 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink in Sentences: Explicit Sentence Boundaries Enhance Language Model's Capabilities
Apr 11, 2026Researchers have explored different ways to improve large language models (LLMs)' capabilities via dummy token insertion in contexts. However, existing works focus solely on the dummy tokens themselves, but fail to leverage the inherent sentence-level structure of natural language. This is a critical oversight, as LLMs acquire linguistic capabilities through exposure to human-generated texts, which are inherently structured at the sentence level. Motivated by this gap, we propose an approach that inserts delimiters at sentence boundaries in LLM inputs, which not only integrates dummy tokens into the context, but also facilitates LLMs with sentence-by-sentence processing behavior during reasoning. Two concrete methods: (1). In-context learning and (2). Supervised fine-tuning are experimented using 7B models to 600B Deepseek-V3. Our results demonstrate consistent improvements across various tasks, with notable gains of up to 7.7\% on GSM8k and 12.5\% on DROP. Furthermore, the fine-tuned LLMs can incorporate sentence awareness evidenced by their internal representations. Our work establishes a simple yet effective technique for enhancing LLM's capabilities, offering promising directions for cognitive-inspired LLM enhancement paradigm.
Detecting Subtle Differences between Human and Model Languages Using Spectrum of Relative Likelihood
Jun 28, 2024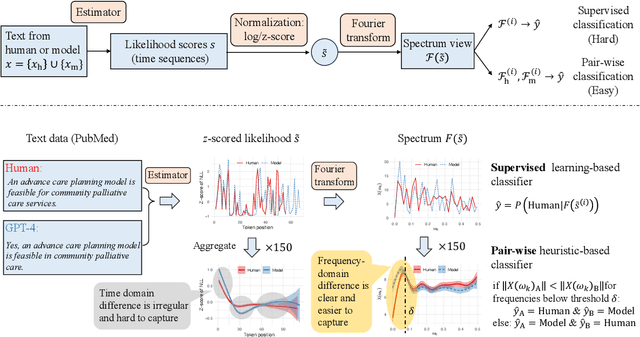
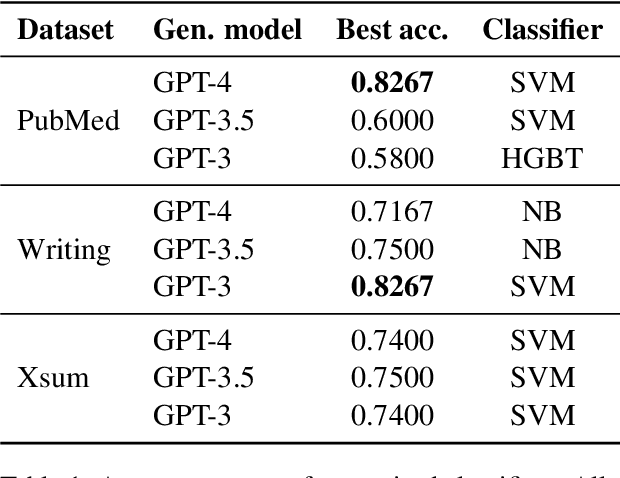
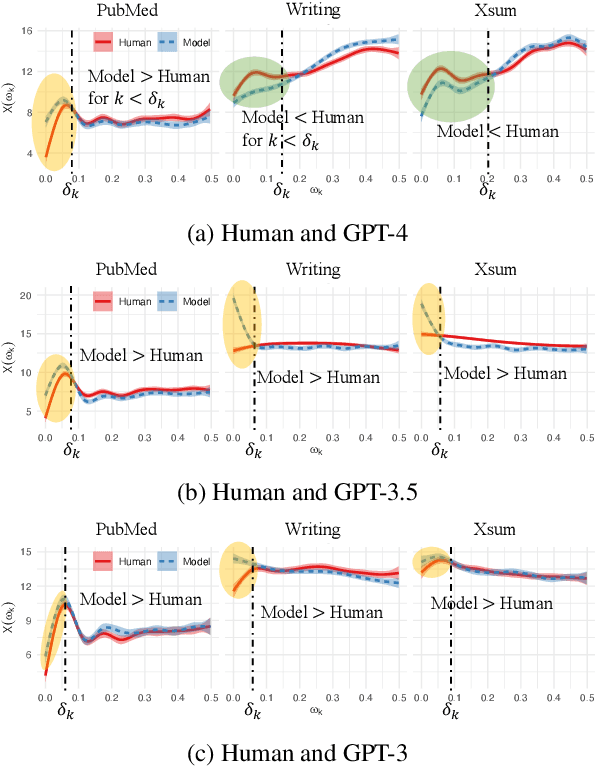
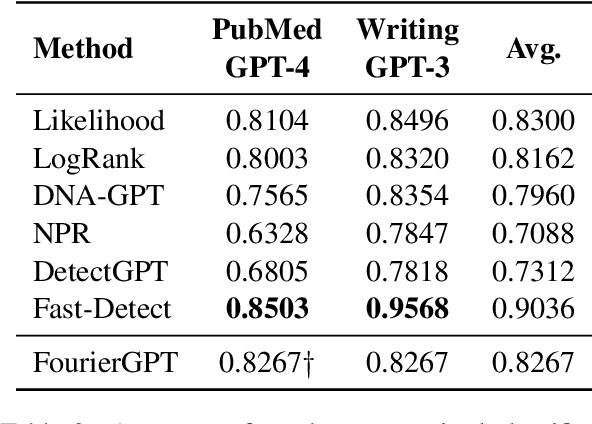
Human and model-generated texts can be distinguished by examining the magnitude of likelihood in language. However, it is becoming increasingly difficult as language model's capabilities of generating human-like texts keep evolving. This study provides a new perspective by using the relative likelihood values instead of absolute ones, and extracting useful features from the spectrum-view of likelihood for the human-model text detection task. We propose a detection procedure with two classification methods, supervised and heuristic-based, respectively, which results in competitive performances with previous zero-shot detection methods and a new state-of-the-art on short-text detection. Our method can also reveal subtle differences between human and model languages, which find theoretical roots in psycholinguistics studies. Our code is available at https://github.com/CLCS-SUSTech/FourierGPT
HDTR-Net: A Real-Time High-Definition Teeth Restoration Network for Arbitrary Talking Face Generation Methods
Sep 14, 2023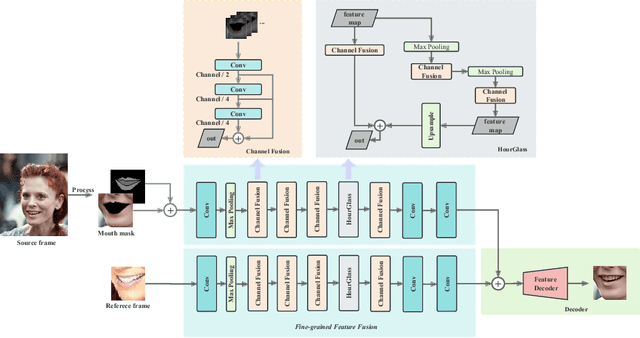
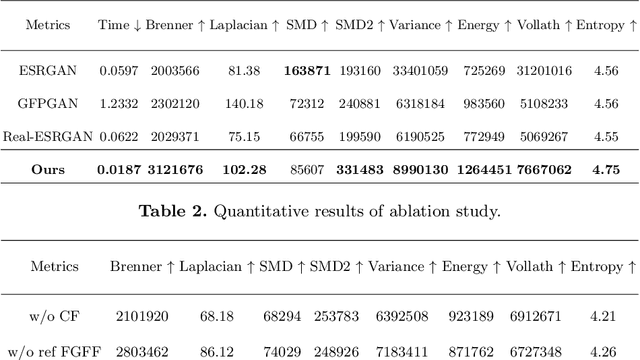
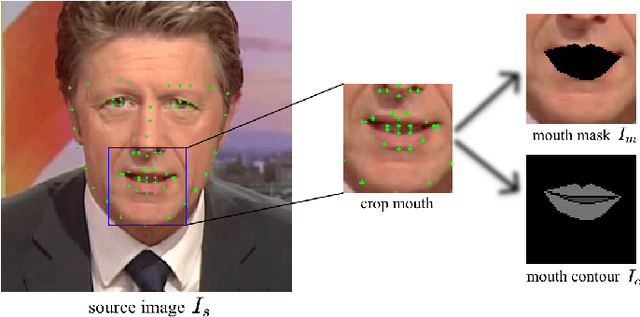
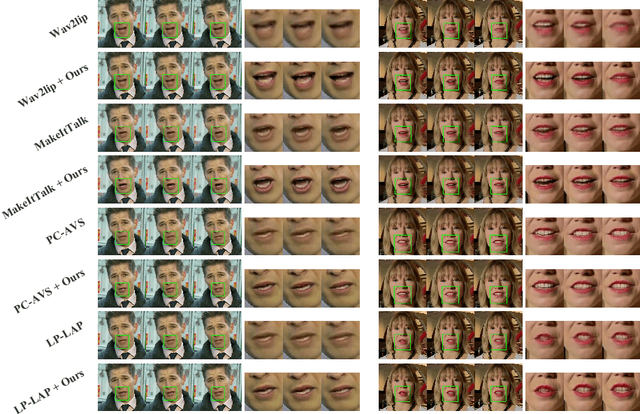
Talking Face Generation (TFG) aims to reconstruct facial movements to achieve high natural lip movements from audio and facial features that are under potential connections. Existing TFG methods have made significant advancements to produce natural and realistic images. However, most work rarely takes visual quality into consideration. It is challenging to ensure lip synchronization while avoiding visual quality degradation in cross-modal generation methods. To address this issue, we propose a universal High-Definition Teeth Restoration Network, dubbed HDTR-Net, for arbitrary TFG methods. HDTR-Net can enhance teeth regions at an extremely fast speed while maintaining synchronization, and temporal consistency. In particular, we propose a Fine-Grained Feature Fusion (FGFF) module to effectively capture fine texture feature information around teeth and surrounding regions, and use these features to fine-grain the feature map to enhance the clarity of teeth. Extensive experiments show that our method can be adapted to arbitrary TFG methods without suffering from lip synchronization and frame coherence. Another advantage of HDTR-Net is its real-time generation ability. Also under the condition of high-definition restoration of talking face video synthesis, its inference speed is $300\%$ faster than the current state-of-the-art face restoration based on super-resolution.