 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRCTEA: Richness-guided Co-training for Temporal Entity Alignment
May 18, 2026Temporal Entity Alignment (TEA), which aims to identify equivalent entities across Temporal Knowledge Graphs (TKGs), is crucial for integrating knowledge facts from multiple sources. However, existing TEA models often fail to capture the orthogonal yet complementary effects between structural and temporal features, and typically overlook the importance of information richness, a key factor for effective message passing in neural feature encoders. To address these limitations, we propose the RCTEA framework, which jointly models both structural and temporal aspects of TKGs for entity alignment. Specifically, we design a richness-guided attention mechanism along with an adaptive weighting strategy to facilitate effective feature fusion. To ensure robust alignment despite noisy entity contexts, we introduce a dual-view neighborhood consensus algorithm that jointly refines the feature encoders to enforce local structural consistency of the predicted alignments. Extensive experiments demonstrate the superiority of RCTEA, achieving state-of-the-art performance on public TEA benchmarks.
Bridging Graph Structure and Knowledge-Guided Editing for Interpretable Temporal Knowledge Graph Reasoning
Jan 29, 2026Temporal knowledge graph reasoning (TKGR) aims to predict future events by inferring missing entities with dynamic knowledge structures. Existing LLM-based reasoning methods prioritize contextual over structural relations, struggling to extract relevant subgraphs from dynamic graphs. This limits structural information understanding, leading to unstructured, hallucination-prone inferences especially with temporal inconsistencies. To address this problem, we propose IGETR (Integration of Graph and Editing-enhanced Temporal Reasoning), a hybrid reasoning framework that combines the structured temporal modeling capabilities of Graph Neural Networks (GNNs) with the contextual understanding of LLMs. IGETR operates through a three-stage pipeline. The first stage aims to ground the reasoning process in the actual data by identifying structurally and temporally coherent candidate paths through a temporal GNN, ensuring that inference starts from reliable graph-based evidence. The second stage introduces LLM-guided path editing to address logical and semantic inconsistencies, leveraging external knowledge to refine and enhance the initial paths. The final stage focuses on integrating the refined reasoning paths to produce predictions that are both accurate and interpretable. Experiments on standard TKG benchmarks show that IGETR achieves state-of-the-art performance, outperforming strong baselines with relative improvements of up to 5.6% on Hits@1 and 8.1% on Hits@3 on the challenging ICEWS datasets. Additionally, we execute ablation studies and additional analyses confirm the effectiveness of each component.
Random Client Selection on Contrastive Federated Learning for Tabular Data
May 16, 2025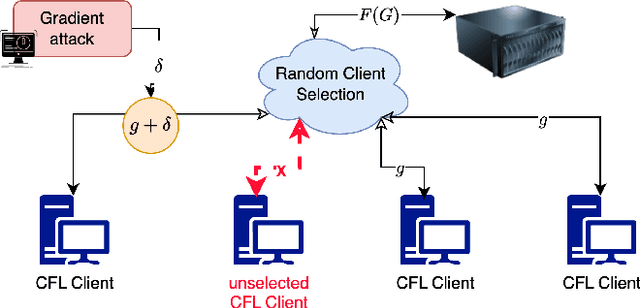
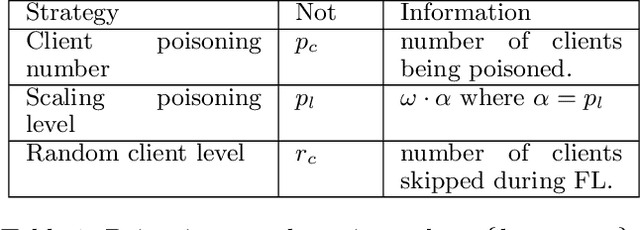
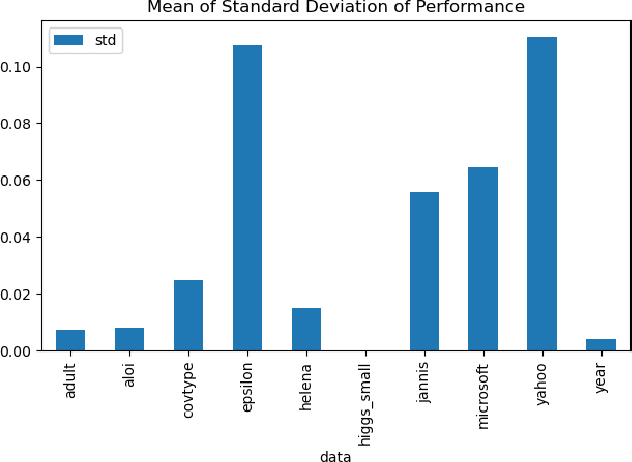
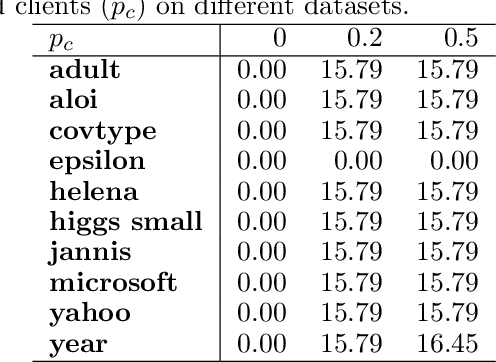
Vertical Federated Learning (VFL) has revolutionised collaborative machine learning by enabling privacy-preserving model training across multiple parties. However, it remains vulnerable to information leakage during intermediate computation sharing. While Contrastive Federated Learning (CFL) was introduced to mitigate these privacy concerns through representation learning, it still faces challenges from gradient-based attacks. This paper presents a comprehensive experimental analysis of gradient-based attacks in CFL environments and evaluates random client selection as a defensive strategy. Through extensive experimentation, we demonstrate that random client selection proves particularly effective in defending against gradient attacks in the CFL network. Our findings provide valuable insights for implementing robust security measures in contrastive federated learning systems, contributing to the development of more secure collaborative learning frameworks
Continual Contrastive Learning on Tabular Data with Out of Distribution
Mar 19, 2025Out-of-distribution (OOD) prediction remains a significant challenge in machine learning, particularly for tabular data where traditional methods often fail to generalize beyond their training distribution. This paper introduces Tabular Continual Contrastive Learning (TCCL), a novel framework designed to address OOD challenges in tabular data processing. TCCL integrates contrastive learning principles with continual learning mechanisms, featuring a three-component architecture: an Encoder for data transformation, a Decoder for representation learning, and a Learner Head. We evaluate TCCL against 14 baseline models, including state-of-the-art deep learning approaches and gradient-boosted decision trees (GBDT), across eight diverse tabular datasets. Our experimental results demonstrate that TCCL consistently outperforms existing methods in both classification and regression tasks on OOD data, with particular strength in handling distribution shifts. These findings suggest that TCCL represents a significant advancement in handling OOD scenarios for tabular data.
VaeDiff-DocRE: End-to-end Data Augmentation Framework for Document-level Relation Extraction
Dec 18, 2024



Document-level Relation Extraction (DocRE) aims to identify relationships between entity pairs within a document. However, most existing methods assume a uniform label distribution, resulting in suboptimal performance on real-world, imbalanced datasets. To tackle this challenge, we propose a novel data augmentation approach using generative models to enhance data from the embedding space. Our method leverages the Variational Autoencoder (VAE) architecture to capture all relation-wise distributions formed by entity pair representations and augment data for underrepresented relations. To better capture the multi-label nature of DocRE, we parameterize the VAE's latent space with a Diffusion Model. Additionally, we introduce a hierarchical training framework to integrate the proposed VAE-based augmentation module into DocRE systems. Experiments on two benchmark datasets demonstrate that our method outperforms state-of-the-art models, effectively addressing the long-tail distribution problem in DocRE.
Neuro-Symbolic Entity Alignment via Variational Inference
Oct 05, 2024



Entity alignment (EA) aims to merge two knowledge graphs (KGs) by identifying equivalent entity pairs. Existing methods can be categorized into symbolic and neural models. Symbolic models, while precise, struggle with substructure heterogeneity and sparsity, whereas neural models, although effective, generally lack interpretability and cannot handle uncertainty. We propose NeuSymEA, a probabilistic neuro-symbolic framework that combines the strengths of both methods. NeuSymEA models the joint probability of all possible pairs' truth scores in a Markov random field, regulated by a set of rules, and optimizes it with the variational EM algorithm. In the E-step, a neural model parameterizes the truth score distributions and infers missing alignments. In the M-step, the rule weights are updated based on the observed and inferred alignments. To facilitate interpretability, we further design a path-ranking-based explainer upon this framework that generates supporting rules for the inferred alignments. Experiments on benchmarks demonstrate that NeuSymEA not only significantly outperforms baselines in terms of effectiveness and robustness, but also provides interpretable results.
Contrastive Federated Learning with Tabular Data Silos
Sep 10, 2024Learning from data silos is a difficult task for organizations that need to obtain knowledge of objects that appeared in multiple independent data silos. Objects in multi-organizations, such as government agents, are referred by different identifiers, such as driver license, passport number, and tax file number. The data distributions in data silos are mostly non-IID (Independently and Identically Distributed), labelless, and vertically partitioned (i.e., having different attributes). Privacy concerns harden the above issues. Conditions inhibit enthusiasm for collaborative work. While Federated Learning (FL) has been proposed to address these issues, the difficulty of labeling, namely, label costliness, often hinders optimal model performance. A potential solution lies in contrastive learning, an unsupervised self-learning technique to represent semantic data by contrasting similar data pairs. However, contrastive learning is currently not designed to handle tabular data silos that existed within multiple organizations where data linkage by quasi identifiers are needed. To address these challenges, we propose using semi-supervised contrastive federated learning, which we refer to as Contrastive Federated Learning with Data Silos (CFL). Our approach tackles the aforementioned issues with an integrated solution. Our experimental results demonstrate that CFL outperforms current methods in addressing these challenges and providing improvements in accuracy. Additionally, we present positive results that showcase the advantages of our contrastive federated learning approach in complex client environments.
Entity Alignment with Noisy Annotations from Large Language Models
May 28, 2024Entity alignment (EA) aims to merge two knowledge graphs (KGs) by identifying equivalent entity pairs. While existing methods heavily rely on human-generated labels, it is prohibitively expensive to incorporate cross-domain experts for annotation in real-world scenarios. The advent of Large Language Models (LLMs) presents new avenues for automating EA with annotations, inspired by their comprehensive capability to process semantic information. However, it is nontrivial to directly apply LLMs for EA since the annotation space in real-world KGs is large. LLMs could also generate noisy labels that may mislead the alignment. To this end, we propose a unified framework, LLM4EA, to effectively leverage LLMs for EA. Specifically, we design a novel active learning policy to significantly reduce the annotation space by prioritizing the most valuable entities based on the entire inter-KG and intra-KG structure. Moreover, we introduce an unsupervised label refiner to continuously enhance label accuracy through in-depth probabilistic reasoning. We iteratively optimize the policy based on the feedback from a base EA model. Extensive experiments demonstrate the advantages of LLM4EA on four benchmark datasets in terms of effectiveness, robustness, and efficiency. Codes are available via https://github.com/chensyCN/llm4ea_official.
Improving the Robustness of Knowledge-Grounded Dialogue via Contrastive Learning
Jan 09, 2024Knowledge-grounded dialogue (KGD) learns to generate an informative response based on a given dialogue context and external knowledge (\emph{e.g.}, knowledge graphs; KGs). Recently, the emergence of large language models (LLMs) and pre-training techniques has brought great success to knowledge-grounded dialogue. However, when building KGD systems in real applications, there are various real-world noises that are inevitable to face. For example, the dialogue context might involve perturbations such as misspellings and abbreviations. In addition, KGs typically suffer from incompletion and also might contain erroneous and outdated facts. Such real-world noises pose a challenge to the robustness of KGD systems and hinder their applications in the real world. In this paper, we propose an entity-based contrastive learning framework for improving the robustness of KGD. Specifically, we make use of the entity information in a KGD sample to create both its positive and negative samples which involve semantic-irrelevant and semantic-relevant perturbations, respectively. The contrastive learning framework ensures the KGD model is aware of these two types of perturbations, thus generating informative responses with the potentially noisy inputs in real applications. Experimental results on three benchmark datasets show that our method achieves new state-of-the-art performance in terms of automatic evaluation scores, verifying its effectiveness and potentiality. Furthermore, we show that our method can generate better responses than comparison models in both the noisy and the few-shot settings.
Guiding Neural Entity Alignment with Compatibility
Nov 29, 2022



Entity Alignment (EA) aims to find equivalent entities between two Knowledge Graphs (KGs). While numerous neural EA models have been devised, they are mainly learned using labelled data only. In this work, we argue that different entities within one KG should have compatible counterparts in the other KG due to the potential dependencies among the entities. Making compatible predictions thus should be one of the goals of training an EA model along with fitting the labelled data: this aspect however is neglected in current methods. To power neural EA models with compatibility, we devise a training framework by addressing three problems: (1) how to measure the compatibility of an EA model; (2) how to inject the property of being compatible into an EA model; (3) how to optimise parameters of the compatibility model. Extensive experiments on widely-used datasets demonstrate the advantages of integrating compatibility within EA models. In fact, state-of-the-art neural EA models trained within our framework using just 5\% of the labelled data can achieve comparable effectiveness with supervised training using 20\% of the labelled data.