 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Client Selection on Contrastive Federated Learning for Tabular Data
May 16, 2025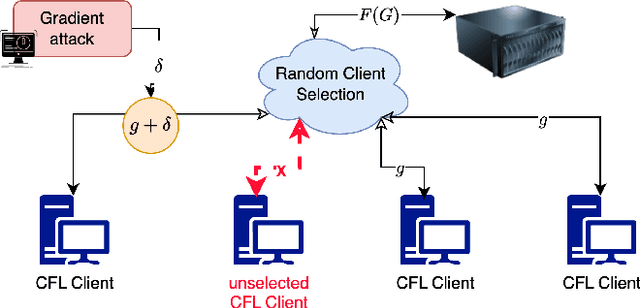
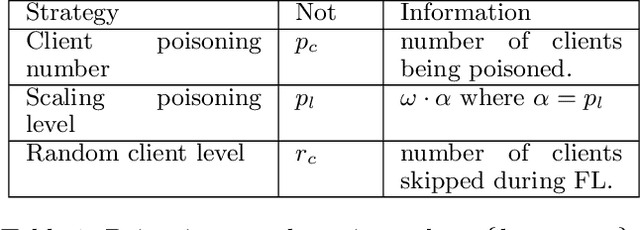
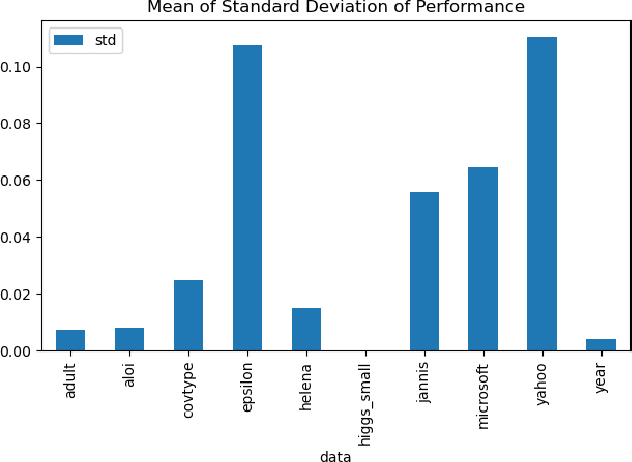
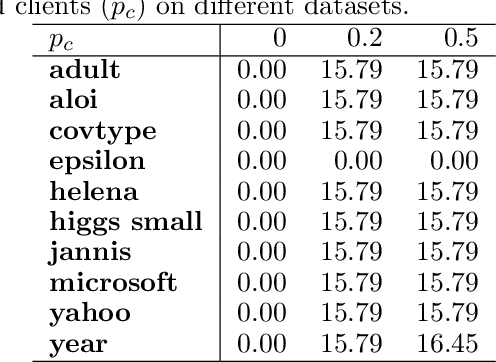
Vertical Federated Learning (VFL) has revolutionised collaborative machine learning by enabling privacy-preserving model training across multiple parties. However, it remains vulnerable to information leakage during intermediate computation sharing. While Contrastive Federated Learning (CFL) was introduced to mitigate these privacy concerns through representation learning, it still faces challenges from gradient-based attacks. This paper presents a comprehensive experimental analysis of gradient-based attacks in CFL environments and evaluates random client selection as a defensive strategy. Through extensive experimentation, we demonstrate that random client selection proves particularly effective in defending against gradient attacks in the CFL network. Our findings provide valuable insights for implementing robust security measures in contrastive federated learning systems, contributing to the development of more secure collaborative learning frameworks
Continual Contrastive Learning on Tabular Data with Out of Distribution
Mar 19, 2025Out-of-distribution (OOD) prediction remains a significant challenge in machine learning, particularly for tabular data where traditional methods often fail to generalize beyond their training distribution. This paper introduces Tabular Continual Contrastive Learning (TCCL), a novel framework designed to address OOD challenges in tabular data processing. TCCL integrates contrastive learning principles with continual learning mechanisms, featuring a three-component architecture: an Encoder for data transformation, a Decoder for representation learning, and a Learner Head. We evaluate TCCL against 14 baseline models, including state-of-the-art deep learning approaches and gradient-boosted decision trees (GBDT), across eight diverse tabular datasets. Our experimental results demonstrate that TCCL consistently outperforms existing methods in both classification and regression tasks on OOD data, with particular strength in handling distribution shifts. These findings suggest that TCCL represents a significant advancement in handling OOD scenarios for tabular data.
Contrastive Federated Learning with Tabular Data Silos
Sep 10, 2024Learning from data silos is a difficult task for organizations that need to obtain knowledge of objects that appeared in multiple independent data silos. Objects in multi-organizations, such as government agents, are referred by different identifiers, such as driver license, passport number, and tax file number. The data distributions in data silos are mostly non-IID (Independently and Identically Distributed), labelless, and vertically partitioned (i.e., having different attributes). Privacy concerns harden the above issues. Conditions inhibit enthusiasm for collaborative work. While Federated Learning (FL) has been proposed to address these issues, the difficulty of labeling, namely, label costliness, often hinders optimal model performance. A potential solution lies in contrastive learning, an unsupervised self-learning technique to represent semantic data by contrasting similar data pairs. However, contrastive learning is currently not designed to handle tabular data silos that existed within multiple organizations where data linkage by quasi identifiers are needed. To address these challenges, we propose using semi-supervised contrastive federated learning, which we refer to as Contrastive Federated Learning with Data Silos (CFL). Our approach tackles the aforementioned issues with an integrated solution. Our experimental results demonstrate that CFL outperforms current methods in addressing these challenges and providing improvements in accuracy. Additionally, we present positive results that showcase the advantages of our contrastive federated learning approach in complex client environments.