 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Robustness of Knowledge-Grounded Dialogue via Contrastive Learning
Jan 09, 2024Knowledge-grounded dialogue (KGD) learns to generate an informative response based on a given dialogue context and external knowledge (\emph{e.g.}, knowledge graphs; KGs). Recently, the emergence of large language models (LLMs) and pre-training techniques has brought great success to knowledge-grounded dialogue. However, when building KGD systems in real applications, there are various real-world noises that are inevitable to face. For example, the dialogue context might involve perturbations such as misspellings and abbreviations. In addition, KGs typically suffer from incompletion and also might contain erroneous and outdated facts. Such real-world noises pose a challenge to the robustness of KGD systems and hinder their applications in the real world. In this paper, we propose an entity-based contrastive learning framework for improving the robustness of KGD. Specifically, we make use of the entity information in a KGD sample to create both its positive and negative samples which involve semantic-irrelevant and semantic-relevant perturbations, respectively. The contrastive learning framework ensures the KGD model is aware of these two types of perturbations, thus generating informative responses with the potentially noisy inputs in real applications. Experimental results on three benchmark datasets show that our method achieves new state-of-the-art performance in terms of automatic evaluation scores, verifying its effectiveness and potentiality. Furthermore, we show that our method can generate better responses than comparison models in both the noisy and the few-shot settings.
Meta-optimized Joint Generative and Contrastive Learning for Sequential Recommendation
Oct 21, 2023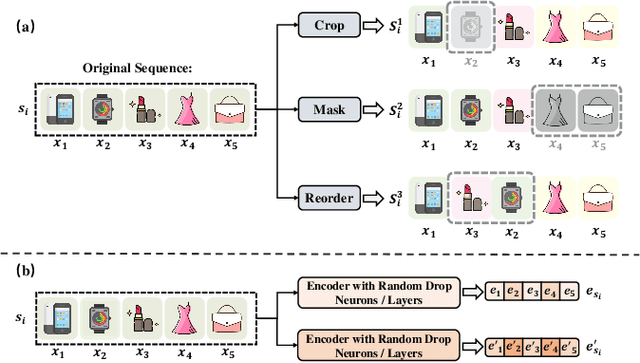
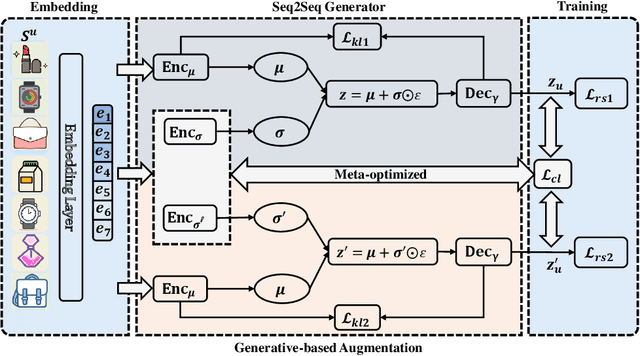
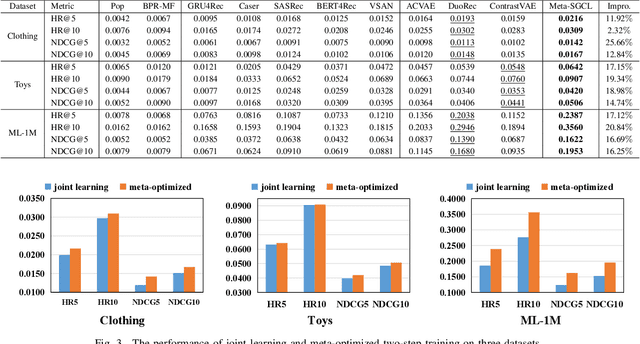
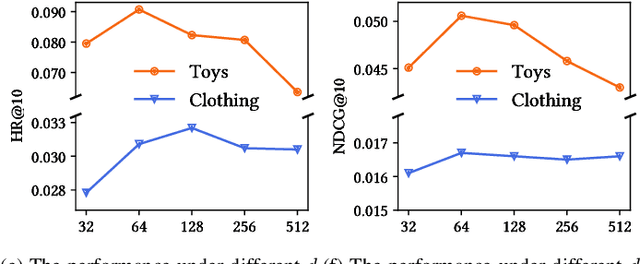
Sequential Recommendation (SR) has received increasing attention due to its ability to capture user dynamic preferences. Recently, Contrastive Learning (CL) provides an effective approach for sequential recommendation by learning invariance from different views of an input. However, most existing data or model augmentation methods may destroy semantic sequential interaction characteristics and often rely on the hand-crafted property of their contrastive view-generation strategies. In this paper, we propose a Meta-optimized Seq2Seq Generator and Contrastive Learning (Meta-SGCL) for sequential recommendation, which applies the meta-optimized two-step training strategy to adaptive generate contrastive views. Specifically, Meta-SGCL first introduces a simple yet effective augmentation method called Sequence-to-Sequence (Seq2Seq) generator, which treats the Variational AutoEncoders (VAE) as the view generator and can constitute contrastive views while preserving the original sequence's semantics. Next, the model employs a meta-optimized two-step training strategy, which aims to adaptively generate contrastive views without relying on manually designed view-generation techniques. Finally, we evaluate our proposed method Meta-SGCL using three public real-world datasets. Compared with the state-of-the-art methods, our experimental results demonstrate the effectiveness of our model and the code is available.
Snowman: A Million-scale Chinese Commonsense Knowledge Graph Distilled from Foundation Model
Jun 17, 2023



Constructing commonsense knowledge graphs (CKGs) has attracted wide research attention due to its significant importance in cognitive intelligence. Nevertheless, existing CKGs are typically oriented to English, limiting the research in non-English languages. Meanwhile, the emergence of foundation models like ChatGPT and GPT-4 has shown promising intelligence with the help of reinforcement learning from human feedback. Under the background, in this paper, we utilize foundation models to construct a Chinese CKG, named Snowman. Specifically, we distill different types of commonsense head items from ChatGPT, and continue to use it to collect tail items with respect to the head items and pre-defined relations. Based on the preliminary analysis, we find the negative commonsense knowledge distilled by ChatGPT achieves lower human acceptance compared to other knowledge. Therefore, we design a simple yet effective self-instruct filtering strategy to filter out invalid negative commonsense. Overall, the constructed Snowman covers more than ten million Chinese commonsense triples, making it the largest Chinese CKG. Moreover, human studies show the acceptance of Snowman achieves 90.6\%, indicating the high-quality triples distilled by the cutting-edge foundation model. We also conduct experiments on commonsense knowledge models to show the usability and effectiveness of our Snowman.
Towards Unifying Multi-Lingual and Cross-Lingual Summarization
May 16, 2023
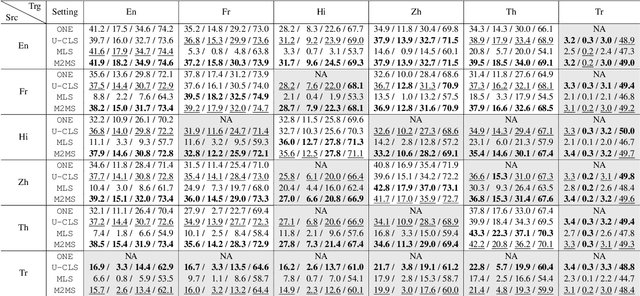


To adapt text summarization to the multilingual world, previous work proposes multi-lingual summarization (MLS) and cross-lingual summarization (CLS). However, these two tasks have been studied separately due to the different definitions, which limits the compatible and systematic research on both of them. In this paper, we aim to unify MLS and CLS into a more general setting, i.e., many-to-many summarization (M2MS), where a single model could process documents in any language and generate their summaries also in any language. As the first step towards M2MS, we conduct preliminary studies to show that M2MS can better transfer task knowledge across different languages than MLS and CLS. Furthermore, we propose Pisces, a pre-trained M2MS model that learns language modeling, cross-lingual ability and summarization ability via three-stage pre-training. Experimental results indicate that our Pisces significantly outperforms the state-of-the-art baselines, especially in the zero-shot directions, where there is no training data from the source-language documents to the target-language summaries.
Is ChatGPT a Good NLG Evaluator? A Preliminary Study
Mar 07, 2023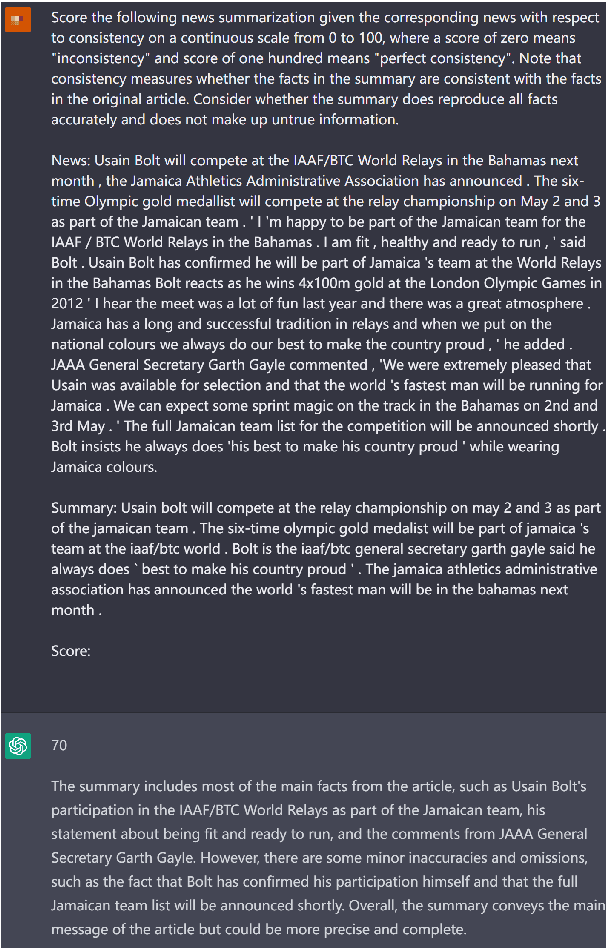
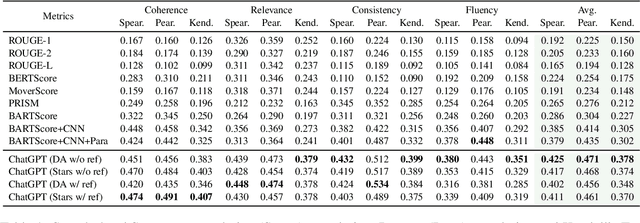

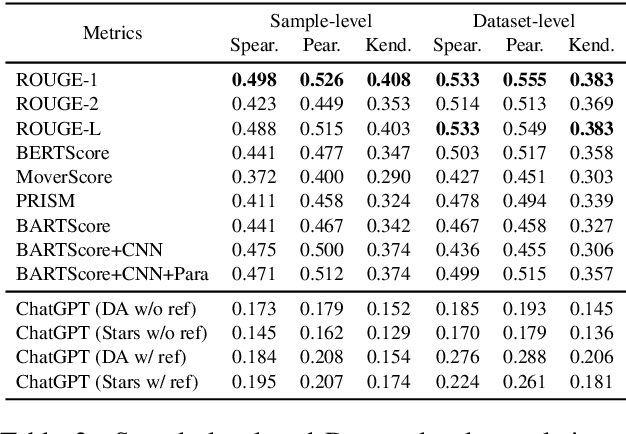
Recently, the emergence of ChatGPT has attracted wide attention from the computational linguistics community. Many prior studies have shown that ChatGPT achieves remarkable performance on various NLP tasks in terms of automatic evaluation metrics. However, the ability of ChatGPT to serve as an evaluation metric is still underexplored. Considering assessing the quality of NLG models is an arduous task and previous statistical metrics notoriously show their poor correlation with human judgments, we wonder whether ChatGPT is a good NLG evaluation metric. In this report, we provide a preliminary meta-evaluation on ChatGPT to show its reliability as an NLG metric. In detail, we regard ChatGPT as a human evaluator and give task-specific (e.g., summarization) and aspect-specific (e.g., relevance) instruction to prompt ChatGPT to score the generation of NLG models. We conduct experiments on three widely-used NLG meta-evaluation datasets (including summarization, story generation and data-to-text tasks). Experimental results show that compared with previous automatic metrics, ChatGPT achieves state-of-the-art or competitive correlation with golden human judgments. We hope our preliminary study could prompt the emergence of a general-purposed reliable NLG metric.
Cross-Lingual Summarization via ChatGPT
Feb 28, 2023



Given a document in a source language, cross-lingual summarization (CLS) aims to generate a summary in a different target language. Recently, the emergence of ChatGPT has attracted wide attention from the computational linguistics community. However, it is not yet known the performance of ChatGPT on CLS. In this report, we empirically use various prompts to guide ChatGPT to perform zero-shot CLS from different paradigms (i.e., end-to-end and pipeline), and provide a preliminary evaluation on its generated summaries.We find that ChatGPT originally prefers to produce lengthy summaries with more detailed information. But with the help of an interactive prompt, ChatGPT can balance between informativeness and conciseness, and significantly improve its CLS performance. Experimental results on three widely-used CLS datasets show that ChatGPT outperforms the advanced GPT 3.5 model (i.e., text-davinci-003). In addition, we provide qualitative case studies to show the superiority of ChatGPT on CLS.
Long-Document Cross-Lingual Summarization
Dec 01, 2022



Cross-Lingual Summarization (CLS) aims at generating summaries in one language for the given documents in another language. CLS has attracted wide research attention due to its practical significance in the multi-lingual world. Though great contributions have been made, existing CLS works typically focus on short documents, such as news articles, short dialogues and guides. Different from these short texts, long documents such as academic articles and business reports usually discuss complicated subjects and consist of thousands of words, making them non-trivial to process and summarize. To promote CLS research on long documents, we construct Perseus, the first long-document CLS dataset which collects about 94K Chinese scientific documents paired with English summaries. The average length of documents in Perseus is more than two thousand tokens. As a preliminary study on long-document CLS, we build and evaluate various CLS baselines, including pipeline and end-to-end methods. Experimental results on Perseus show the superiority of the end-to-end baseline, outperforming the strong pipeline models equipped with sophisticated machine translation systems. Furthermore, to provide a deeper understanding, we manually analyze the model outputs and discuss specific challenges faced by current approaches. We hope that our work could benchmark long-document CLS and benefit future studies.
MMKGR: Multi-hop Multi-modal Knowledge Graph Reasoning
Sep 03, 2022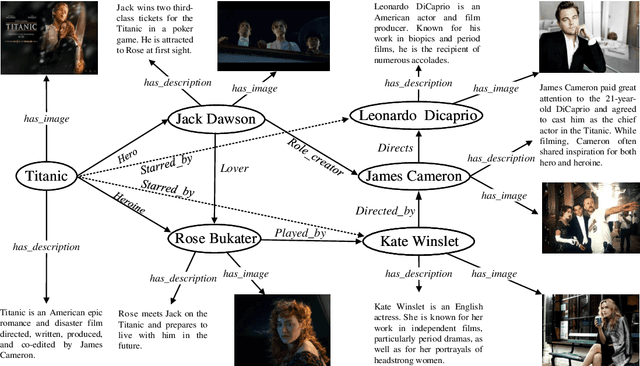
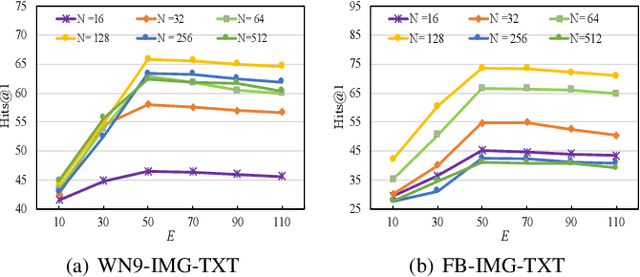
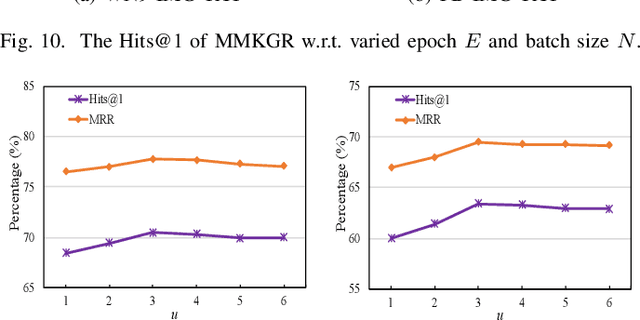
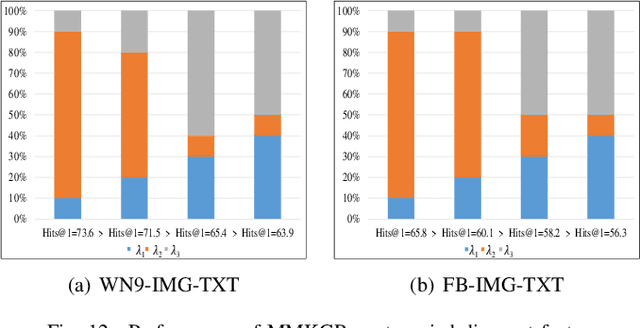
Multi-modal knowledge graphs (MKGs) include not only the relation triplets, but also related multi-modal auxiliary data (i.e., texts and images), which enhance the diversity of knowledge. However, the natural incompleteness has significantly hindered the applications of MKGs. To tackle the problem, existing studies employ the embedding-based reasoning models to infer the missing knowledge after fusing the multi-modal features. However, the reasoning performance of these methods is limited due to the following problems: (1) ineffective fusion of multi-modal auxiliary features; (2) lack of complex reasoning ability as well as inability to conduct the multi-hop reasoning which is able to infer more missing knowledge. To overcome these problems, we propose a novel model entitled MMKGR (Multi-hop Multi-modal Knowledge Graph Reasoning). Specifically, the model contains the following two components: (1) a unified gate-attention network which is designed to generate effective multi-modal complementary features through sufficient attention interaction and noise reduction; (2) a complementary feature-aware reinforcement learning method which is proposed to predict missing elements by performing the multi-hop reasoning process, based on the features obtained in component (1). The experimental results demonstrate that MMKGR outperforms the state-of-the-art approaches in the MKG reasoning task.
Large-scale Entity Alignment via Knowledge Graph Merging, Partitioning and Embedding
Aug 23, 2022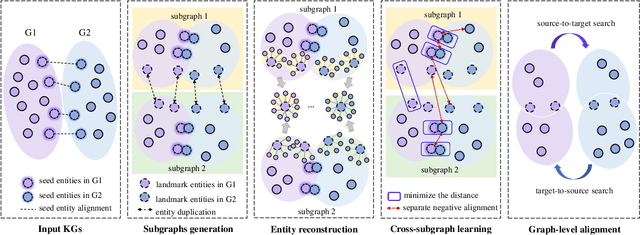
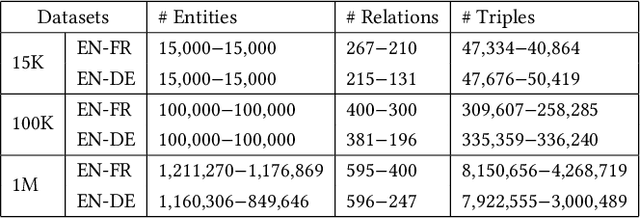
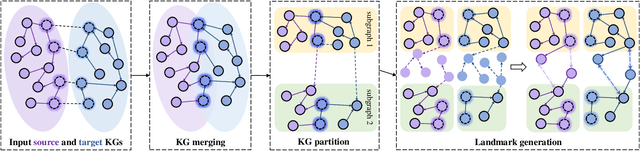

Entity alignment is a crucial task in knowledge graph fusion. However, most entity alignment approaches have the scalability problem. Recent methods address this issue by dividing large KGs into small blocks for embedding and alignment learning in each. However, such a partitioning and learning process results in an excessive loss of structure and alignment. Therefore, in this work, we propose a scalable GNN-based entity alignment approach to reduce the structure and alignment loss from three perspectives. First, we propose a centrality-based subgraph generation algorithm to recall some landmark entities serving as the bridges between different subgraphs. Second, we introduce self-supervised entity reconstruction to recover entity representations from incomplete neighborhood subgraphs, and design cross-subgraph negative sampling to incorporate entities from other subgraphs in alignment learning. Third, during the inference process, we merge the embeddings of subgraphs to make a single space for alignment search. Experimental results on the benchmark OpenEA dataset and the proposed large DBpedia1M dataset verify the effectiveness of our approach.
RT-KGD: Relation Transition Aware Knowledge-Grounded Dialogue Generation
Jul 17, 2022

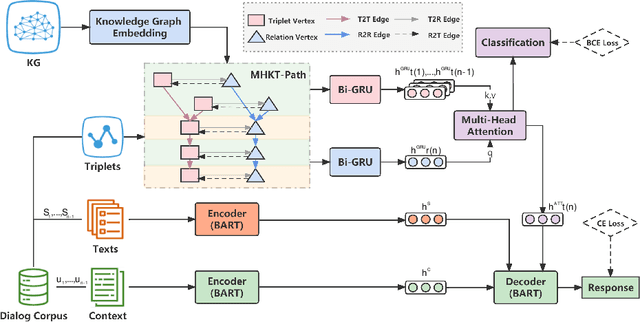

Grounding dialogue system with external knowledge is a promising way to improve the quality of responses. Most existing works adopt knowledge graphs (KGs) as the external resources, paying attention to the contribution of entities in the last utterance of the dialogue for context understanding and response generation. Nevertheless, the correlations between knowledge implied in the multi-turn context and the transition regularities between relations in KGs are under-explored. To this end, we propose a Relation Transition aware Knowledge-Grounded Dialogue Generation model (RT-KGD). Specifically, inspired by the latent logic of human conversation, our model integrates dialogue-level relation transition regularities with turn-level entity semantic information. In this manner, the interaction between knowledge is considered to produce abundant clues for predicting the appropriate knowledge and generating coherent responses. The experimental results on both automatic evaluation and manual evaluation indicate that our model outperforms state-of-the-art baselines.