 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedCRF: A Federated Cross-domain Recommendation Method with Semantic-driven Deep Knowledge Fusion
Apr 20, 2026As user behavior data becomes increasingly scattered across different platforms, achieving cross-domain knowledge fusion while preserving privacy has become a critical issue in recommender systems. Existing PPCDR methods usually rely on overlapping users or items as a bridge, making them inapplicable to non-overlapping scenarios. They also suffer from limitations in the collaborative modeling of global and local semantics. To this end, this paper proposes a Federated Cross-domain Recommendation method with deep knowledge Fusion (FedCRF). Using textual semantics as a cross-domain bridge, FedCRF achieves cross-domain knowledge transfer via federated semantic learning under the non-overlapping scenario. Specifically, FedCRF constructs global semantic clusters on the server side to extract shared semantic information, and designs a FGSAT module on the client side to dynamically adapt to local data distributions and alleviate cross-domain distribution shift. Meanwhile, it builds a semantic graph based on textual features to learn representations that integrate both structural and semantic information, and introduces contrastive learning constraints between global and local semantic representations to enhance semantic consistency and promote deep knowledge fusion. In this framework, only item semantic representations are shared, while user interaction data remains locally stored, effectively mitigating privacy leakage risks. Experimental results on multiple real-world datasets show that FedCRF significantly outperforms existing methods in terms of Recall@20 and NDCG@20, validating its effectiveness and superiority in non-overlapping cross-domain recommendation scenarios.
Federated Semantic Learning for Privacy-preserving Cross-domain Recommendation
Mar 29, 2025In the evolving landscape of recommender systems, the challenge of effectively conducting privacy-preserving Cross-Domain Recommendation (CDR), especially under strict non-overlapping constraints, has emerged as a key focus. Despite extensive research has made significant progress, several limitations still exist: 1) Previous semantic-based methods fail to deeply exploit rich textual information, since they quantize the text into codes, losing its original rich semantics. 2) The current solution solely relies on the text-modality, while the synergistic effects with the ID-modality are ignored. 3) Existing studies do not consider the impact of irrelevant semantic features, leading to inaccurate semantic representation. To address these challenges, we introduce federated semantic learning and devise FFMSR as our solution. For Limitation 1, we locally learn items'semantic encodings from their original texts by a multi-layer semantic encoder, and then cluster them on the server to facilitate the transfer of semantic knowledge between domains. To tackle Limitation 2, we integrate both ID and Text modalities on the clients, and utilize them to learn different aspects of items. To handle Limitation 3, a Fast Fourier Transform (FFT)-based filter and a gating mechanism are developed to alleviate the impact of irrelevant semantic information in the local model. We conduct extensive experiments on two real-world datasets, and the results demonstrate the superiority of our FFMSR method over other SOTA methods. Our source codes are publicly available at: https://github.com/Sapphire-star/FFMSR.
Unveiling Context-Related Anomalies: Knowledge Graph Empowered Decoupling of Scene and Action for Human-Related Video Anomaly Detection
Sep 05, 2024Detecting anomalies in human-related videos is crucial for surveillance applications. Current methods primarily include appearance-based and action-based techniques. Appearance-based methods rely on low-level visual features such as color, texture, and shape. They learn a large number of pixel patterns and features related to known scenes during training, making them effective in detecting anomalies within these familiar contexts. However, when encountering new or significantly changed scenes, i.e., unknown scenes, they often fail because existing SOTA methods do not effectively capture the relationship between actions and their surrounding scenes, resulting in low generalization. In contrast, action-based methods focus on detecting anomalies in human actions but are usually less informative because they tend to overlook the relationship between actions and their scenes, leading to incorrect detection. For instance, the normal event of running on the beach and the abnormal event of running on the street might both be considered normal due to the lack of scene information. In short, current methods struggle to integrate low-level visual and high-level action features, leading to poor anomaly detection in varied and complex scenes. To address this challenge, we propose a novel decoupling-based architecture for human-related video anomaly detection (DecoAD). DecoAD significantly improves the integration of visual and action features through the decoupling and interweaving of scenes and actions, thereby enabling a more intuitive and accurate understanding of complex behaviors and scenes. DecoAD supports fully supervised, weakly supervised, and unsupervised settings.
Behavior Pattern Mining-based Multi-Behavior Recommendation
Aug 22, 2024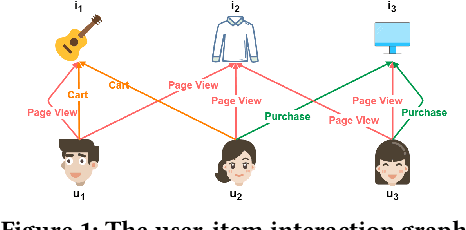
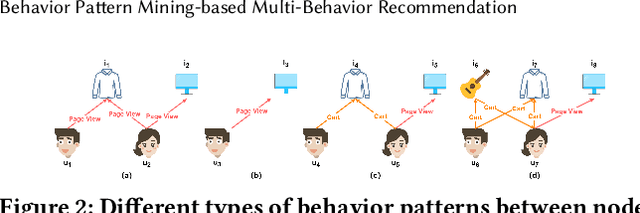
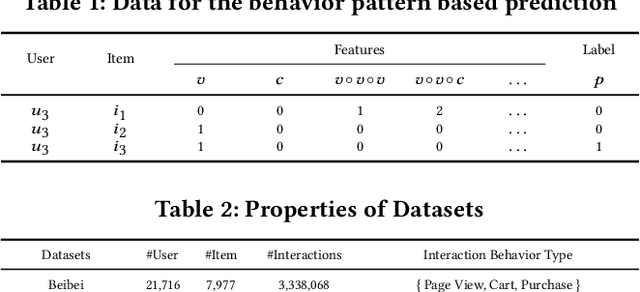
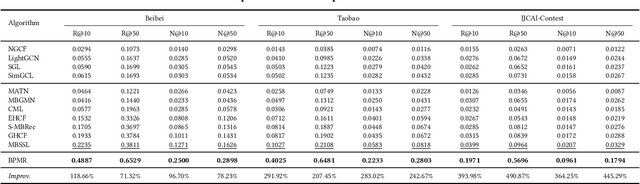
Multi-behavior recommendation systems enhance effectiveness by leveraging auxiliary behaviors (such as page views and favorites) to address the limitations of traditional models that depend solely on sparse target behaviors like purchases. Existing approaches to multi-behavior recommendations typically follow one of two strategies: some derive initial node representations from individual behavior subgraphs before integrating them for a comprehensive profile, while others interpret multi-behavior data as a heterogeneous graph, applying graph neural networks to achieve a unified node representation. However, these methods do not adequately explore the intricate patterns of behavior among users and items. To bridge this gap, we introduce a novel algorithm called Behavior Pattern mining-based Multi-behavior Recommendation (BPMR). Our method extensively investigates the diverse interaction patterns between users and items, utilizing these patterns as features for making recommendations. We employ a Bayesian approach to streamline the recommendation process, effectively circumventing the challenges posed by graph neural network algorithms, such as the inability to accurately capture user preferences due to over-smoothing. Our experimental evaluation on three real-world datasets demonstrates that BPMR significantly outperforms existing state-of-the-art algorithms, showing an average improvement of 268.29% in Recall@10 and 248.02% in NDCG@10 metrics. The code of our BPMR is openly accessible for use and further research at https://github.com/rookitkitlee/BPMR.
Amplify Graph Learning for Recommendation via Sparsity Completion
Jun 27, 2024



Graph learning models have been widely deployed in collaborative filtering (CF) based recommendation systems. Due to the issue of data sparsity, the graph structure of the original input lacks potential positive preference edges, which significantly reduces the performance of recommendations. In this paper, we study how to enhance the graph structure for CF more effectively, thereby optimizing the representation of graph nodes. Previous works introduced matrix completion techniques into CF, proposing the use of either stochastic completion methods or superficial structure completion to address this issue. However, most of these approaches employ random numerical filling that lack control over noise perturbations and limit the in-depth exploration of higher-order interaction features of nodes, resulting in biased graph representations. In this paper, we propose an Amplify Graph Learning framework based on Sparsity Completion (called AGL-SC). First, we utilize graph neural network to mine direct interaction features between user and item nodes, which are used as the inputs of the encoder. Second, we design a factorization-based method to mine higher-order interaction features. These features serve as perturbation factors in the latent space of the hidden layer to facilitate generative enhancement. Finally, by employing the variational inference, the above multi-order features are integrated to implement the completion and enhancement of missing graph structures. We conducted benchmark and strategy experiments on four real-world datasets related to recommendation tasks. The experimental results demonstrate that AGL-SC significantly outperforms the state-of-the-art methods.
HRLAIF: Improvements in Helpfulness and Harmlessness in Open-domain Reinforcement Learning From AI Feedback
Mar 14, 2024



Reinforcement Learning from AI Feedback (RLAIF) has the advantages of shorter annotation cycles and lower costs over Reinforcement Learning from Human Feedback (RLHF), making it highly efficient during the rapid strategy iteration periods of large language model (LLM) training. Using ChatGPT as a labeler to provide feedback on open-domain prompts in RLAIF training, we observe an increase in human evaluators' preference win ratio for model responses, but a decrease in evaluators' satisfaction rate. Analysis suggests that the decrease in satisfaction rate is mainly due to some responses becoming less helpful, particularly in terms of correctness and truthfulness, highlighting practical limitations of basic RLAIF. In this paper, we propose Hybrid Reinforcement Learning from AI Feedback (HRLAIF). This method enhances the accuracy of AI annotations for responses, making the model's helpfulness more robust in training process. Additionally, it employs AI for Red Teaming, further improving the model's harmlessness. Human evaluation results show that HRLAIF inherits the ability of RLAIF to enhance human preference for outcomes at a low cost while also improving the satisfaction rate of responses. Compared to the policy model before Reinforcement Learning (RL), it achieves an increase of 2.08\% in satisfaction rate, effectively addressing the issue of a decrease of 4.58\% in satisfaction rate after basic RLAIF.