 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoE Enhanced Federated Learning for Spatiotemporal Prediction
Jun 09, 2026Traffic prediction is fundamental to intelligent transportation systems and urban computing, yet many cities continue to suffer from traffic data scarcity due to limited sensor deployment and uneven urban development. Cross-city knowledge transfer has thus attracted increasing attention, enabling data-rich cities to assist data-scarce ones. However, centralized approaches raise privacy concerns, while existing federated methods struggle with pronounced spatiotemporal heterogeneity across cities. To address these challenges, we propose MoE-FedTP, a personalized federated cross-city spatiotemporal prediction framework based on lightweight Mixture-of-Experts (MoE) networks. MoE-FedTP first employs spatiotemporal neural networks to extract features from both source and target cities, then introduces a set of expert networks derived from different source cities through partial parameter sharing. A gating mechanism dynamically fuses the experts to capture diverse traffic dynamics, achieving fine-grained modeling of urban heterogeneity while preserving privacy. Experiments on four real-world traffic datasets show that MoE-FedTP consistently outperforms state-of-the-art cross-city and federated learning baselines, demonstrating its effectiveness in enhancing prediction accuracy for data-scarce cities.
VISAFF: Speaker-Centered Visual Affective Feature Learning for Emotion Recognition in Conversation
May 18, 2026Emotion Recognition in Conversation (ERC) is essential for effective human-machine interaction, aiming to identify speakers' emotional states in multi-turn dialogues. Early text-based methods struggle with complex scenarios like sarcasm because they inherently neglect vital non-verbal information. While recent Vision-Language Models (VLMs) address this by analyzing video directly, they are not inherently tailored for ERC and often focus on emotionally irrelevant background regions or passive listeners rather than the active speaker. Furthermore, fine-tuning these large models incurs prohibitive computational costs. Additionally, isolated visual signals are frequently ambiguous or technically compromised without the context of linguistic content and vocal prosody. To address these challenges, we propose VISAFF, a speaker-centered VISual AFFective feature learning framework for ERC. VISAFF consists of two stages: Speaker-Centered Affective Grounding and Reliability-Guided Affective Complementation. VISAFF utilizes a tuning-free approach to unlock the reasoning capabilities of frozen VLMs, efficiently steering them to focus on the active speaker's emotional visual cues without heavy training overheads. In the second stage, we introduce a reliability-guided affective complementation mechanism that dynamically leverages textual and acoustic modalities to compensate for visual uncertainty. Experiments on two real-world datasets demonstrate that VISAFF achieves highly competitive performance compared to state-of-the-art methods in a tuning-free setting, significantly enhancing computational efficiency by eliminating the need for expensive fine-tuning of large VLMs. The source code is available at https://anonymous.4open.science/r/speaker-2365/.
VAE-REPA: Variational Autoencoder Representation Alignment for Efficient Diffusion Training
Jan 25, 2026Denoising-based diffusion transformers, despite their strong generation performance, suffer from inefficient training convergence. Existing methods addressing this issue, such as REPA (relying on external representation encoders) or SRA (requiring dual-model setups), inevitably incur heavy computational overhead during training due to external dependencies. To tackle these challenges, this paper proposes \textbf{\namex}, a lightweight intrinsic guidance framework for efficient diffusion training. \name leverages off-the-shelf pre-trained Variational Autoencoder (VAE) features: their reconstruction property ensures inherent encoding of visual priors like rich texture details, structural patterns, and basic semantic information. Specifically, \name aligns the intermediate latent features of diffusion transformers with VAE features via a lightweight projection layer, supervised by a feature alignment loss. This design accelerates training without extra representation encoders or dual-model maintenance, resulting in a simple yet effective pipeline. Extensive experiments demonstrate that \name improves both generation quality and training convergence speed compared to vanilla diffusion transformers, matches or outperforms state-of-the-art acceleration methods, and incurs merely 4\% extra GFLOPs with zero additional cost for external guidance models.
EduGuardBench: A Holistic Benchmark for Evaluating the Pedagogical Fidelity and Adversarial Safety of LLMs as Simulated Teachers
Nov 10, 2025Large Language Models for Simulating Professions (SP-LLMs), particularly as teachers, are pivotal for personalized education. However, ensuring their professional competence and ethical safety is a critical challenge, as existing benchmarks fail to measure role-playing fidelity or address the unique teaching harms inherent in educational scenarios. To address this, we propose EduGuardBench, a dual-component benchmark. It assesses professional fidelity using a Role-playing Fidelity Score (RFS) while diagnosing harms specific to the teaching profession. It also probes safety vulnerabilities using persona-based adversarial prompts targeting both general harms and, particularly, academic misconduct, evaluated with metrics including Attack Success Rate (ASR) and a three-tier Refusal Quality assessment. Our extensive experiments on 14 leading models reveal a stark polarization in performance. While reasoning-oriented models generally show superior fidelity, incompetence remains the dominant failure mode across most models. The adversarial tests uncovered a counterintuitive scaling paradox, where mid-sized models can be the most vulnerable, challenging monotonic safety assumptions. Critically, we identified a powerful Educational Transformation Effect: the safest models excel at converting harmful requests into teachable moments by providing ideal Educational Refusals. This capacity is strongly negatively correlated with ASR, revealing a new dimension of advanced AI safety. EduGuardBench thus provides a reproducible framework that moves beyond siloed knowledge tests toward a holistic assessment of professional, ethical, and pedagogical alignment, uncovering complex dynamics essential for deploying trustworthy AI in education. See https://github.com/YL1N/EduGuardBench for Materials.
Improving Region Representation Learning from Urban Imagery with Noisy Long-Caption Supervision
Nov 10, 2025Region representation learning plays a pivotal role in urban computing by extracting meaningful features from unlabeled urban data. Analogous to how perceived facial age reflects an individual's health, the visual appearance of a city serves as its ``portrait", encapsulating latent socio-economic and environmental characteristics. Recent studies have explored leveraging Large Language Models (LLMs) to incorporate textual knowledge into imagery-based urban region representation learning. However, two major challenges remain: i)~difficulty in aligning fine-grained visual features with long captions, and ii) suboptimal knowledge incorporation due to noise in LLM-generated captions. To address these issues, we propose a novel pre-training framework called UrbanLN that improves Urban region representation learning through Long-text awareness and Noise suppression. Specifically, we introduce an information-preserved stretching interpolation strategy that aligns long captions with fine-grained visual semantics in complex urban scenes. To effectively mine knowledge from LLM-generated captions and filter out noise, we propose a dual-level optimization strategy. At the data level, a multi-model collaboration pipeline automatically generates diverse and reliable captions without human intervention. At the model level, we employ a momentum-based self-distillation mechanism to generate stable pseudo-targets, facilitating robust cross-modal learning under noisy conditions. Extensive experiments across four real-world cities and various downstream tasks demonstrate the superior performance of our UrbanLN.
EMNLP: Educator-role Moral and Normative Large Language Models Profiling
Aug 21, 2025Simulating Professions (SP) enables Large Language Models (LLMs) to emulate professional roles. However, comprehensive psychological and ethical evaluation in these contexts remains lacking. This paper introduces EMNLP, an Educator-role Moral and Normative LLMs Profiling framework for personality profiling, moral development stage measurement, and ethical risk under soft prompt injection. EMNLP extends existing scales and constructs 88 teacher-specific moral dilemmas, enabling profession-oriented comparison with human teachers. A targeted soft prompt injection set evaluates compliance and vulnerability in teacher SP. Experiments on 12 LLMs show teacher-role LLMs exhibit more idealized and polarized personalities than human teachers, excel in abstract moral reasoning, but struggle with emotionally complex situations. Models with stronger reasoning are more vulnerable to harmful prompt injection, revealing a paradox between capability and safety. The model temperature and other hyperparameters have limited influence except in some risk behaviors. This paper presents the first benchmark to assess ethical and psychological alignment of teacher-role LLMs for educational AI. Resources are available at https://e-m-n-l-p.github.io/.
A Dataset for Spatiotemporal-Sensitive POI Question Answering
May 16, 2025Spatiotemporal relationships are critical in data science, as many prediction and reasoning tasks require analysis across both spatial and temporal dimensions--for instance, navigating an unfamiliar city involves planning itineraries that sequence locations and timing cultural experiences. However, existing Question-Answering (QA) datasets lack sufficient spatiotemporal-sensitive questions, making them inadequate benchmarks for evaluating models' spatiotemporal reasoning capabilities. To address this gap, we introduce POI-QA, a novel spatiotemporal-sensitive QA dataset centered on Point of Interest (POI), constructed through three key steps: mining and aligning open-source vehicle trajectory data from GAIA with high-precision geographic POI data, rigorous manual validation of noisy spatiotemporal facts, and generating bilingual (Chinese/English) QA pairs that reflect human-understandable spatiotemporal reasoning tasks. Our dataset challenges models to parse complex spatiotemporal dependencies, and evaluations of state-of-the-art multilingual LLMs (e.g., Qwen2.5-7B, Llama3.1-8B) reveal stark limitations: even the top-performing model (Qwen2.5-7B fine-tuned with RAG+LoRA) achieves a top 10 Hit Ratio (HR@10) of only 0.41 on the easiest task, far below human performance at 0.56. This underscores persistent weaknesses in LLMs' ability to perform consistent spatiotemporal reasoning, while highlighting POI-QA as a robust benchmark to advance algorithms sensitive to spatiotemporal dynamics. The dataset is publicly available at https://www.kaggle.com/ds/7394666.
Deep Learning for Time Series Forecasting: A Survey
Mar 13, 2025Time series forecasting (TSF) has long been a crucial task in both industry and daily life. Most classical statistical models may have certain limitations when applied to practical scenarios in fields such as energy, healthcare, traffic, meteorology, and economics, especially when high accuracy is required. With the continuous development of deep learning, numerous new models have emerged in the field of time series forecasting in recent years. However, existing surveys have not provided a unified summary of the wide range of model architectures in this field, nor have they given detailed summaries of works in feature extraction and datasets. To address this gap, in this review, we comprehensively study the previous works and summarize the general paradigms of Deep Time Series Forecasting (DTSF) in terms of model architectures. Besides, we take an innovative approach by focusing on the composition of time series and systematically explain important feature extraction methods. Additionally, we provide an overall compilation of datasets from various domains in existing works. Finally, we systematically emphasize the significant challenges faced and future research directions in this field.
GPT-Augmented Reinforcement Learning with Intelligent Control for Vehicle Dispatching
Aug 19, 2024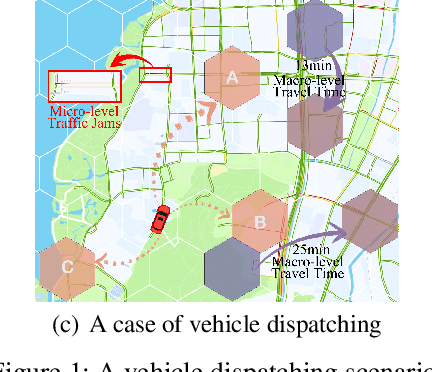

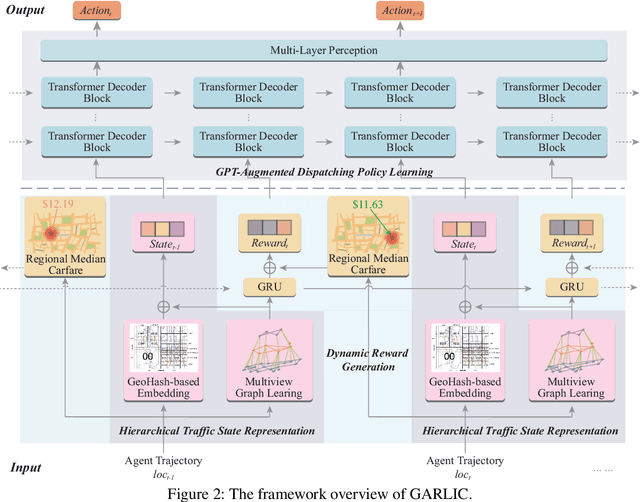
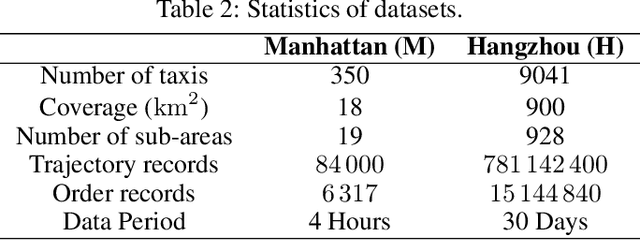
As urban residents demand higher travel quality, vehicle dispatch has become a critical component of online ride-hailing services. However, current vehicle dispatch systems struggle to navigate the complexities of urban traffic dynamics, including unpredictable traffic conditions, diverse driver behaviors, and fluctuating supply and demand patterns. These challenges have resulted in travel difficulties for passengers in certain areas, while many drivers in other areas are unable to secure orders, leading to a decline in the overall quality of urban transportation services. To address these issues, this paper introduces GARLIC: a framework of GPT-Augmented Reinforcement Learning with Intelligent Control for vehicle dispatching. GARLIC utilizes multiview graphs to capture hierarchical traffic states, and learns a dynamic reward function that accounts for individual driving behaviors. The framework further integrates a GPT model trained with a custom loss function to enable high-precision predictions and optimize dispatching policies in real-world scenarios. Experiments conducted on two real-world datasets demonstrate that GARLIC effectively aligns with driver behaviors while reducing the empty load rate of vehicles.
Pattern-Matching Dynamic Memory Network for Dual-Mode Traffic Prediction
Aug 12, 2024



In recent years, deep learning has increasingly gained attention in the field of traffic prediction. Existing traffic prediction models often rely on GCNs or attention mechanisms with O(N^2) complexity to dynamically extract traffic node features, which lack efficiency and are not lightweight. Additionally, these models typically only utilize historical data for prediction, without considering the impact of the target information on the prediction. To address these issues, we propose a Pattern-Matching Dynamic Memory Network (PM-DMNet). PM-DMNet employs a novel dynamic memory network to capture traffic pattern features with only O(N) complexity, significantly reducing computational overhead while achieving excellent performance. The PM-DMNet also introduces two prediction methods: Recursive Multi-step Prediction (RMP) and Parallel Multi-step Prediction (PMP), which leverage the time features of the prediction targets to assist in the forecasting process. Furthermore, a transfer attention mechanism is integrated into PMP, transforming historical data features to better align with the predicted target states, thereby capturing trend changes more accurately and reducing errors. Extensive experiments demonstrate the superiority of the proposed model over existing benchmarks. The source codes are available at: https://github.com/wengwenchao123/PM-DMNet.