 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffuMural: Restoring Dunhuang Murals with Multi-scale Diffusion
Apr 13, 2025Large-scale pre-trained diffusion models have produced excellent results in the field of conditional image generation. However, restoration of ancient murals, as an important downstream task in this field, poses significant challenges to diffusion model-based restoration methods due to its large defective area and scarce training samples. Conditional restoration tasks are more concerned with whether the restored part meets the aesthetic standards of mural restoration in terms of overall style and seam detail, and such metrics for evaluating heuristic image complements are lacking in current research. We therefore propose DiffuMural, a combined Multi-scale convergence and Collaborative Diffusion mechanism with ControlNet and cyclic consistency loss to optimise the matching between the generated images and the conditional control. DiffuMural demonstrates outstanding capabilities in mural restoration, leveraging training data from 23 large-scale Dunhuang murals that exhibit consistent visual aesthetics. The model excels in restoring intricate details, achieving a coherent overall appearance, and addressing the unique challenges posed by incomplete murals lacking factual grounding. Our evaluation framework incorporates four key metrics to quantitatively assess incomplete murals: factual accuracy, textural detail, contextual semantics, and holistic visual coherence. Furthermore, we integrate humanistic value assessments to ensure the restored murals retain their cultural and artistic significance. Extensive experiments validate that our method outperforms state-of-the-art (SOTA) approaches in both qualitative and quantitative metrics.
Detecting Subtle Differences between Human and Model Languages Using Spectrum of Relative Likelihood
Jun 28, 2024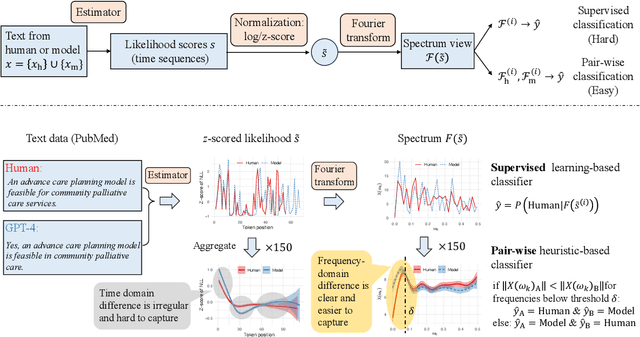
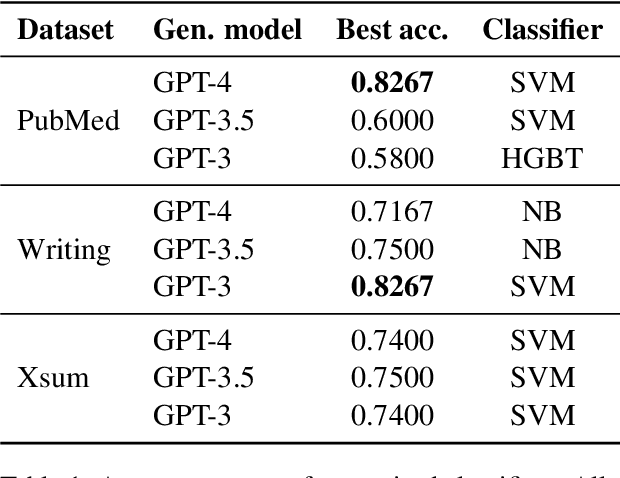
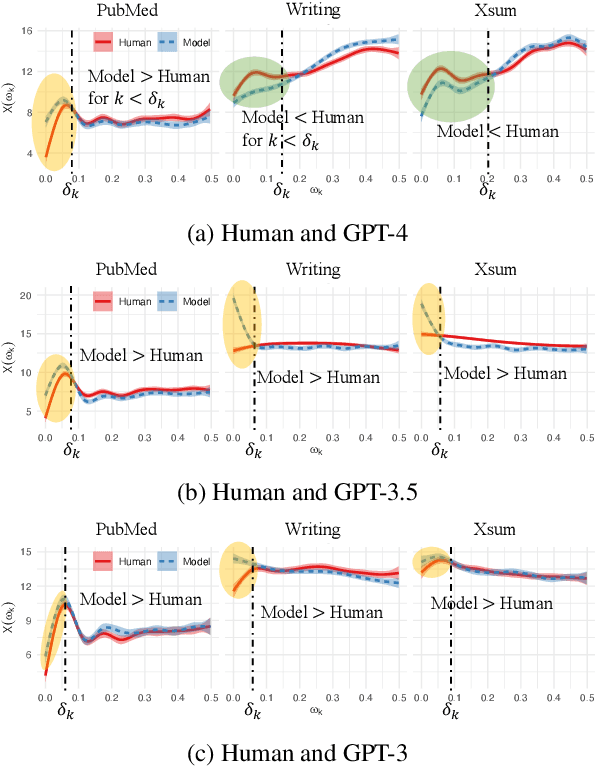
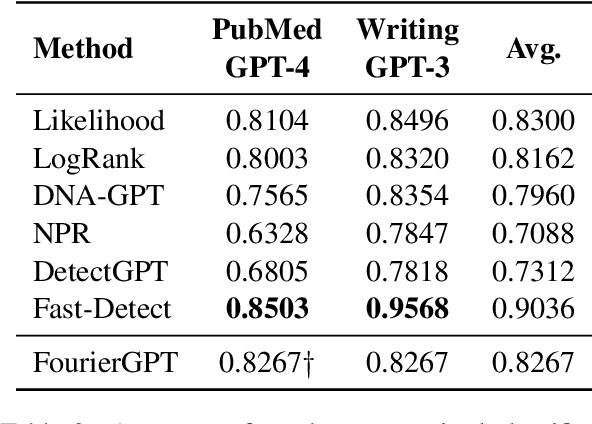
Human and model-generated texts can be distinguished by examining the magnitude of likelihood in language. However, it is becoming increasingly difficult as language model's capabilities of generating human-like texts keep evolving. This study provides a new perspective by using the relative likelihood values instead of absolute ones, and extracting useful features from the spectrum-view of likelihood for the human-model text detection task. We propose a detection procedure with two classification methods, supervised and heuristic-based, respectively, which results in competitive performances with previous zero-shot detection methods and a new state-of-the-art on short-text detection. Our method can also reveal subtle differences between human and model languages, which find theoretical roots in psycholinguistics studies. Our code is available at https://github.com/CLCS-SUSTech/FourierGPT