 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Unifying Multi-Lingual and Cross-Lingual Summarization
Paper and Code

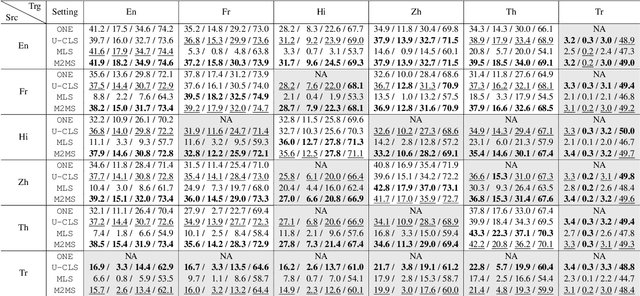


To adapt text summarization to the multilingual world, previous work proposes multi-lingual summarization (MLS) and cross-lingual summarization (CLS). However, these two tasks have been studied separately due to the different definitions, which limits the compatible and systematic research on both of them. In this paper, we aim to unify MLS and CLS into a more general setting, i.e., many-to-many summarization (M2MS), where a single model could process documents in any language and generate their summaries also in any language. As the first step towards M2MS, we conduct preliminary studies to show that M2MS can better transfer task knowledge across different languages than MLS and CLS. Furthermore, we propose Pisces, a pre-trained M2MS model that learns language modeling, cross-lingual ability and summarization ability via three-stage pre-training. Experimental results indicate that our Pisces significantly outperforms the state-of-the-art baselines, especially in the zero-shot directions, where there is no training data from the source-language documents to the target-language summaries.