 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHDTR-Net: A Real-Time High-Definition Teeth Restoration Network for Arbitrary Talking Face Generation Methods
Paper and Code
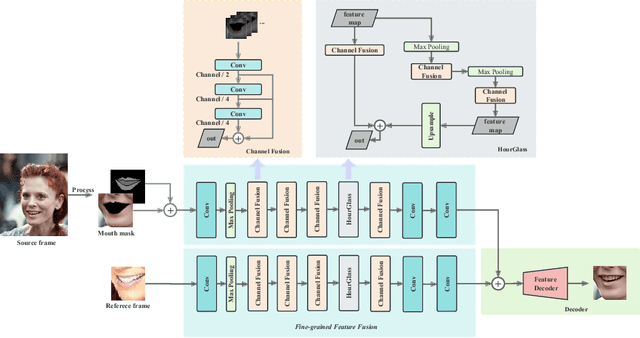
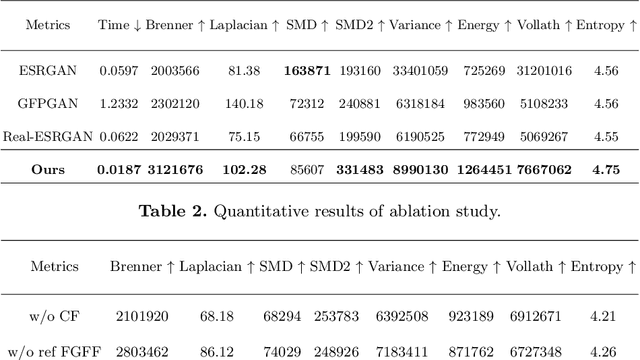
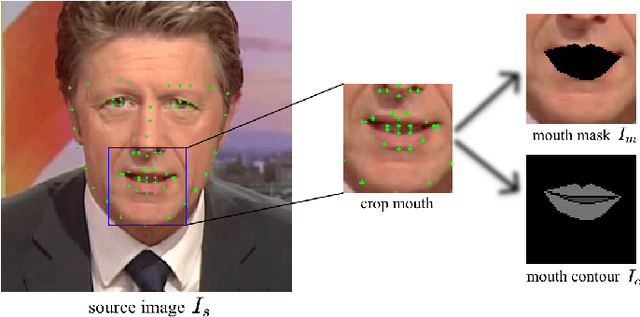
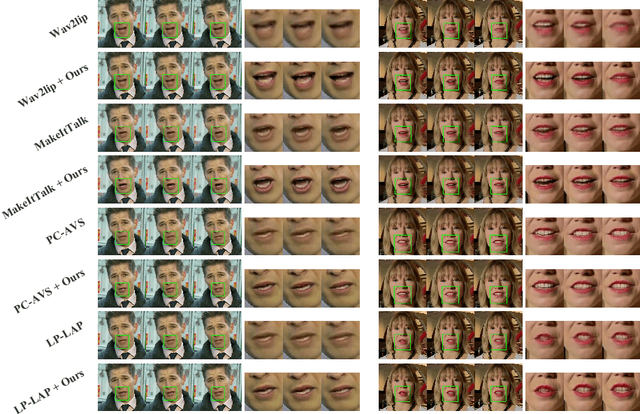
Talking Face Generation (TFG) aims to reconstruct facial movements to achieve high natural lip movements from audio and facial features that are under potential connections. Existing TFG methods have made significant advancements to produce natural and realistic images. However, most work rarely takes visual quality into consideration. It is challenging to ensure lip synchronization while avoiding visual quality degradation in cross-modal generation methods. To address this issue, we propose a universal High-Definition Teeth Restoration Network, dubbed HDTR-Net, for arbitrary TFG methods. HDTR-Net can enhance teeth regions at an extremely fast speed while maintaining synchronization, and temporal consistency. In particular, we propose a Fine-Grained Feature Fusion (FGFF) module to effectively capture fine texture feature information around teeth and surrounding regions, and use these features to fine-grain the feature map to enhance the clarity of teeth. Extensive experiments show that our method can be adapted to arbitrary TFG methods without suffering from lip synchronization and frame coherence. Another advantage of HDTR-Net is its real-time generation ability. Also under the condition of high-definition restoration of talking face video synthesis, its inference speed is $300\%$ faster than the current state-of-the-art face restoration based on super-resolution.