 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery-driven Segment Selection for Ranking Long Documents
Paper and Code
Sep 10, 2021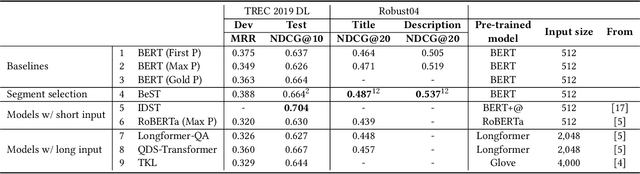
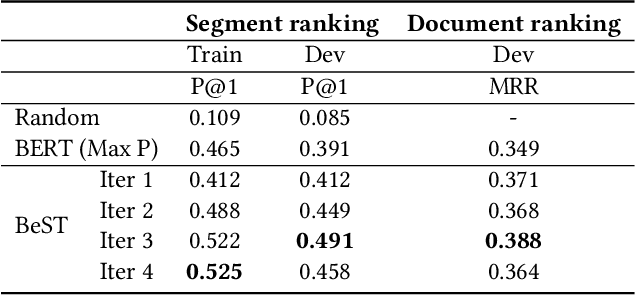
Transformer-based rankers have shown state-of-the-art performance. However, their self-attention operation is mostly unable to process long sequences. One of the common approaches to train these rankers is to heuristically select some segments of each document, such as the first segment, as training data. However, these segments may not contain the query-related parts of documents. To address this problem, we propose query-driven segment selection from long documents to build training data. The segment selector provides relevant samples with more accurate labels and non-relevant samples which are harder to be predicted. The experimental results show that the basic BERT-based ranker trained with the proposed segment selector significantly outperforms that trained by the heuristically selected segments, and performs equally to the state-of-the-art model with localized self-attention that can process longer input sequences. Our findings open up new direction to design efficient transformer-based rankers.