 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Reasoning Horizon in Entity Alignment Foundation Models
Jan 29, 2026Entity alignment (EA) is critical for knowledge graph (KG) fusion. Existing EA models lack transferability and are incapable of aligning unseen KGs without retraining. While using graph foundation models (GFMs) offer a solution, we find that directly adapting GFMs to EA remains largely ineffective. This stems from a critical "reasoning horizon gap": unlike link prediction in GFMs, EA necessitates capturing long-range dependencies across sparse and heterogeneous KG structuresTo address this challenge, we propose a EA foundation model driven by a parallel encoding strategy. We utilize seed EA pairs as local anchors to guide the information flow, initializing and encoding two parallel streams simultaneously. This facilitates anchor-conditioned message passing and significantly shortens the inference trajectory by leveraging local structural proximity instead of global search. Additionally, we incorporate a merged relation graph to model global dependencies and a learnable interaction module for precise matching. Extensive experiments verify the effectiveness of our framework, highlighting its strong generalizability to unseen KGs.
Gene-Metabolite Association Prediction with Interactive Knowledge Transfer Enhanced Graph for Metabolite Production
Oct 24, 2024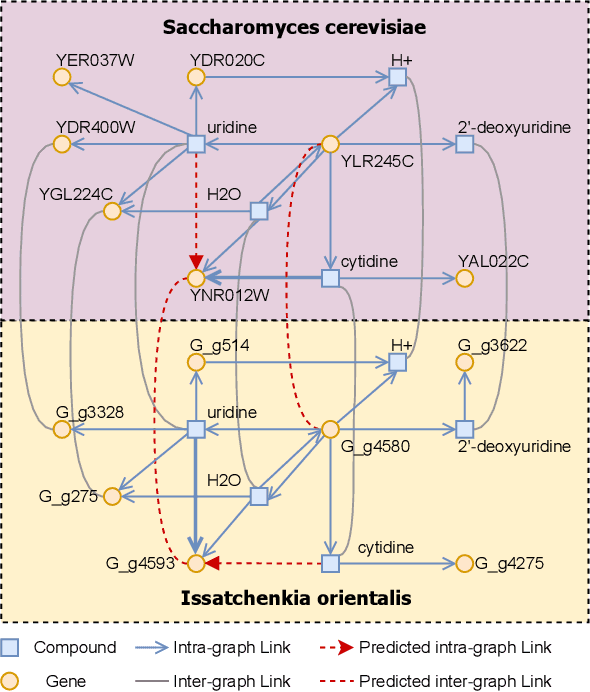
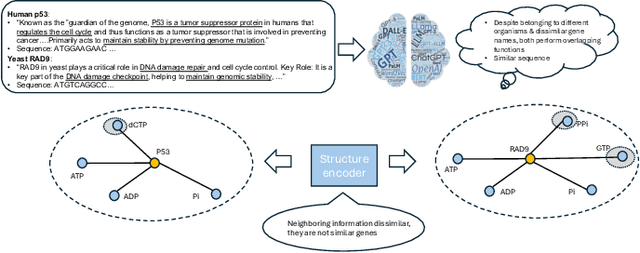
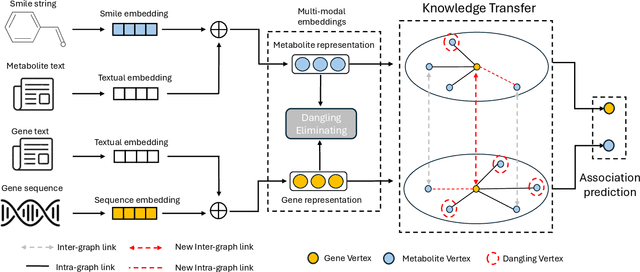
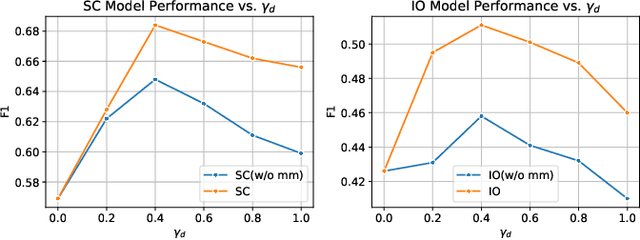
In the rapidly evolving field of metabolic engineering, the quest for efficient and precise gene target identification for metabolite production enhancement presents significant challenges. Traditional approaches, whether knowledge-based or model-based, are notably time-consuming and labor-intensive, due to the vast scale of research literature and the approximation nature of genome-scale metabolic model (GEM) simulations. Therefore, we propose a new task, Gene-Metabolite Association Prediction based on metabolic graphs, to automate the process of candidate gene discovery for a given pair of metabolite and candidate-associated genes, as well as presenting the first benchmark containing 2474 metabolites and 1947 genes of two commonly used microorganisms Saccharomyces cerevisiae (SC) and Issatchenkia orientalis (IO). This task is challenging due to the incompleteness of the metabolic graphs and the heterogeneity among distinct metabolisms. To overcome these limitations, we propose an Interactive Knowledge Transfer mechanism based on Metabolism Graph (IKT4Meta), which improves the association prediction accuracy by integrating the knowledge from different metabolism graphs. First, to build a bridge between two graphs for knowledge transfer, we utilize Pretrained Language Models (PLMs) with external knowledge of genes and metabolites to help generate inter-graph links, significantly alleviating the impact of heterogeneity. Second, we propagate intra-graph links from different metabolic graphs using inter-graph links as anchors. Finally, we conduct the gene-metabolite association prediction based on the enriched metabolism graphs, which integrate the knowledge from multiple microorganisms. Experiments on both types of organisms demonstrate that our proposed methodology outperforms baselines by up to 12.3% across various link prediction frameworks.
Large-scale Entity Alignment via Knowledge Graph Merging, Partitioning and Embedding
Aug 23, 2022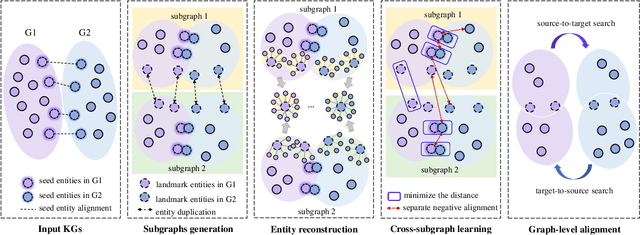
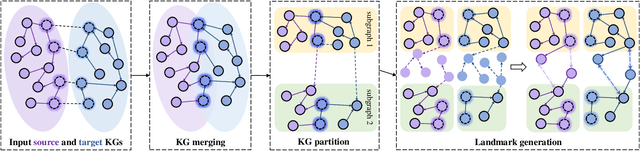

Entity alignment is a crucial task in knowledge graph fusion. However, most entity alignment approaches have the scalability problem. Recent methods address this issue by dividing large KGs into small blocks for embedding and alignment learning in each. However, such a partitioning and learning process results in an excessive loss of structure and alignment. Therefore, in this work, we propose a scalable GNN-based entity alignment approach to reduce the structure and alignment loss from three perspectives. First, we propose a centrality-based subgraph generation algorithm to recall some landmark entities serving as the bridges between different subgraphs. Second, we introduce self-supervised entity reconstruction to recover entity representations from incomplete neighborhood subgraphs, and design cross-subgraph negative sampling to incorporate entities from other subgraphs in alignment learning. Third, during the inference process, we merge the embeddings of subgraphs to make a single space for alignment search. Experimental results on the benchmark OpenEA dataset and the proposed large DBpedia1M dataset verify the effectiveness of our approach.
Ensemble Semi-supervised Entity Alignment via Cycle-teaching
Mar 12, 2022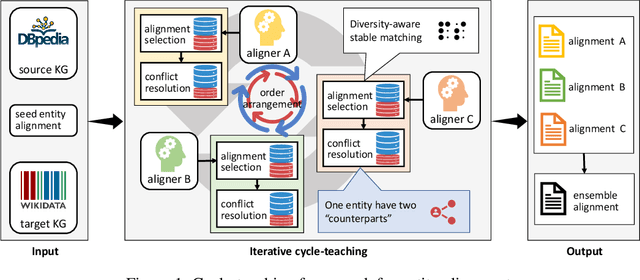

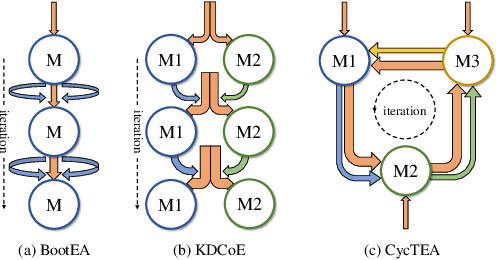

Entity alignment is to find identical entities in different knowledge graphs. Although embedding-based entity alignment has recently achieved remarkable progress, training data insufficiency remains a critical challenge. Conventional semi-supervised methods also suffer from the incorrect entity alignment in newly proposed training data. To resolve these issues, we design an iterative cycle-teaching framework for semi-supervised entity alignment. The key idea is to train multiple entity alignment models (called aligners) simultaneously and let each aligner iteratively teach its successor the proposed new entity alignment. We propose a diversity-aware alignment selection method to choose reliable entity alignment for each aligner. We also design a conflict resolution mechanism to resolve the alignment conflict when combining the new alignment of an aligner and that from its teacher. Besides, considering the influence of cycle-teaching order, we elaborately design a strategy to arrange the optimal order that can maximize the overall performance of multiple aligners. The cycle-teaching process can break the limitations of each model's learning capability and reduce the noise in new training data, leading to improved performance. Extensive experiments on benchmark datasets demonstrate the effectiveness of the proposed cycle-teaching framework, which significantly outperforms the state-of-the-art models when the training data is insufficient and the new entity alignment has much noise.
Informed Multi-context Entity Alignment
Jan 02, 2022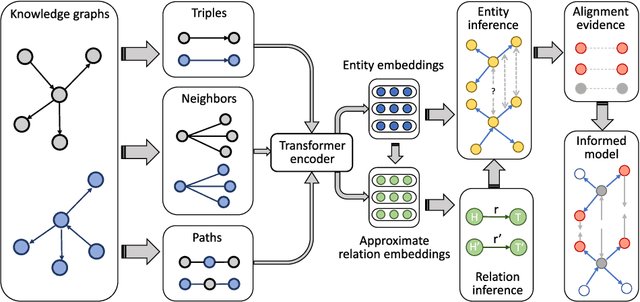
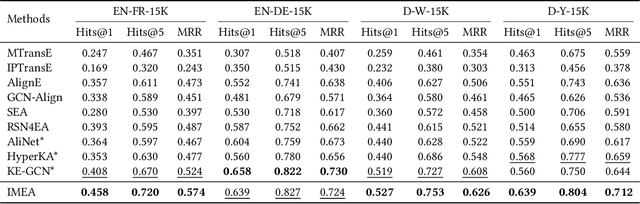
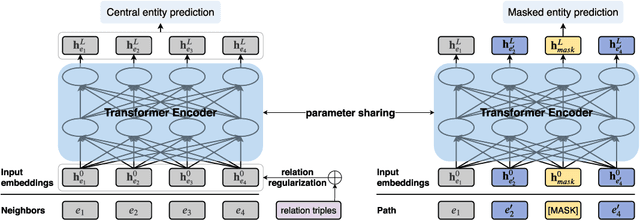

Entity alignment is a crucial step in integrating knowledge graphs (KGs) from multiple sources. Previous attempts at entity alignment have explored different KG structures, such as neighborhood-based and path-based contexts, to learn entity embeddings, but they are limited in capturing the multi-context features. Moreover, most approaches directly utilize the embedding similarity to determine entity alignment without considering the global interaction among entities and relations. In this work, we propose an Informed Multi-context Entity Alignment (IMEA) model to address these issues. In particular, we introduce Transformer to flexibly capture the relation, path, and neighborhood contexts, and design holistic reasoning to estimate alignment probabilities based on both embedding similarity and the relation/entity functionality. The alignment evidence obtained from holistic reasoning is further injected back into the Transformer via the proposed soft label editing to inform embedding learning. Experimental results on several benchmark datasets demonstrate the superiority of our IMEA model compared with existing state-of-the-art entity alignment methods.