 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning and Unlearning for Recommendation with Personalized Data Sharing
Mar 12, 2026Federated recommender systems (FedRS) have emerged as a paradigm for protecting user privacy by keeping interaction data on local devices while coordinating model training through a central server. However, most existing federated recommender systems adopt a one-size-fits-all assumption on user privacy, where all users are required to keep their data strictly local. This setting overlooks users who are willing to share their data with the server in exchange for better recommendation performance. Although several recent studies have explored personalized user data sharing in FedRS, they assume static user privacy preferences and cannot handle user requests to remove previously shared data and its corresponding influence on the trained model. To address this limitation, we propose FedShare, a federated learn-unlearn framework for recommender systems with personalized user data sharing. FedShare not only allows users to control how much interaction data is shared with the server, but also supports data unsharing requests by removing the influence of the unshared data from the trained model. Specifically, FedShare leverages shared data to construct a server-side high-order user-item graph and uses contrastive learning to jointly align local and global representations. In the unlearning phase, we design a contrastive unlearning mechanism that selectively removes representations induced by the unshared data using a small number of historical embedding snapshots, avoiding the need to store large amounts of historical gradient information as required by existing federated recommendation unlearning methods. Extensive experiments on three public datasets demonstrate that FedShare achieves strong recommendation performance in both the learning and unlearning phases, while significantly reducing storage overhead in the unlearning phase compared with state-of-the-art baselines.
CADRL: Category-aware Dual-agent Reinforcement Learning for Explainable Recommendations over Knowledge Graphs
Aug 06, 2024



Knowledge graphs (KGs) have been widely adopted to mitigate data sparsity and address cold-start issues in recommender systems. While existing KGs-based recommendation methods can predict user preferences and demands, they fall short in generating explicit recommendation paths and lack explainability. As a step beyond the above methods, recent advancements utilize reinforcement learning (RL) to find suitable items for a given user via explainable recommendation paths. However, the performance of these solutions is still limited by the following two points. (1) Lack of ability to capture contextual dependencies from neighboring information. (2) The excessive reliance on short recommendation paths due to efficiency concerns. To surmount these challenges, we propose a category-aware dual-agent reinforcement learning (CADRL) model for explainable recommendations over KGs. Specifically, our model comprises two components: (1) a category-aware gated graph neural network that jointly captures context-aware item representations from neighboring entities and categories, and (2) a dual-agent RL framework where two agents efficiently traverse long paths to search for suitable items. Finally, experimental results show that CADRL outperforms state-of-the-art models in terms of both effectiveness and efficiency on large-scale datasets.
Do as I can, not as I get: Topology-aware multi-hop reasoning on multi-modal knowledge graphs
Jun 17, 2023



Multi-modal knowledge graph (MKG) includes triplets that consist of entities and relations and multi-modal auxiliary data. In recent years, multi-hop multi-modal knowledge graph reasoning (MMKGR) based on reinforcement learning (RL) has received extensive attention because it addresses the intrinsic incompleteness of MKG in an interpretable manner. However, its performance is limited by empirically designed rewards and sparse relations. In addition, this method has been designed for the transductive setting where test entities have been seen during training, and it works poorly in the inductive setting where test entities do not appear in the training set. To overcome these issues, we propose TMR (Topology-aware Multi-hop Reasoning), which can conduct MKG reasoning under inductive and transductive settings. Specifically, TMR mainly consists of two components. (1) The topology-aware inductive representation captures information from the directed relations of unseen entities, and aggregates query-related topology features in an attentive manner to generate the fine-grained entity-independent features. (2) After completing multi-modal feature fusion, the relation-augment adaptive RL conducts multi-hop reasoning by eliminating manual rewards and dynamically adding actions. Finally, we construct new MKG datasets with different scales for inductive reasoning evaluation. Experimental results demonstrate that TMP outperforms state-of-the-art MKGR methods under both inductive and transductive settings.
DREAM: Adaptive Reinforcement Learning based on Attention Mechanism for Temporal Knowledge Graph Reasoning
Apr 08, 2023Temporal knowledge graphs (TKGs) model the temporal evolution of events and have recently attracted increasing attention. Since TKGs are intrinsically incomplete, it is necessary to reason out missing elements. Although existing TKG reasoning methods have the ability to predict missing future events, they fail to generate explicit reasoning paths and lack explainability. As reinforcement learning (RL) for multi-hop reasoning on traditional knowledge graphs starts showing superior explainability and performance in recent advances, it has opened up opportunities for exploring RL techniques on TKG reasoning. However, the performance of RL-based TKG reasoning methods is limited due to: (1) lack of ability to capture temporal evolution and semantic dependence jointly; (2) excessive reliance on manually designed rewards. To overcome these challenges, we propose an adaptive reinforcement learning model based on attention mechanism (DREAM) to predict missing elements in the future. Specifically, the model contains two components: (1) a multi-faceted attention representation learning method that captures semantic dependence and temporal evolution jointly; (2) an adaptive RL framework that conducts multi-hop reasoning by adaptively learning the reward functions. Experimental results demonstrate DREAM outperforms state-of-the-art models on public dataset
MMKGR: Multi-hop Multi-modal Knowledge Graph Reasoning
Sep 03, 2022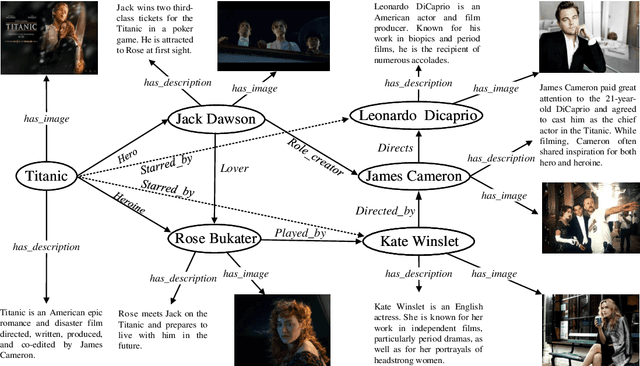
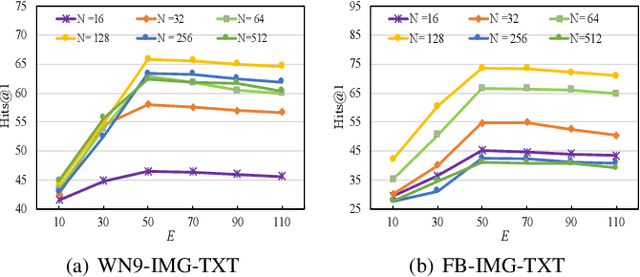
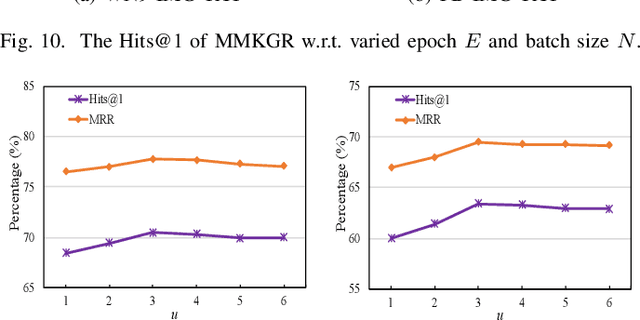
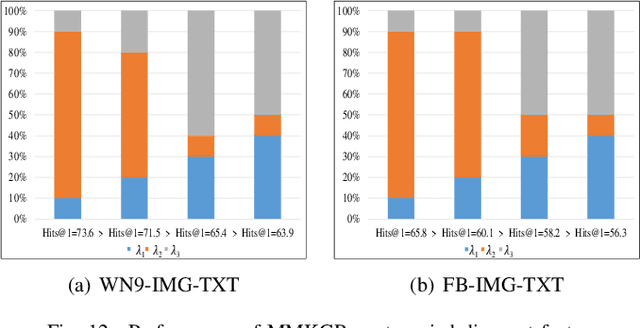
Multi-modal knowledge graphs (MKGs) include not only the relation triplets, but also related multi-modal auxiliary data (i.e., texts and images), which enhance the diversity of knowledge. However, the natural incompleteness has significantly hindered the applications of MKGs. To tackle the problem, existing studies employ the embedding-based reasoning models to infer the missing knowledge after fusing the multi-modal features. However, the reasoning performance of these methods is limited due to the following problems: (1) ineffective fusion of multi-modal auxiliary features; (2) lack of complex reasoning ability as well as inability to conduct the multi-hop reasoning which is able to infer more missing knowledge. To overcome these problems, we propose a novel model entitled MMKGR (Multi-hop Multi-modal Knowledge Graph Reasoning). Specifically, the model contains the following two components: (1) a unified gate-attention network which is designed to generate effective multi-modal complementary features through sufficient attention interaction and noise reduction; (2) a complementary feature-aware reinforcement learning method which is proposed to predict missing elements by performing the multi-hop reasoning process, based on the features obtained in component (1). The experimental results demonstrate that MMKGR outperforms the state-of-the-art approaches in the MKG reasoning task.