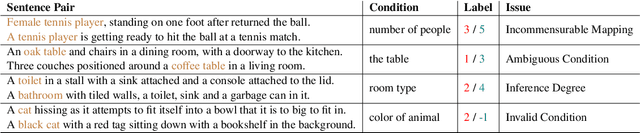
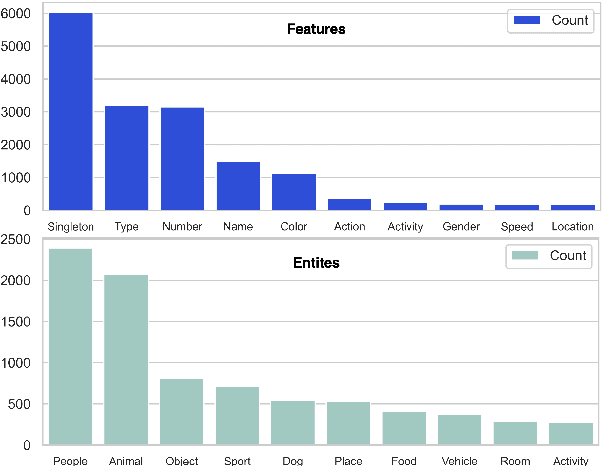

Semantic textual similarity (STS) is a fundamental NLP task that measures the semantic similarity between a pair of sentences. In order to reduce the inherent ambiguity posed from the sentences, a recent work called Conditional STS (C-STS) has been proposed to measure the sentences' similarity conditioned on a certain aspect. Despite the popularity of C-STS, we find that the current C-STS dataset suffers from various issues that could impede proper evaluation on this task. In this paper, we reannotate the C-STS validation set and observe an annotator discrepancy on 55% of the instances resulting from the annotation errors in the original label, ill-defined conditions, and the lack of clarity in the task definition. After a thorough dataset analysis, we improve the C-STS task by leveraging the models' capability to understand the conditions under a QA task setting. With the generated answers, we present an automatic error identification pipeline that is able to identify annotation errors from the C-STS data with over 80% F1 score. We also propose a new method that largely improves the performance over baselines on the C-STS data by training the models with the answers. Finally we discuss the conditionality annotation based on the typed-feature structure (TFS) of entity types. We show in examples that the TFS is able to provide a linguistic foundation for constructing C-STS data with new conditions.
Supervised Learning in the Presence of Noise: Application in ICD-10 Code Classification
Mar 13, 2021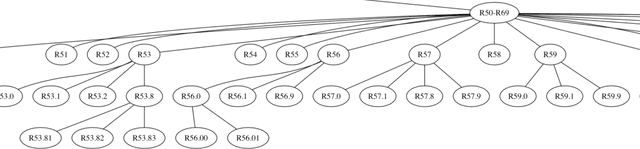

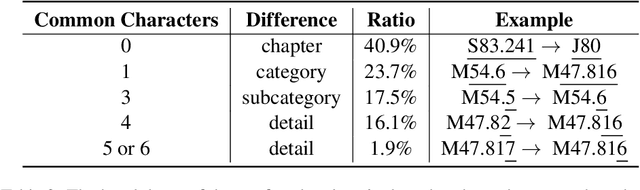
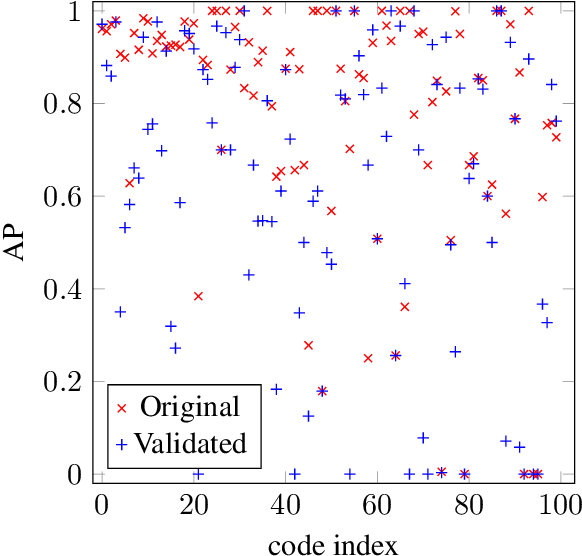
ICD coding is the international standard for capturing and reporting health conditions and diagnosis for revenue cycle management in healthcare. Manually assigning ICD codes is prone to human error due to the large code vocabulary and the similarities between codes. Since machine learning based approaches require ground truth training data, the inconsistency among human coders is manifested as noise in labeling, which makes the training and evaluation of ICD classifiers difficult in presence of such noise. This paper investigates the characteristics of such noise in manually-assigned ICD-10 codes and furthermore, proposes a method to train robust ICD-10 classifiers in the presence of labeling noise. Our research concluded that the nature of such noise is systematic. Most of the existing methods for handling label noise assume that the noise is completely random and independent of features or labels, which is not the case for ICD data. Therefore, we develop a new method for training robust classifiers in the presence of systematic noise. We first identify ICD-10 codes that human coders tend to misuse or confuse, based on the codes' locations in the ICD-10 hierarchy, the types of the codes, and baseline classifier's prediction behaviors; we then develop a novel training strategy that accounts for such noise. We compared our method with the baseline that does not handle label noise and the baseline methods that assume random noise, and demonstrated that our proposed method outperforms all baselines when evaluated on expert validated labels.
From Extreme Multi-label to Multi-class: A Hierarchical Approach for Automated ICD-10 Coding Using Phrase-level Attention
Feb 18, 2021



Clinical coding is the task of assigning a set of alphanumeric codes, referred to as ICD (International Classification of Diseases), to a medical event based on the context captured in a clinical narrative. The latest version of ICD, ICD-10, includes more than 70,000 codes. As this is a labor-intensive and error-prone task, automatic ICD coding of medical reports using machine learning has gained significant interest in the last decade. Existing literature has modeled this problem as a multi-label task. Nevertheless, such multi-label approach is challenging due to the extremely large label set size. Furthermore, the interpretability of the predictions is essential for the endusers (e.g., healthcare providers and insurance companies). In this paper, we propose a novel approach for automatic ICD coding by reformulating the extreme multi-label problem into a simpler multi-class problem using a hierarchical solution. We made this approach viable through extensive data collection to acquire phrase-level human coder annotations to supervise our models on learning the specific relations between the input text and predicted ICD codes. Our approach employs two independently trained networks, the sentence tagger and the ICD classifier, stacked hierarchically to predict a codeset for a medical report. The sentence tagger identifies focus sentences containing a medical event or concept relevant to an ICD coding. Using a supervised attention mechanism, the ICD classifier then assigns each focus sentence with an ICD code. The proposed approach outperforms strong baselines by large margins of 23% in subset accuracy, 18% in micro-F1, and 15% in instance based F-1. With our proposed approach, interpretability is achieved not through implicitly learned attention scores but by attributing each prediction to a particular sentence and words selected by human coders.
An Ensemble Approach for Automatic Structuring of Radiology Reports
Oct 11, 2020
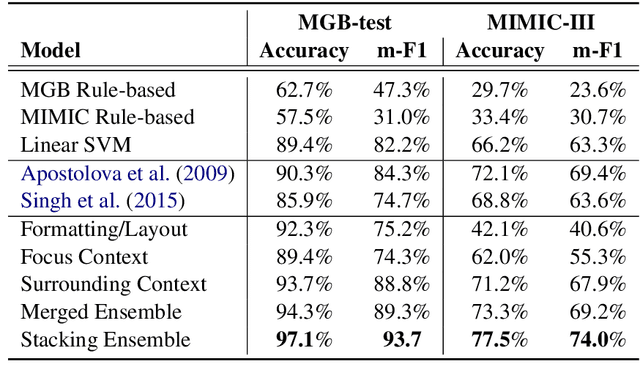
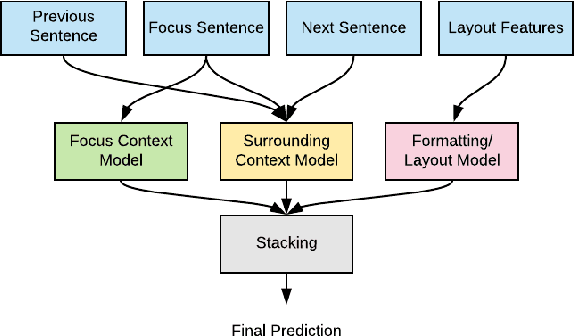

Automatic structuring of electronic medical records is of high demand for clinical workflow solutions to facilitate extraction, storage, and querying of patient care information. However, developing a scalable solution is extremely challenging, specifically for radiology reports, as most healthcare institutes use either no template or department/institute specific templates. Moreover, radiologists' reporting style varies from one to another as sentences are telegraphic and do not follow general English grammar rules. We present an ensemble method that consolidates the predictions of three models, capturing various attributes of textual information for automatic labeling of sentences with section labels. These three models are: 1) Focus Sentence model, capturing context of the target sentence; 2) Surrounding Context model, capturing the neighboring context of the target sentence; and finally, 3) Formatting/Layout model, aimed at learning report formatting cues. We utilize Bi-directional LSTMs, followed by sentence encoders, to acquire the context. Furthermore, we define several features that incorporate the structure of reports. We compare our proposed approach against multiple baselines and state-of-the-art approaches on a proprietary dataset as well as 100 manually annotated radiology notes from the MIMIC-III dataset, which we are making publicly available. Our proposed approach significantly outperforms other approaches by achieving 97.1% accuracy.