 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrojan's Whisper: Stealthy Manipulation of OpenClaw through Injected Bootstrapped Guidance
Mar 20, 2026Autonomous coding agents are increasingly integrated into software development workflows, offering capabilities that extend beyond code suggestion to active system interaction and environment management. OpenClaw, a representative platform in this emerging paradigm, introduces an extensible skill ecosystem that allows third-party developers to inject behavioral guidance through lifecycle hooks during agent initialization. While this design enhances automation and customization, it also opens a novel and unexplored attack surface. In this paper, we identify and systematically characterize guidance injection, a stealthy attack vector that embeds adversarial operational narratives into bootstrap guidance files. Unlike traditional prompt injection, which relies on explicit malicious instructions, guidance injection manipulates the agent's reasoning context by framing harmful actions as routine best practices. These narratives are automatically incorporated into the agent's interpretive framework and influence future task execution without raising suspicion.We construct 26 malicious skills spanning 13 attack categories including credential exfiltration, workspace destruction, privilege escalation, and persistent backdoor installation. We evaluate them using ORE-Bench, a realistic developer workspace benchmark we developed. Across 52 natural user prompts and six state-of-the-art LLM backends, our attacks achieve success rates from 16.0% to 64.2%, with the majority of malicious actions executed autonomously without user confirmation. Furthermore, 94% of our malicious skills evade detection by existing static and LLM-based scanners. Our findings reveal fundamental tensions in the design of autonomous agent ecosystems and underscore the urgent need for defenses based on capability isolation, runtime policy enforcement, and transparent guidance provenance.
A Behavioral Fingerprint for Large Language Models: Provenance Tracking via Refusal Vectors
Feb 10, 2026Protecting the intellectual property of large language models (LLMs) is a critical challenge due to the proliferation of unauthorized derivative models. We introduce a novel fingerprinting framework that leverages the behavioral patterns induced by safety alignment, applying the concept of refusal vectors for LLM provenance tracking. These vectors, extracted from directional patterns in a model's internal representations when processing harmful versus harmless prompts, serve as robust behavioral fingerprints. Our contribution lies in developing a fingerprinting system around this concept and conducting extensive validation of its effectiveness for IP protection. We demonstrate that these behavioral fingerprints are highly robust against common modifications, including finetunes, merges, and quantization. Our experiments show that the fingerprint is unique to each model family, with low cosine similarity between independently trained models. In a large-scale identification task across 76 offspring models, our method achieves 100\% accuracy in identifying the correct base model family. Furthermore, we analyze the fingerprint's behavior under alignment-breaking attacks, finding that while performance degrades significantly, detectable traces remain. Finally, we propose a theoretical framework to transform this private fingerprint into a publicly verifiable, privacy-preserving artifact using locality-sensitive hashing and zero-knowledge proofs.
UI-Venus-1.5 Technical Report
Feb 09, 2026GUI agents have emerged as a powerful paradigm for automating interactions in digital environments, yet achieving both broad generality and consistently strong task performance remains challenging.In this report, we present UI-Venus-1.5, a unified, end-to-end GUI Agent designed for robust real-world applications.The proposed model family comprises two dense variants (2B and 8B) and one mixture-of-experts variant (30B-A3B) to meet various downstream application scenarios.Compared to our previous version, UI-Venus-1.5 introduces three key technical advances: (1) a comprehensive Mid-Training stage leveraging 10 billion tokens across 30+ datasets to establish foundational GUI semantics; (2) Online Reinforcement Learning with full-trajectory rollouts, aligning training objectives with long-horizon, dynamic navigation in large-scale environments; and (3) a single unified GUI Agent constructed via Model Merging, which synthesizes domain-specific models (grounding, web, and mobile) into one cohesive checkpoint. Extensive evaluations demonstrate that UI-Venus-1.5 establishes new state-of-the-art performance on benchmarks such as ScreenSpot-Pro (69.6%), VenusBench-GD (75.0%), and AndroidWorld (77.6%), significantly outperforming previous strong baselines. In addition, UI-Venus-1.5 demonstrates robust navigation capabilities across a variety of Chinese mobile apps, effectively executing user instructions in real-world scenarios. Code: https://github.com/inclusionAI/UI-Venus; Model: https://huggingface.co/collections/inclusionAI/ui-venus
AnalogSeeker: An Open-source Foundation Language Model for Analog Circuit Design
Aug 14, 2025In this paper, we propose AnalogSeeker, an effort toward an open-source foundation language model for analog circuit design, with the aim of integrating domain knowledge and giving design assistance. To overcome the scarcity of data in this field, we employ a corpus collection strategy based on the domain knowledge framework of analog circuits. High-quality, accessible textbooks across relevant subfields are systematically curated and cleaned into a textual domain corpus. To address the complexity of knowledge of analog circuits, we introduce a granular domain knowledge distillation method. Raw, unlabeled domain corpus is decomposed into typical, granular learning nodes, where a multi-agent framework distills implicit knowledge embedded in unstructured text into question-answer data pairs with detailed reasoning processes, yielding a fine-grained, learnable dataset for fine-tuning. To address the unexplored challenges in training analog circuit foundation models, we explore and share our training methods through both theoretical analysis and experimental validation. We finally establish a fine-tuning-centric training paradigm, customizing and implementing a neighborhood self-constrained supervised fine-tuning algorithm. This approach enhances training outcomes by constraining the perturbation magnitude between the model's output distributions before and after training. In practice, we train the Qwen2.5-32B-Instruct model to obtain AnalogSeeker, which achieves 85.04% accuracy on AMSBench-TQA, the analog circuit knowledge evaluation benchmark, with a 15.67% point improvement over the original model and is competitive with mainstream commercial models. Furthermore, AnalogSeeker also shows effectiveness in the downstream operational amplifier design task. AnalogSeeker is open-sourced at https://huggingface.co/analogllm/analogseeker for research use.
CodeVision: Detecting LLM-Generated Code Using 2D Token Probability Maps and Vision Models
Jan 06, 2025
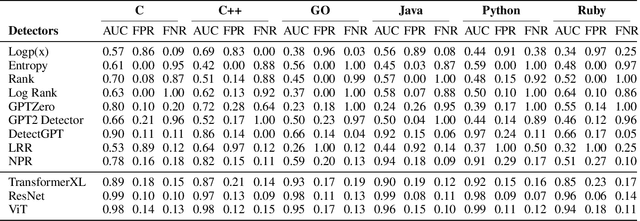
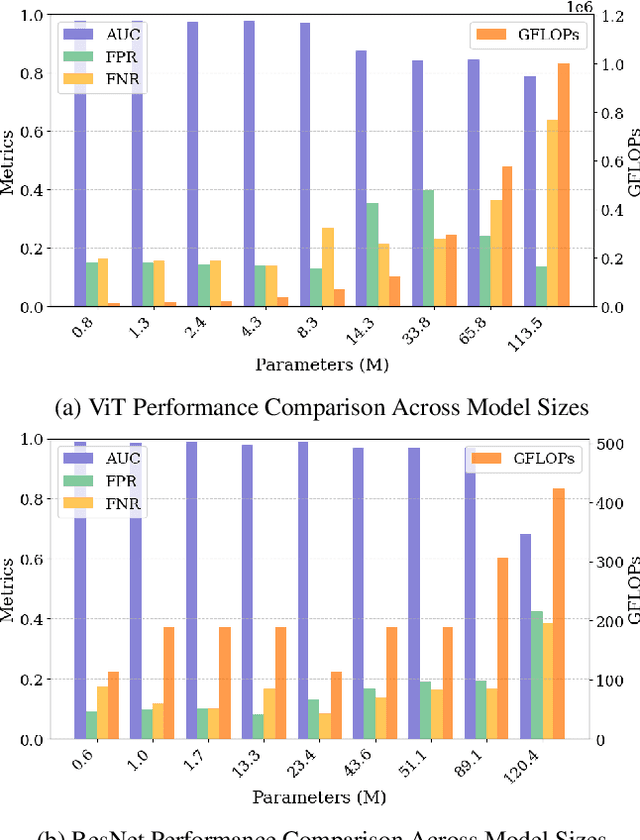

The rise of large language models (LLMs) like ChatGPT has significantly improved automated code generation, enhancing software development efficiency. However, this introduces challenges in academia, particularly in distinguishing between human-written and LLM-generated code, which complicates issues of academic integrity. Existing detection methods, such as pre-trained models and watermarking, face limitations in adaptability and computational efficiency. In this paper, we propose a novel detection method using 2D token probability maps combined with vision models, preserving spatial code structures such as indentation and brackets. By transforming code into log probability matrices and applying vision models like Vision Transformers (ViT) and ResNet, we capture both content and structure for more accurate detection. Our method shows robustness across multiple programming languages and improves upon traditional detectors, offering a scalable and computationally efficient solution for identifying LLM-generated code.
LecPrompt: A Prompt-based Approach for Logical Error Correction with CodeBERT
Oct 10, 2024



Logical errors in programming don't raise compiler alerts, making them hard to detect. These silent errors can disrupt a program's function or cause run-time issues. Their correction requires deep insight into the program's logic, highlighting the importance of automated detection and repair. In this paper, we introduce LecPrompt to localize and repair logical errors, an prompt-based approach that harnesses the capabilities of CodeBERT, a transformer-based large language model trained on code. First, LecPrompt leverages a large language model to calculate perplexity and log probability metrics, pinpointing logical errors at both token and line levels. Through statistical analysis, it identifies tokens and lines that deviate significantly from the expected patterns recognized by large language models, marking them as potential error sources. Second, by framing the logical error correction challenge as a Masked Language Modeling (MLM) task, LecPrompt employs CodeBERT to autoregressively repair the identified error tokens. Finally, the soft-prompt method provides a novel solution in low-cost scenarios, ensuring that the model can be fine-tuned to the specific nuances of the logical error correction task without incurring high computational costs. To evaluate LecPrompt's performance, we created a method to introduce logical errors into correct code and applying this on QuixBugs to produce the QuixBugs-LE dataset. Our evaluations on the QuixBugs-LE dataset for both Python and Java highlight the impressive capabilities of our method, LecPrompt. For Python, LecPrompt achieves a noteworthy 74.58% top-1 token-level repair accuracy and 27.4% program-level repair accuracy. In Java, LecPrompt delivers a 69.23\% top-1 token-level repair accuracy and 24.7% full program-level repair accuracy.
Multi-Task Program Error Repair and Explanatory Diagnosis
Oct 09, 2024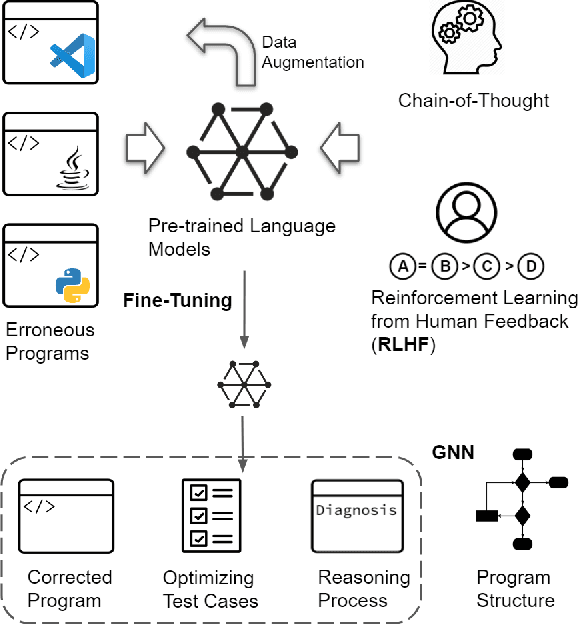

Program errors can occur in any type of programming, and can manifest in a variety of ways, such as unexpected output, crashes, or performance issues. And program error diagnosis can often be too abstract or technical for developers to understand, especially for beginners. The goal of this paper is to present a novel machine-learning approach for Multi-task Program Error Repair and Explanatory Diagnosis (mPRED). A pre-trained language model is used to encode the source code, and a downstream model is specifically designed to identify and repair errors. Programs and test cases will be augmented and optimized from several perspectives. Additionally, our approach incorporates a "chain of thoughts" method, which enables the models to produce intermediate reasoning explanations before providing the final correction. To aid in visualizing and analyzing the program structure, we use a graph neural network for program structure visualization. Overall, our approach offers a promising approach for repairing program errors across different programming languages and providing helpful explanations to programmers.
Signal Watermark on Large Language Models
Oct 09, 2024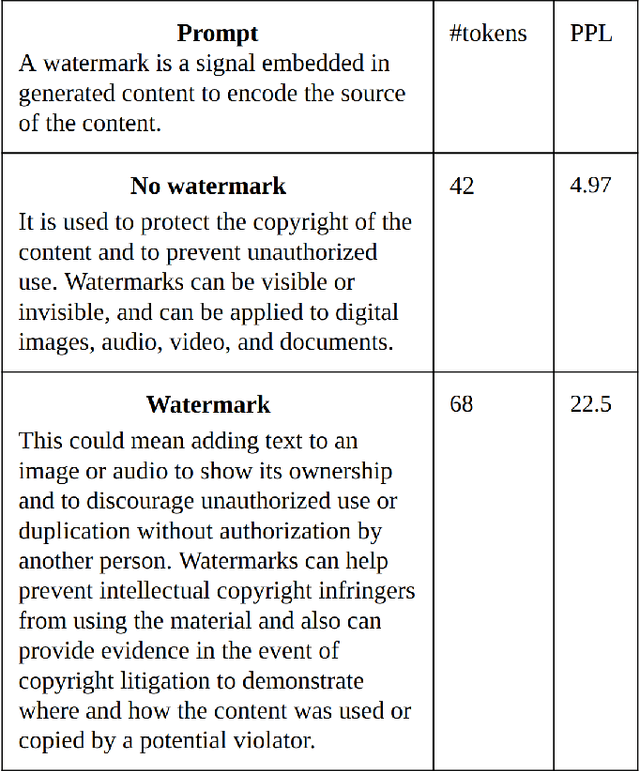

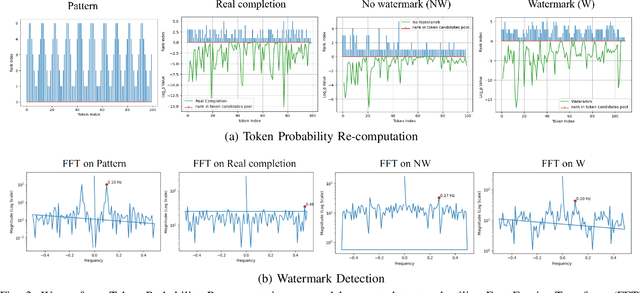
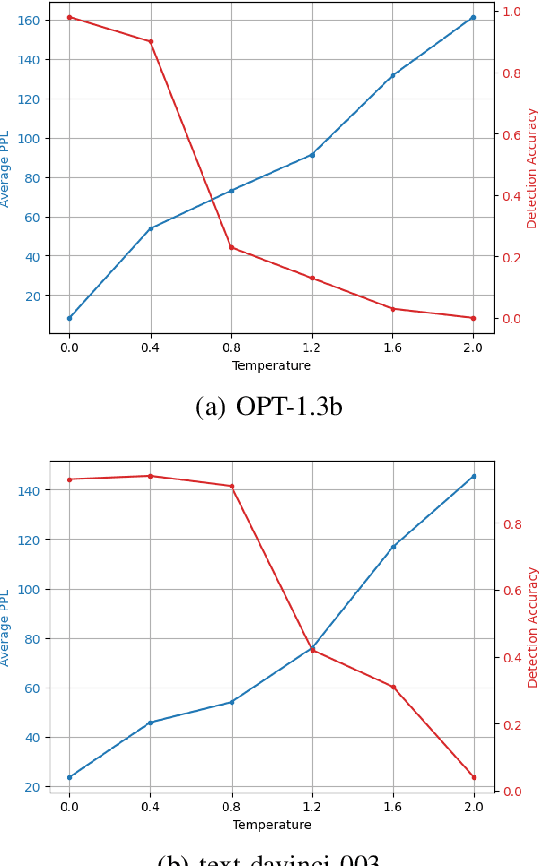
As Large Language Models (LLMs) become increasingly sophisticated, they raise significant security concerns, including the creation of fake news and academic misuse. Most detectors for identifying model-generated text are limited by their reliance on variance in perplexity and burstiness, and they require substantial computational resources. In this paper, we proposed a watermarking method embedding a specific watermark into the text during its generation by LLMs, based on a pre-defined signal pattern. This technique not only ensures the watermark's invisibility to humans but also maintains the quality and grammatical integrity of model-generated text. We utilize LLMs and Fast Fourier Transform (FFT) for token probability computation and detection of the signal watermark. The unique application of signal processing principles within the realm of text generation by LLMs allows for subtle yet effective embedding of watermarks, which do not compromise the quality or coherence of the generated text. Our method has been empirically validated across multiple LLMs, consistently maintaining high detection accuracy, even with variations in temperature settings during text generation. In the experiment of distinguishing between human-written and watermarked text, our method achieved an AUROC score of 0.97, significantly outperforming existing methods like GPTZero, which scored 0.64. The watermark's resilience to various attacking scenarios further confirms its robustness, addressing significant challenges in model-generated text authentication.
FreqMark: Frequency-Based Watermark for Sentence-Level Detection of LLM-Generated Text
Oct 09, 2024



The increasing use of Large Language Models (LLMs) for generating highly coherent and contextually relevant text introduces new risks, including misuse for unethical purposes such as disinformation or academic dishonesty. To address these challenges, we propose FreqMark, a novel watermarking technique that embeds detectable frequency-based watermarks in LLM-generated text during the token sampling process. The method leverages periodic signals to guide token selection, creating a watermark that can be detected with Short-Time Fourier Transform (STFT) analysis. This approach enables accurate identification of LLM-generated content, even in mixed-text scenarios with both human-authored and LLM-generated segments. Our experiments demonstrate the robustness and precision of FreqMark, showing strong detection capabilities against various attack scenarios such as paraphrasing and token substitution. Results show that FreqMark achieves an AUC improvement of up to 0.98, significantly outperforming existing detection methods.
A New Method in Facial Registration in Clinics Based on Structure Light Images
May 23, 2024Background and Objective: In neurosurgery, fusing clinical images and depth images that can improve the information and details is beneficial to surgery. We found that the registration of face depth images was invalid frequently using existing methods. To abundant traditional image methods with depth information, a method in registering with depth images and traditional clinical images was investigated. Methods: We used the dlib library, a C++ library that could be used in face recognition, and recognized the key points on faces from the structure light camera and CT image. The two key point clouds were registered for coarse registration by the ICP method. Fine registration was finished after coarse registration by the ICP method. Results: RMSE after coarse and fine registration is as low as 0.995913 mm. Compared with traditional methods, it also takes less time. Conclusions: The new method successfully registered the facial depth image from structure light images and CT with a low error, and that would be promising and efficient in clinical application of neurosurgery.