 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntent Contrastive Learning with Cross Subsequences for Sequential Recommendation
Oct 31, 2023
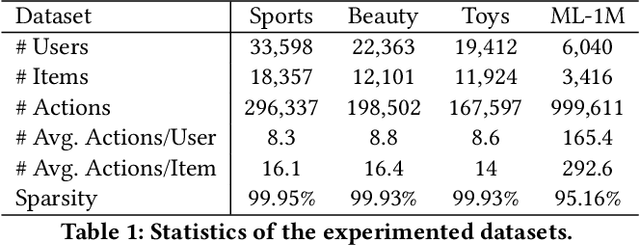

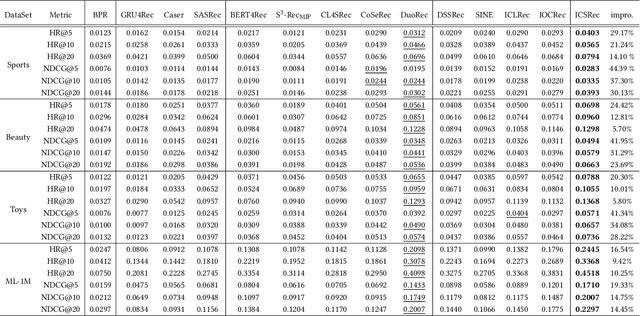
The user purchase behaviors are mainly influenced by their intentions (e.g., buying clothes for decoration, buying brushes for painting, etc.). Modeling a user's latent intention can significantly improve the performance of recommendations. Previous works model users' intentions by considering the predefined label in auxiliary information or introducing stochastic data augmentation to learn purposes in the latent space. However, the auxiliary information is sparse and not always available for recommender systems, and introducing stochastic data augmentation may introduce noise and thus change the intentions hidden in the sequence. Therefore, leveraging user intentions for sequential recommendation (SR) can be challenging because they are frequently varied and unobserved. In this paper, Intent contrastive learning with Cross Subsequences for sequential Recommendation (ICSRec) is proposed to model users' latent intentions. Specifically, ICSRec first segments a user's sequential behaviors into multiple subsequences by using a dynamic sliding operation and takes these subsequences into the encoder to generate the representations for the user's intentions. To tackle the problem of no explicit labels for purposes, ICSRec assumes different subsequences with the same target item may represent the same intention and proposes a coarse-grain intent contrastive learning to push these subsequences closer. Then, fine-grain intent contrastive learning is mentioned to capture the fine-grain intentions of subsequences in sequential behaviors. Extensive experiments conducted on four real-world datasets demonstrate the superior performance of the proposed ICSRec model compared with baseline methods.
HDTR-Net: A Real-Time High-Definition Teeth Restoration Network for Arbitrary Talking Face Generation Methods
Sep 14, 2023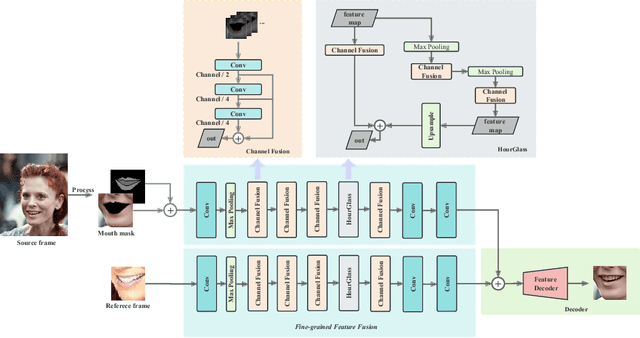
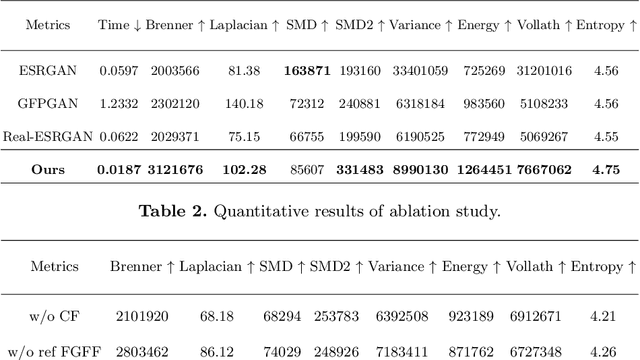
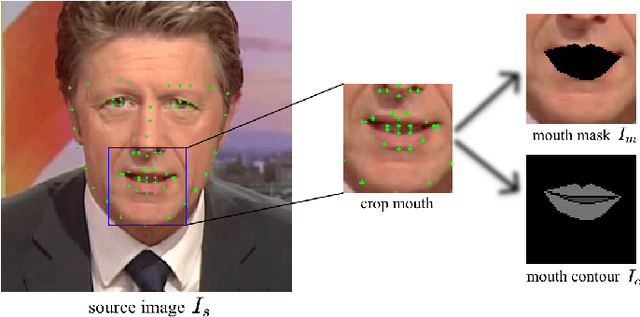
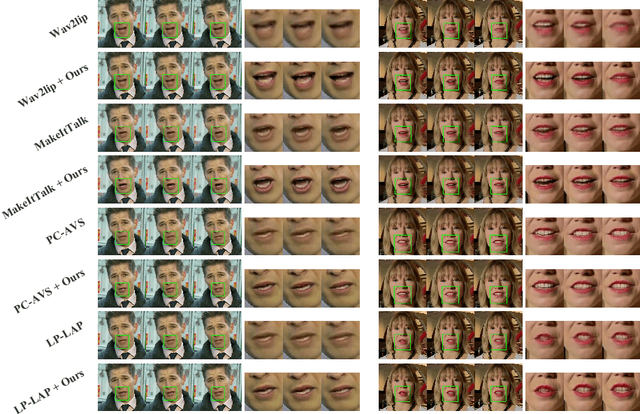
Talking Face Generation (TFG) aims to reconstruct facial movements to achieve high natural lip movements from audio and facial features that are under potential connections. Existing TFG methods have made significant advancements to produce natural and realistic images. However, most work rarely takes visual quality into consideration. It is challenging to ensure lip synchronization while avoiding visual quality degradation in cross-modal generation methods. To address this issue, we propose a universal High-Definition Teeth Restoration Network, dubbed HDTR-Net, for arbitrary TFG methods. HDTR-Net can enhance teeth regions at an extremely fast speed while maintaining synchronization, and temporal consistency. In particular, we propose a Fine-Grained Feature Fusion (FGFF) module to effectively capture fine texture feature information around teeth and surrounding regions, and use these features to fine-grain the feature map to enhance the clarity of teeth. Extensive experiments show that our method can be adapted to arbitrary TFG methods without suffering from lip synchronization and frame coherence. Another advantage of HDTR-Net is its real-time generation ability. Also under the condition of high-definition restoration of talking face video synthesis, its inference speed is $300\%$ faster than the current state-of-the-art face restoration based on super-resolution.
Meta-optimized Contrastive Learning for Sequential Recommendation
Apr 26, 2023Contrastive Learning (CL) performances as a rising approach to address the challenge of sparse and noisy recommendation data. Although having achieved promising results, most existing CL methods only perform either hand-crafted data or model augmentation for generating contrastive pairs to find a proper augmentation operation for different datasets, which makes the model hard to generalize. Additionally, since insufficient input data may lead the encoder to learn collapsed embeddings, these CL methods expect a relatively large number of training data (e.g., large batch size or memory bank) to contrast. However, not all contrastive pairs are always informative and discriminative enough for the training processing. Therefore, a more general CL-based recommendation model called Meta-optimized Contrastive Learning for sequential Recommendation (MCLRec) is proposed in this work. By applying both data augmentation and learnable model augmentation operations, this work innovates the standard CL framework by contrasting data and model augmented views for adaptively capturing the informative features hidden in stochastic data augmentation. Moreover, MCLRec utilizes a meta-learning manner to guide the updating of the model augmenters, which helps to improve the quality of contrastive pairs without enlarging the amount of input data. Finally, a contrastive regularization term is considered to encourage the augmentation model to generate more informative augmented views and avoid too similar contrastive pairs within the meta updating. The experimental results on commonly used datasets validate the effectiveness of MCLRec.