 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs ChatGPT a Good NLG Evaluator? A Preliminary Study
Paper and Code
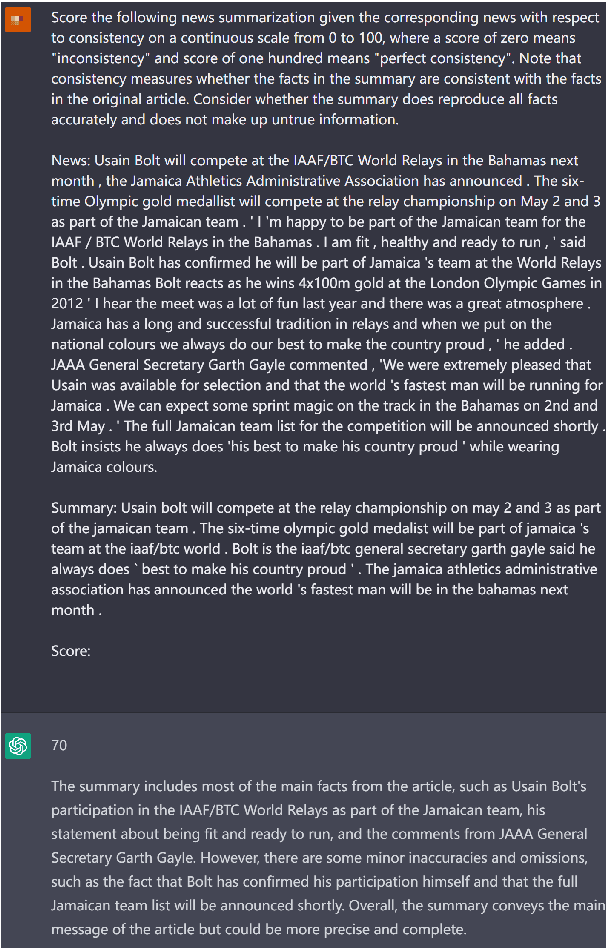
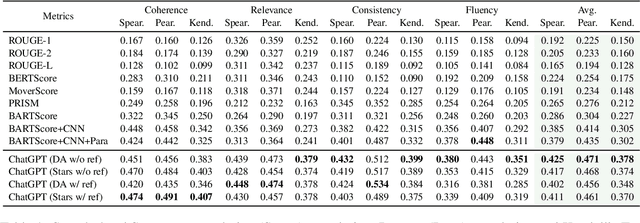

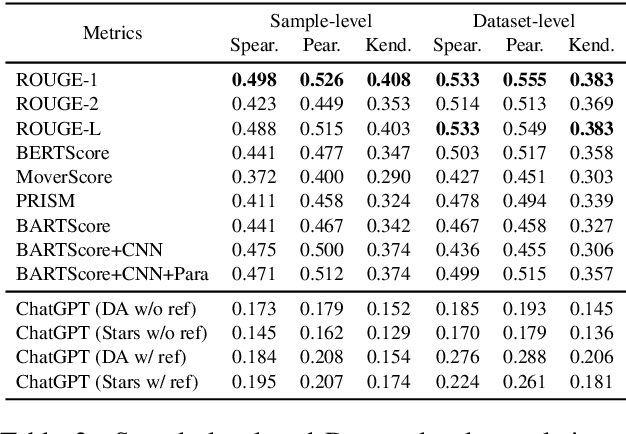
Recently, the emergence of ChatGPT has attracted wide attention from the computational linguistics community. Many prior studies have shown that ChatGPT achieves remarkable performance on various NLP tasks in terms of automatic evaluation metrics. However, the ability of ChatGPT to serve as an evaluation metric is still underexplored. Considering assessing the quality of NLG models is an arduous task and previous statistical metrics notoriously show their poor correlation with human judgments, we wonder whether ChatGPT is a good NLG evaluation metric. In this report, we provide a preliminary meta-evaluation on ChatGPT to show its reliability as an NLG metric. In detail, we regard ChatGPT as a human evaluator and give task-specific (e.g., summarization) and aspect-specific (e.g., relevance) instruction to prompt ChatGPT to score the generation of NLG models. We conduct experiments on three widely-used NLG meta-evaluation datasets (including summarization, story generation and data-to-text tasks). Experimental results show that compared with previous automatic metrics, ChatGPT achieves state-of-the-art or competitive correlation with golden human judgments. We hope our preliminary study could prompt the emergence of a general-purposed reliable NLG metric.