 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeVision: Detecting LLM-Generated Code Using 2D Token Probability Maps and Vision Models
Jan 06, 2025
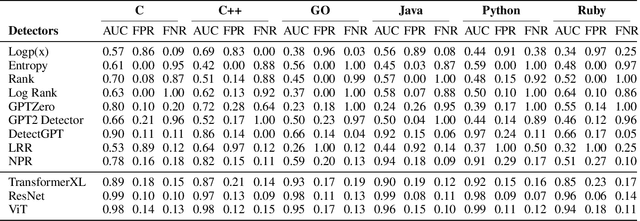
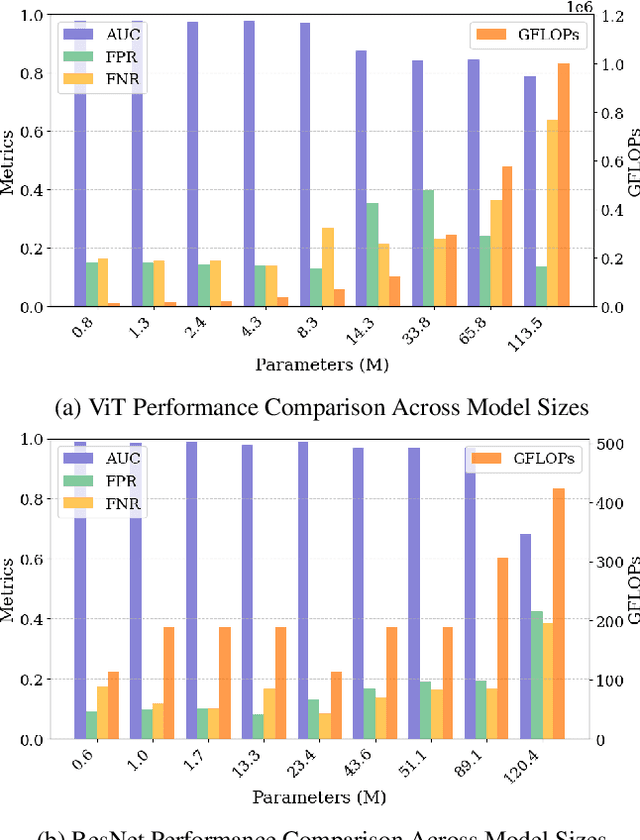

The rise of large language models (LLMs) like ChatGPT has significantly improved automated code generation, enhancing software development efficiency. However, this introduces challenges in academia, particularly in distinguishing between human-written and LLM-generated code, which complicates issues of academic integrity. Existing detection methods, such as pre-trained models and watermarking, face limitations in adaptability and computational efficiency. In this paper, we propose a novel detection method using 2D token probability maps combined with vision models, preserving spatial code structures such as indentation and brackets. By transforming code into log probability matrices and applying vision models like Vision Transformers (ViT) and ResNet, we capture both content and structure for more accurate detection. Our method shows robustness across multiple programming languages and improves upon traditional detectors, offering a scalable and computationally efficient solution for identifying LLM-generated code.
Token2Wave
Nov 11, 2024



This paper provides an in-depth analysis of Token2Wave, a novel token representation method derived from the Wave Network, designed to capture both global and local semantics of input text through wave-inspired complex vectors. In Token2Wave, each token is represented with a magnitude component, capturing the global semantics of the entire input text, and a phase component, encoding the relationships between individual tokens and the global semantics. Building on prior research that demonstrated the effectiveness of wave-like operations, such as interference and modulation, during forward propagation, this study investigates the convergence behavior, backpropagation characteristics, and embedding independence within the Token2Wave framework. A detailed computational complexity analysis shows that Token2Wave can significantly reduce video memory usage and training time compared to BERT. Gradient comparisons for the [CLS] token, total input text, and classifier parameters further highlight Token2Wave's unique characteristics. This research offers new insights into wave-based token representations, demonstrating their potential to enable efficient and computationally friendly language model architectures.
Bridging the Gap: Representation Spaces in Neuro-Symbolic AI
Nov 07, 2024Neuro-symbolic AI is an effective method for improving the overall performance of AI models by combining the advantages of neural networks and symbolic learning. However, there are differences between the two in terms of how they process data, primarily because they often use different data representation methods, which is often an important factor limiting the overall performance of the two. From this perspective, we analyzed 191 studies from 2013 by constructing a four-level classification framework. The first level defines five types of representation spaces, and the second level focuses on five types of information modalities that the representation space can represent. Then, the third level describes four symbolic logic methods. Finally, the fourth-level categories propose three collaboration strategies between neural networks and symbolic learning. Furthermore, we conducted a detailed analysis of 46 research based on their representation space.
Neuro-Symbolic AI: Explainability, Challenges, and Future Trends
Nov 07, 2024



Explainability is an essential reason limiting the application of neural networks in many vital fields. Although neuro-symbolic AI hopes to enhance the overall explainability by leveraging the transparency of symbolic learning, the results are less evident than imagined. This article proposes a classification for explainability by considering both model design and behavior of 191 studies from 2013, focusing on neuro-symbolic AI, hoping to inspire scholars who want to understand the explainability of neuro-symbolic AI. Precisely, we classify them into five categories by considering whether the form of bridging the representation differences is readable as their design factor, if there are representation differences between neural networks and symbolic logic learning, and whether a model decision or prediction process is understandable as their behavior factor: implicit intermediate representations and implicit prediction, partially explicit intermediate representations and partially explicit prediction, explicit intermediate representations or explicit prediction, explicit intermediate representation and explicit prediction, unified representation and explicit prediction. We also analyzed the research trends and three significant challenges: unified representations, explainability and transparency, and sufficient cooperation from neural networks and symbolic learning. Finally, we put forward suggestions for future research in three aspects: unified representations, enhancing model explainability, ethical considerations, and social impact.
Wave Network: An Ultra-Small Language Model
Nov 04, 2024



We propose an innovative token representation and update method in a new ultra-small language model: the Wave network. Specifically, we use a \textbf{complex vector} to represent each token, encoding both global and local semantics of the input text. A \textbf{complex vector} consists of two components: a magnitude vector representing the \textit{global semantics} of the input text, and a phase vector capturing the \textit{relationships between individual tokens and global semantics}. Experiments on the AG News text classification task demonstrate that, when generating complex vectors from randomly initialized token embeddings, our single-layer Wave Network achieves 90.91\% accuracy with wave interference and 91.66\% with wave modulation -- outperforming a single Transformer layer using BERT pre-trained embeddings by 19.23\% and 19.98\%, respectively, and approaching the accuracy of the pre-trained and fine-tuned BERT base model (94.64\%). Additionally, compared to BERT base, the Wave Network reduces video memory usage and training time by 77.34\% and 85.62\% during wave modulation. In summary, we used a 2.4-million-parameter small language model to achieve accuracy comparable to a 100-million-parameter BERT model in text classification.
LecPrompt: A Prompt-based Approach for Logical Error Correction with CodeBERT
Oct 10, 2024



Logical errors in programming don't raise compiler alerts, making them hard to detect. These silent errors can disrupt a program's function or cause run-time issues. Their correction requires deep insight into the program's logic, highlighting the importance of automated detection and repair. In this paper, we introduce LecPrompt to localize and repair logical errors, an prompt-based approach that harnesses the capabilities of CodeBERT, a transformer-based large language model trained on code. First, LecPrompt leverages a large language model to calculate perplexity and log probability metrics, pinpointing logical errors at both token and line levels. Through statistical analysis, it identifies tokens and lines that deviate significantly from the expected patterns recognized by large language models, marking them as potential error sources. Second, by framing the logical error correction challenge as a Masked Language Modeling (MLM) task, LecPrompt employs CodeBERT to autoregressively repair the identified error tokens. Finally, the soft-prompt method provides a novel solution in low-cost scenarios, ensuring that the model can be fine-tuned to the specific nuances of the logical error correction task without incurring high computational costs. To evaluate LecPrompt's performance, we created a method to introduce logical errors into correct code and applying this on QuixBugs to produce the QuixBugs-LE dataset. Our evaluations on the QuixBugs-LE dataset for both Python and Java highlight the impressive capabilities of our method, LecPrompt. For Python, LecPrompt achieves a noteworthy 74.58% top-1 token-level repair accuracy and 27.4% program-level repair accuracy. In Java, LecPrompt delivers a 69.23\% top-1 token-level repair accuracy and 24.7% full program-level repair accuracy.
Signal Watermark on Large Language Models
Oct 09, 2024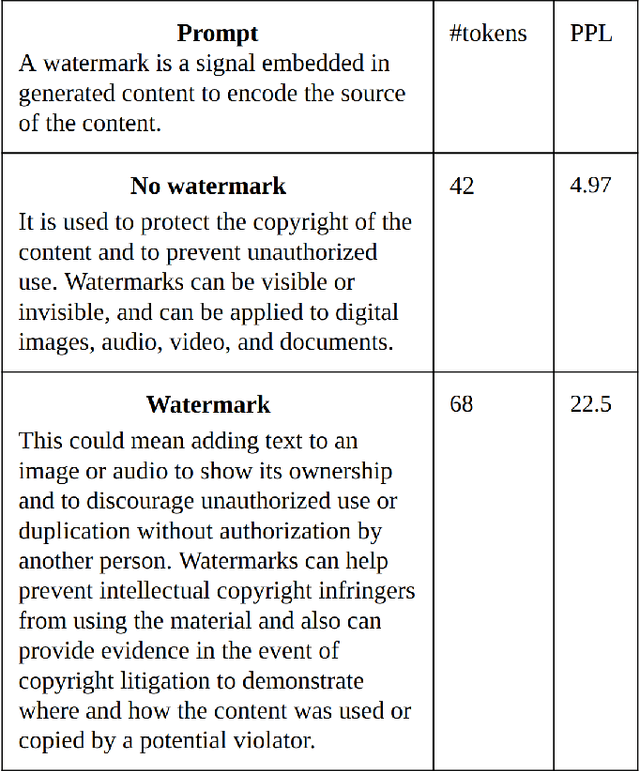

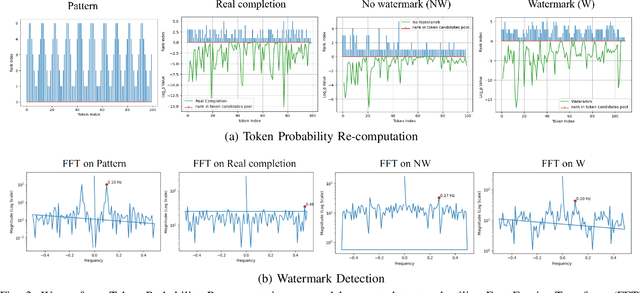
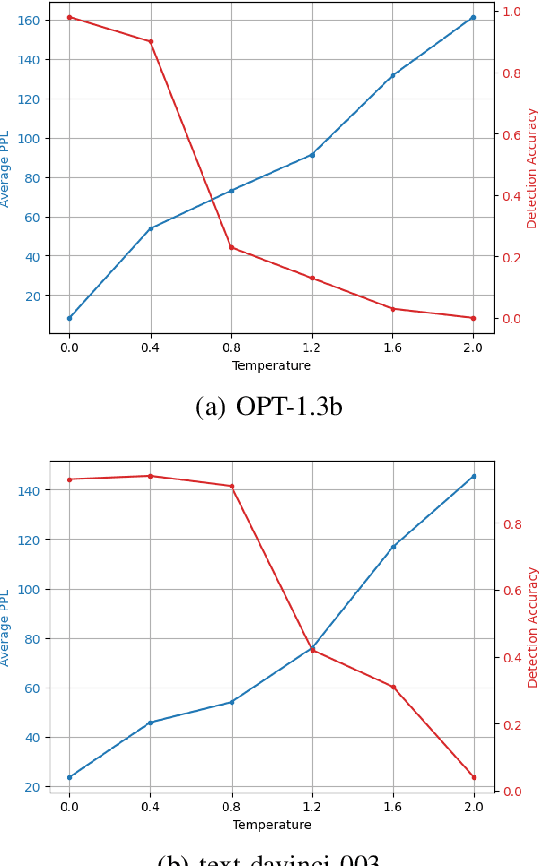
As Large Language Models (LLMs) become increasingly sophisticated, they raise significant security concerns, including the creation of fake news and academic misuse. Most detectors for identifying model-generated text are limited by their reliance on variance in perplexity and burstiness, and they require substantial computational resources. In this paper, we proposed a watermarking method embedding a specific watermark into the text during its generation by LLMs, based on a pre-defined signal pattern. This technique not only ensures the watermark's invisibility to humans but also maintains the quality and grammatical integrity of model-generated text. We utilize LLMs and Fast Fourier Transform (FFT) for token probability computation and detection of the signal watermark. The unique application of signal processing principles within the realm of text generation by LLMs allows for subtle yet effective embedding of watermarks, which do not compromise the quality or coherence of the generated text. Our method has been empirically validated across multiple LLMs, consistently maintaining high detection accuracy, even with variations in temperature settings during text generation. In the experiment of distinguishing between human-written and watermarked text, our method achieved an AUROC score of 0.97, significantly outperforming existing methods like GPTZero, which scored 0.64. The watermark's resilience to various attacking scenarios further confirms its robustness, addressing significant challenges in model-generated text authentication.
FreqMark: Frequency-Based Watermark for Sentence-Level Detection of LLM-Generated Text
Oct 09, 2024



The increasing use of Large Language Models (LLMs) for generating highly coherent and contextually relevant text introduces new risks, including misuse for unethical purposes such as disinformation or academic dishonesty. To address these challenges, we propose FreqMark, a novel watermarking technique that embeds detectable frequency-based watermarks in LLM-generated text during the token sampling process. The method leverages periodic signals to guide token selection, creating a watermark that can be detected with Short-Time Fourier Transform (STFT) analysis. This approach enables accurate identification of LLM-generated content, even in mixed-text scenarios with both human-authored and LLM-generated segments. Our experiments demonstrate the robustness and precision of FreqMark, showing strong detection capabilities against various attack scenarios such as paraphrasing and token substitution. Results show that FreqMark achieves an AUC improvement of up to 0.98, significantly outperforming existing detection methods.
Multi-Task Program Error Repair and Explanatory Diagnosis
Oct 09, 2024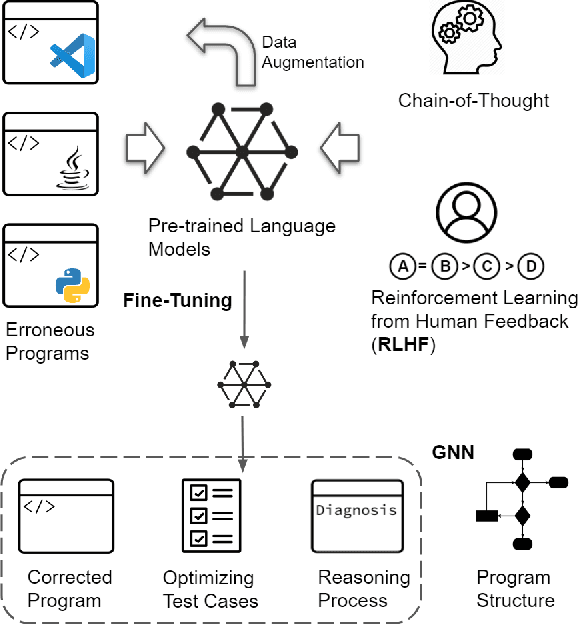

Program errors can occur in any type of programming, and can manifest in a variety of ways, such as unexpected output, crashes, or performance issues. And program error diagnosis can often be too abstract or technical for developers to understand, especially for beginners. The goal of this paper is to present a novel machine-learning approach for Multi-task Program Error Repair and Explanatory Diagnosis (mPRED). A pre-trained language model is used to encode the source code, and a downstream model is specifically designed to identify and repair errors. Programs and test cases will be augmented and optimized from several perspectives. Additionally, our approach incorporates a "chain of thoughts" method, which enables the models to produce intermediate reasoning explanations before providing the final correction. To aid in visualizing and analyzing the program structure, we use a graph neural network for program structure visualization. Overall, our approach offers a promising approach for repairing program errors across different programming languages and providing helpful explanations to programmers.
Intent Contrastive Learning with Cross Subsequences for Sequential Recommendation
Oct 31, 2023
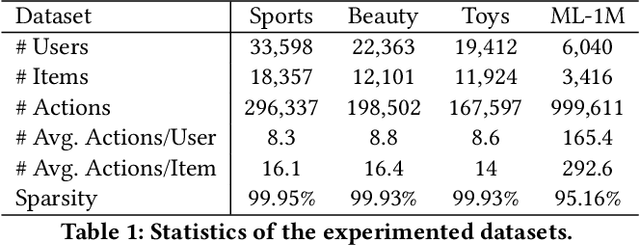

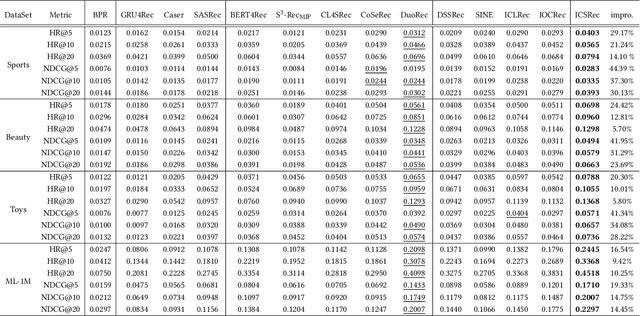
The user purchase behaviors are mainly influenced by their intentions (e.g., buying clothes for decoration, buying brushes for painting, etc.). Modeling a user's latent intention can significantly improve the performance of recommendations. Previous works model users' intentions by considering the predefined label in auxiliary information or introducing stochastic data augmentation to learn purposes in the latent space. However, the auxiliary information is sparse and not always available for recommender systems, and introducing stochastic data augmentation may introduce noise and thus change the intentions hidden in the sequence. Therefore, leveraging user intentions for sequential recommendation (SR) can be challenging because they are frequently varied and unobserved. In this paper, Intent contrastive learning with Cross Subsequences for sequential Recommendation (ICSRec) is proposed to model users' latent intentions. Specifically, ICSRec first segments a user's sequential behaviors into multiple subsequences by using a dynamic sliding operation and takes these subsequences into the encoder to generate the representations for the user's intentions. To tackle the problem of no explicit labels for purposes, ICSRec assumes different subsequences with the same target item may represent the same intention and proposes a coarse-grain intent contrastive learning to push these subsequences closer. Then, fine-grain intent contrastive learning is mentioned to capture the fine-grain intentions of subsequences in sequential behaviors. Extensive experiments conducted on four real-world datasets demonstrate the superior performance of the proposed ICSRec model compared with baseline methods.