 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA2RAG: Adaptive Agentic Graph Retrieval for Cost-Aware and Reliable Reasoning
Jan 29, 2026Graph Retrieval-Augmented Generation (Graph-RAG) enhances multihop question answering by organizing corpora into knowledge graphs and routing evidence through relational structure. However, practical deployments face two persistent bottlenecks: (i) mixed-difficulty workloads where one-size-fits-all retrieval either wastes cost on easy queries or fails on hard multihop cases, and (ii) extraction loss, where graph abstraction omits fine-grained qualifiers that remain only in source text. We present A2RAG, an adaptive-and-agentic GraphRAG framework for cost-aware and reliable reasoning. A2RAG couples an adaptive controller that verifies evidence sufficiency and triggers targeted refinement only when necessary, with an agentic retriever that progressively escalates retrieval effort and maps graph signals back to provenance text to remain robust under extraction loss and incomplete graphs. Experiments on HotpotQA and 2WikiMultiHopQA demonstrate that A2RAG achieves +9.9/+11.8 absolute gains in Recall@2, while cutting token consumption and end-to-end latency by about 50% relative to iterative multihop baselines.
Re-understanding Graph Unlearning through Memorization
Jan 21, 2026Graph unlearning (GU), which removes nodes, edges, or features from trained graph neural networks (GNNs), is crucial in Web applications where graph data may contain sensitive, mislabeled, or malicious information. However, existing GU methods lack a clear understanding of the key factors that determine unlearning effectiveness, leading to three fundamental limitations: (1) impractical and inaccurate GU difficulty assessment due to test-access requirements and invalid assumptions, (2) ineffectiveness on hard-to-unlearn tasks, and (3) misaligned evaluation protocols that overemphasize easy tasks and fail to capture true forgetting capability. To address these issues, we establish GNN memorization as a new perspective for understanding graph unlearning and propose MGU, a Memorization-guided Graph Unlearning framework. MGU achieves three key advances: it provides accurate and practical difficulty assessment across different GU tasks, develops an adaptive strategy that dynamically adjusts unlearning objectives based on difficulty levels, and establishes a comprehensive evaluation protocol that aligns with practical requirements. Extensive experiments on ten real-world graphs demonstrate that MGU consistently outperforms state-of-the-art baselines in forgetting quality, computational efficiency, and utility preservation.
How Do Graph Signals Affect Recommendation: Unveiling the Mystery of Low and High-Frequency Graph Signals
Dec 10, 2025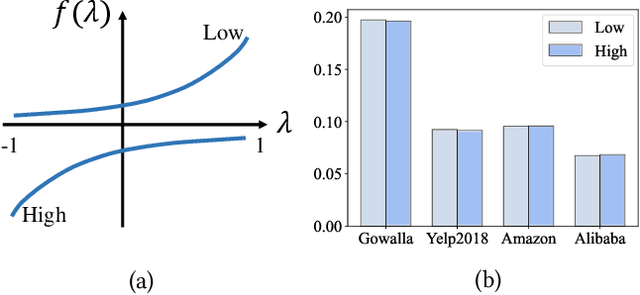
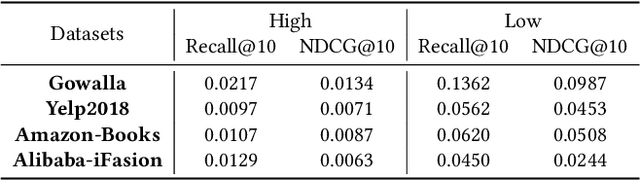
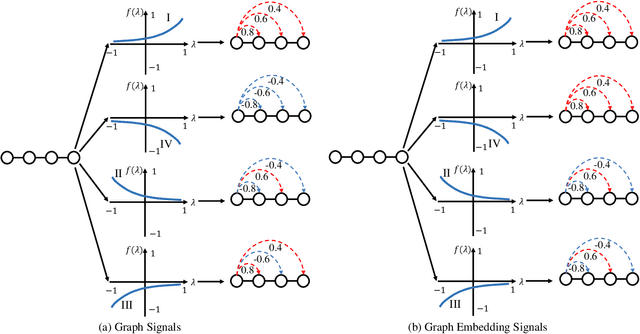
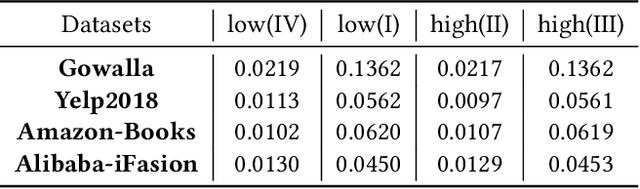
Spectral graph neural networks (GNNs) are highly effective in modeling graph signals, with their success in recommendation often attributed to low-pass filtering. However, recent studies highlight the importance of high-frequency signals. The role of low-frequency and high-frequency graph signals in recommendation remains unclear. This paper aims to bridge this gap by investigating the influence of graph signals on recommendation performance. We theoretically prove that the effects of low-frequency and high-frequency graph signals are equivalent in recommendation tasks, as both contribute by smoothing the similarities between user-item pairs. To leverage this insight, we propose a frequency signal scaler, a plug-and-play module that adjusts the graph signal filter function to fine-tune the smoothness between user-item pairs, making it compatible with any GNN model. Additionally, we identify and prove that graph embedding-based methods cannot fully capture the characteristics of graph signals. To address this limitation, a space flip method is introduced to restore the expressive power of graph embeddings. Remarkably, we demonstrate that either low-frequency or high-frequency graph signals alone are sufficient for effective recommendations. Extensive experiments on four public datasets validate the effectiveness of our proposed methods. Code is avaliable at https://github.com/mojosey/SimGCF.
Wavelet Enhanced Adaptive Frequency Filter for Sequential Recommendation
Nov 10, 2025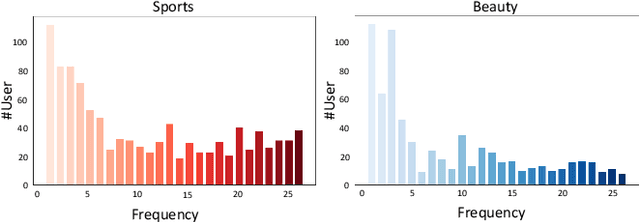
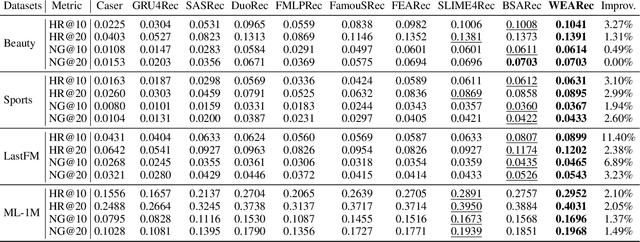
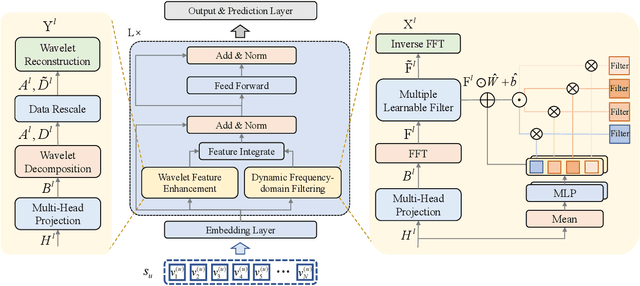
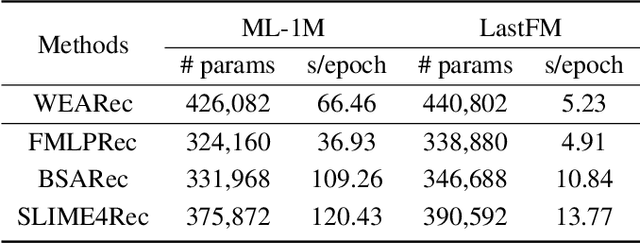
Sequential recommendation has garnered significant attention for its ability to capture dynamic preferences by mining users' historical interaction data. Given that users' complex and intertwined periodic preferences are difficult to disentangle in the time domain, recent research is exploring frequency domain analysis to identify these hidden patterns. However, current frequency-domain-based methods suffer from two key limitations: (i) They primarily employ static filters with fixed characteristics, overlooking the personalized nature of behavioral patterns; (ii) While the global discrete Fourier transform excels at modeling long-range dependencies, it can blur non-stationary signals and short-term fluctuations. To overcome these limitations, we propose a novel method called Wavelet Enhanced Adaptive Frequency Filter for Sequential Recommendation. Specifically, it consists of two vital modules: dynamic frequency-domain filtering and wavelet feature enhancement. The former is used to dynamically adjust filtering operations based on behavioral sequences to extract personalized global information, and the latter integrates wavelet transform to reconstruct sequences, enhancing blurred non-stationary signals and short-term fluctuations. Finally, these two modules work to achieve comprehensive performance and efficiency optimization in long sequential recommendation scenarios. Extensive experiments on four widely-used benchmark datasets demonstrate the superiority of our work.
Towards Comprehensive and Prerequisite-Free Explainer for Graph Neural Networks
May 20, 2025To enhance the reliability and credibility of graph neural networks (GNNs) and improve the transparency of their decision logic, a new field of explainability of GNNs (XGNN) has emerged. However, two major limitations severely degrade the performance and hinder the generalizability of existing XGNN methods: they (a) fail to capture the complete decision logic of GNNs across diverse distributions in the entire dataset's sample space, and (b) impose strict prerequisites on edge properties and GNN internal accessibility. To address these limitations, we propose OPEN, a novel c\textbf{O}mprehensive and \textbf{P}rerequisite-free \textbf{E}xplainer for G\textbf{N}Ns. OPEN, as the first work in the literature, can infer and partition the entire dataset's sample space into multiple environments, each containing graphs that follow a distinct distribution. OPEN further learns the decision logic of GNNs across different distributions by sampling subgraphs from each environment and analyzing their predictions, thus eliminating the need for strict prerequisites. Experimental results demonstrate that OPEN captures nearly complete decision logic of GNNs, outperforms state-of-the-art methods in fidelity while maintaining similar efficiency, and enhances robustness in real-world scenarios.
Adaptive Graph Unlearning
May 19, 2025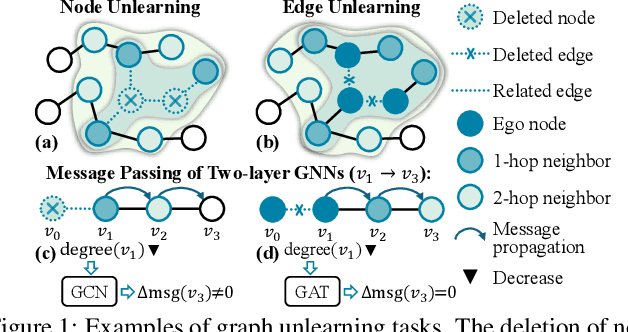

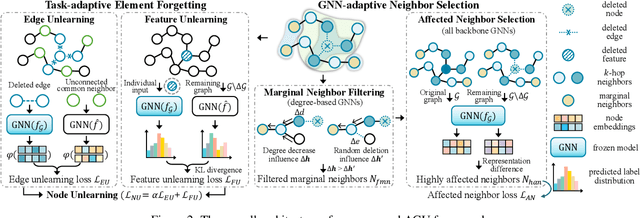
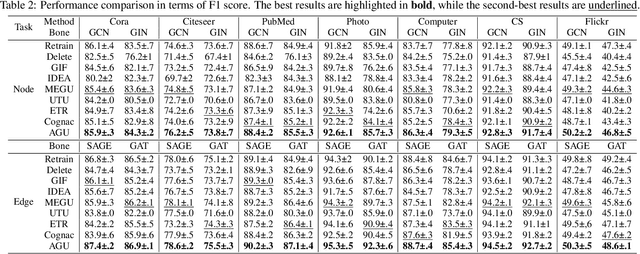
Graph unlearning, which deletes graph elements such as nodes and edges from trained graph neural networks (GNNs), is crucial for real-world applications where graph data may contain outdated, inaccurate, or privacy-sensitive information. However, existing methods often suffer from (1) incomplete or over unlearning due to neglecting the distinct objectives of different unlearning tasks, and (2) inaccurate identification of neighbors affected by deleted elements across various GNN architectures. To address these limitations, we propose AGU, a novel Adaptive Graph Unlearning framework that flexibly adapts to diverse unlearning tasks and GNN architectures. AGU ensures the complete forgetting of deleted elements while preserving the integrity of the remaining graph. It also accurately identifies affected neighbors for each GNN architecture and prioritizes important ones to enhance unlearning performance. Extensive experiments on seven real-world graphs demonstrate that AGU outperforms existing methods in terms of effectiveness, efficiency, and unlearning capability.
Behavior Pattern Mining-based Multi-Behavior Recommendation
Aug 22, 2024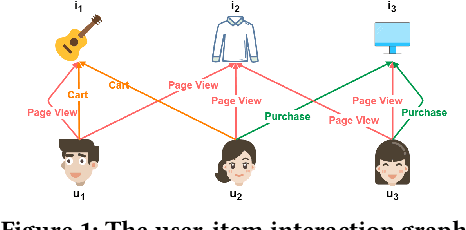
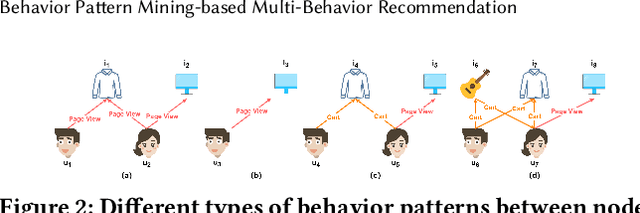
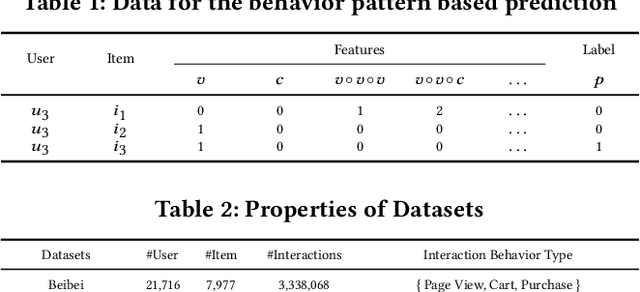
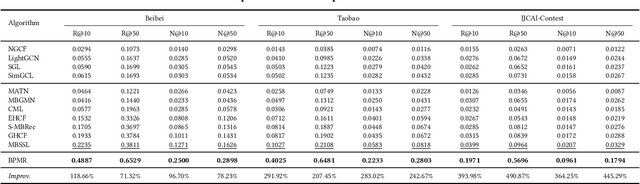
Multi-behavior recommendation systems enhance effectiveness by leveraging auxiliary behaviors (such as page views and favorites) to address the limitations of traditional models that depend solely on sparse target behaviors like purchases. Existing approaches to multi-behavior recommendations typically follow one of two strategies: some derive initial node representations from individual behavior subgraphs before integrating them for a comprehensive profile, while others interpret multi-behavior data as a heterogeneous graph, applying graph neural networks to achieve a unified node representation. However, these methods do not adequately explore the intricate patterns of behavior among users and items. To bridge this gap, we introduce a novel algorithm called Behavior Pattern mining-based Multi-behavior Recommendation (BPMR). Our method extensively investigates the diverse interaction patterns between users and items, utilizing these patterns as features for making recommendations. We employ a Bayesian approach to streamline the recommendation process, effectively circumventing the challenges posed by graph neural network algorithms, such as the inability to accurately capture user preferences due to over-smoothing. Our experimental evaluation on three real-world datasets demonstrates that BPMR significantly outperforms existing state-of-the-art algorithms, showing an average improvement of 268.29% in Recall@10 and 248.02% in NDCG@10 metrics. The code of our BPMR is openly accessible for use and further research at https://github.com/rookitkitlee/BPMR.
Few-shot Learning on Heterogeneous Graphs: Challenges, Progress, and Prospects
Mar 10, 2024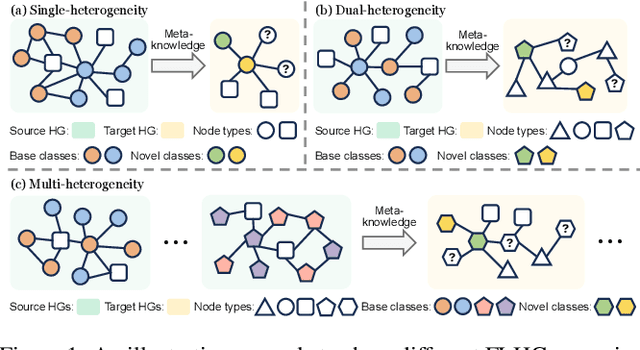
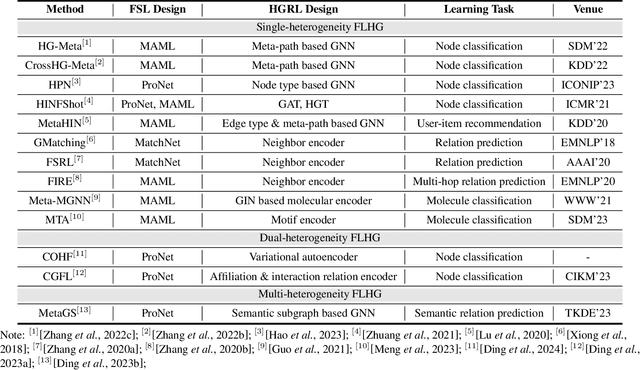
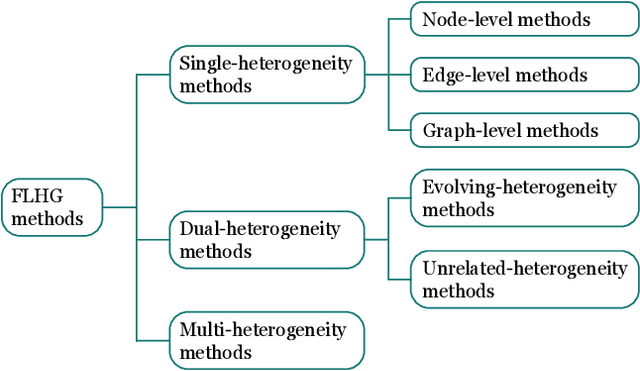
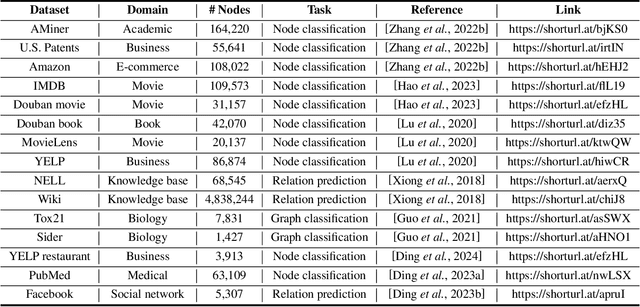
Few-shot learning on heterogeneous graphs (FLHG) is attracting more attention from both academia and industry because prevailing studies on heterogeneous graphs often suffer from label sparsity. FLHG aims to tackle the performance degradation in the face of limited annotated data and there have been numerous recent studies proposing various methods and applications. In this paper, we provide a comprehensive review of existing FLHG methods, covering challenges, research progress, and future prospects. Specifically, we first formalize FLHG and categorize its methods into three types: single-heterogeneity FLHG, dual-heterogeneity FLHG, and multi-heterogeneity FLHG. Then, we analyze the research progress within each category, highlighting the most recent and representative developments. Finally, we identify and discuss promising directions for future research in FLHG. To the best of our knowledge, this paper is the first systematic and comprehensive review of FLHG.
Adaptive Hypergraph Network for Trust Prediction
Feb 07, 2024
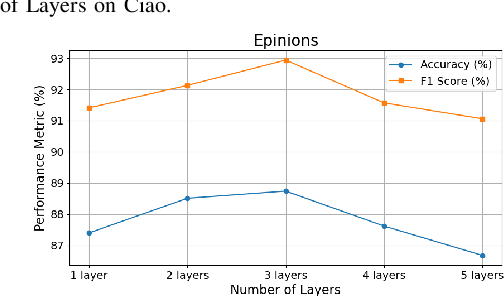
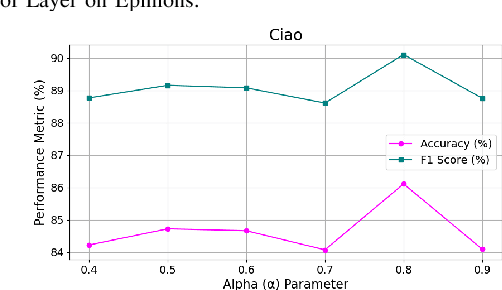
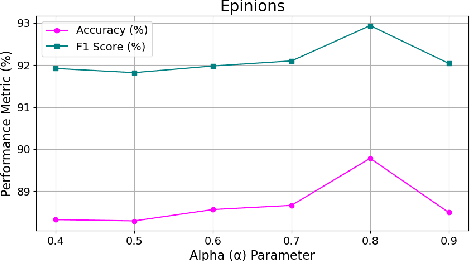
Trust plays an essential role in an individual's decision-making. Traditional trust prediction models rely on pairwise correlations to infer potential relationships between users. However, in the real world, interactions between users are usually complicated rather than pairwise only. Hypergraphs offer a flexible approach to modeling these complex high-order correlations (not just pairwise connections), since hypergraphs can leverage hyperedeges to link more than two nodes. However, most hypergraph-based methods are generic and cannot be well applied to the trust prediction task. In this paper, we propose an Adaptive Hypergraph Network for Trust Prediction (AHNTP), a novel approach that improves trust prediction accuracy by using higher-order correlations. AHNTP utilizes Motif-based PageRank to capture high-order social influence information. In addition, it constructs hypergroups from both node-level and structure-level attributes to incorporate complex correlation information. Furthermore, AHNTP leverages adaptive hypergraph Graph Convolutional Network (GCN) layers and multilayer perceptrons (MLPs) to generate comprehensive user embeddings, facilitating trust relationship prediction. To enhance model generalization and robustness, we introduce a novel supervised contrastive learning loss for optimization. Extensive experiments demonstrate the superiority of our model over the state-of-the-art approaches in terms of trust prediction accuracy. The source code of this work can be accessed via https://github.com/Sherry-XU1995/AHNTP.
Few-Shot Causal Representation Learning for Out-of-Distribution Generalization on Heterogeneous Graphs
Jan 07, 2024Heterogeneous graph few-shot learning (HGFL) has been developed to address the label sparsity issue in heterogeneous graphs (HGs), which consist of various types of nodes and edges. The core concept of HGFL is to extract knowledge from rich-labeled classes in a source HG, transfer this knowledge to a target HG to facilitate learning new classes with few-labeled training data, and finally make predictions on unlabeled testing data. Existing methods typically assume that the source HG, training data, and testing data all share the same distribution. However, in practice, distribution shifts among these three types of data are inevitable due to two reasons: (1) the limited availability of the source HG that matches the target HG distribution, and (2) the unpredictable data generation mechanism of the target HG. Such distribution shifts result in ineffective knowledge transfer and poor learning performance in existing methods, thereby leading to a novel problem of out-of-distribution (OOD) generalization in HGFL. To address this challenging problem, we propose a novel Causal OOD Heterogeneous graph Few-shot learning model, namely COHF. In COHF, we first characterize distribution shifts in HGs with a structural causal model, establishing an invariance principle for OOD generalization in HGFL. Then, following this invariance principle, we propose a new variational autoencoder-based heterogeneous graph neural network to mitigate the impact of distribution shifts. Finally, by integrating this network with a novel meta-learning framework, COHF effectively transfers knowledge to the target HG to predict new classes with few-labeled data. Extensive experiments on seven real-world datasets have demonstrated the superior performance of COHF over the state-of-the-art methods.