 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-light Stereo Image Enhancement and De-noising in the Low-frequency Information Enhanced Image Space
Jan 15, 2024Unlike single image task, stereo image enhancement can use another view information, and its key stage is how to perform cross-view feature interaction to extract useful information from another view. However, complex noise in low-light image and its impact on subsequent feature encoding and interaction are ignored by the existing methods. In this paper, a method is proposed to perform enhancement and de-noising simultaneously. First, to reduce unwanted noise interference, a low-frequency information enhanced module (IEM) is proposed to suppress noise and produce a new image space. Additionally, a cross-channel and spatial context information mining module (CSM) is proposed to encode long-range spatial dependencies and to enhance inter-channel feature interaction. Relying on CSM, an encoder-decoder structure is constructed, incorporating cross-view and cross-scale feature interactions to perform enhancement in the new image space. Finally, the network is trained with the constraints of both spatial and frequency domain losses. Extensive experiments on both synthesized and real datasets show that our method obtains better detail recovery and noise removal compared with state-of-the-art methods. In addition, a real stereo image enhancement dataset is captured with stereo camera ZED2. The code and dataset are publicly available at: https://www.github.com/noportraits/LFENet.
Non-imaging real-time detection and tracking of fast-moving objects using a single-pixel detector
Sep 10, 2021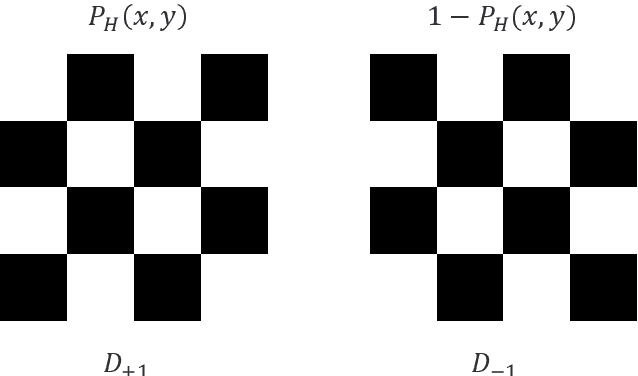

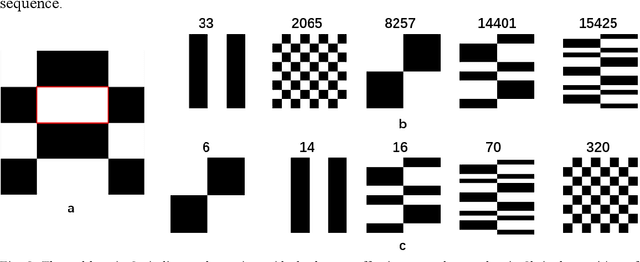
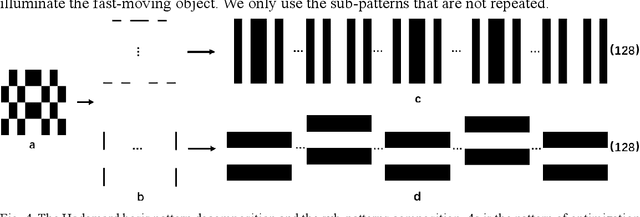
Detection and tracking of fast-moving objects have widespread utility in many fields. However, fulfilling this demand for fast and efficient detecting and tracking using image-based techniques is problematic, owing to the complex calculations and limited data processing capabilities. To tackle this problem, we propose an image-free method to achieve real-time detection and tracking of fast-moving objects. It employs the Hadamard pattern to illuminate the fast-moving object by a spatial light modulator, in which the resulting light signal is collected by a single-pixel detector. The single-pixel measurement values are directly used to reconstruct the position information without image reconstruction. Furthermore, a new sampling method is used to optimize the pattern projection way for achieving an ultra-low sampling rate. Compared with the state-of-the-art methods, our approach is not only capable of handling real-time detection and tracking, but also it has a small amount of calculation and high efficiency. We experimentally demonstrate that the proposed method, using a 22kHz digital micro-mirror device, can implement a 105fps frame rate at a 1.28% sampling rate when tracks. Our method breaks through the traditional tracking ways, which can implement the object real-time tracking without image reconstruction.
PHI-MVS: Plane Hypothesis Inference Multi-view Stereo for Large-Scale Scene Reconstruction
Apr 13, 2021


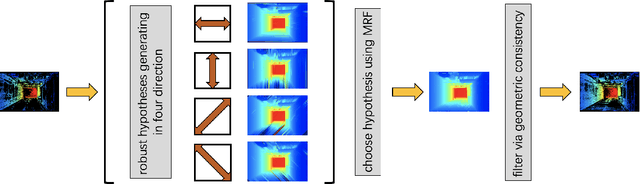
PatchMatch based Multi-view Stereo (MVS) algorithms have achieved great success in large-scale scene reconstruction tasks. However, reconstruction of texture-less planes often fails as similarity measurement methods may become ineffective on these regions. Thus, a new plane hypothesis inference strategy is proposed to handle the above issue. The procedure consists of two steps: First, multiple plane hypotheses are generated using filtered initial depth maps on regions that are not successfully recovered; Second, depth hypotheses are selected using Markov Random Field (MRF). The strategy can significantly improve the completeness of reconstruction results with only acceptable computing time increasing. Besides, a new acceleration scheme similar to dilated convolution can speed up the depth map estimating process with only a slight influence on the reconstruction. We integrated the above ideas into a new MVS pipeline, Plane Hypothesis Inference Multi-view Stereo (PHI-MVS). The result of PHI-MVS is validated on ETH3D public benchmarks, and it demonstrates competing performance against the state-of-the-art.
Learning Structral coherence Via Generative Adversarial Network for Single Image Super-Resolution
Jan 25, 2021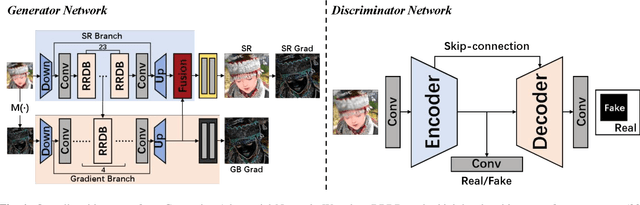


Among the major remaining challenges for single image super resolution (SISR) is the capacity to recover coherent images with global shapes and local details conforming to human vision system. Recent generative adversarial network (GAN) based SISR methods have yielded overall realistic SR images, however, there are always unpleasant textures accompanied with structural distortions in local regions. To target these issues, we introduce the gradient branch into the generator to preserve structural information by restoring high-resolution gradient maps in SR process. In addition, we utilize a U-net based discriminator to consider both the whole image and the detailed per-pixel authenticity, which could encourage the generator to maintain overall coherence of the reconstructed images. Moreover, we have studied objective functions and LPIPS perceptual loss is added to generate more realistic and natural details. Experimental results show that our proposed method outperforms state-of-the-art perceptual-driven SR methods in perception index (PI), and obtains more geometrically consistent and visually pleasing textures in natural image restoration.
Disentanglement Then Reconstruction: Learning Compact Features for Unsupervised Domain Adaptation
May 28, 2020

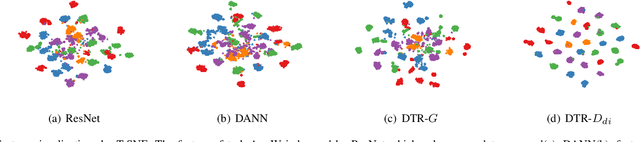

Recent works in domain adaptation always learn domain invariant features to mitigate the gap between the source and target domains by adversarial methods. The category information are not sufficiently used which causes the learned domain invariant features are not enough discriminative. We propose a new domain adaptation method based on prototype construction which likes capturing data cluster centers. Specifically, it consists of two parts: disentanglement and reconstruction. First, the domain specific features and domain invariant features are disentangled from the original features. At the same time, the domain prototypes and class prototypes of both domains are estimated. Then, a reconstructor is trained by reconstructing the original features from the disentangled domain invariant features and domain specific features. By this reconstructor, we can construct prototypes for the original features using class prototypes and domain prototypes correspondingly. In the end, the feature extraction network is forced to extract features close to these prototypes. Our contribution lies in the technical use of the reconstructor to obtain the original feature prototypes which helps to learn compact and discriminant features. As far as we know, this idea is proposed for the first time. Experiment results on several public datasets confirm the state-of-the-art performance of our method.
Study on Sparse Representation based Classification for Biometric Verification
Feb 27, 2015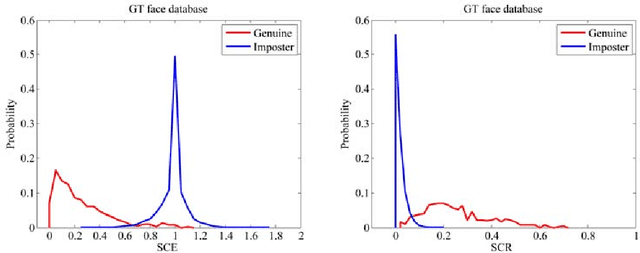

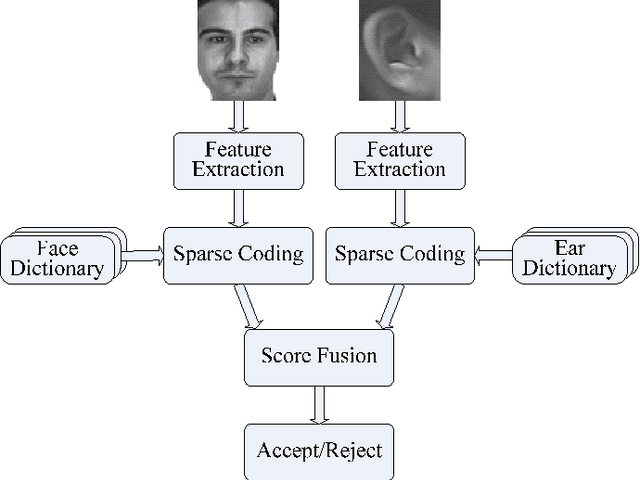
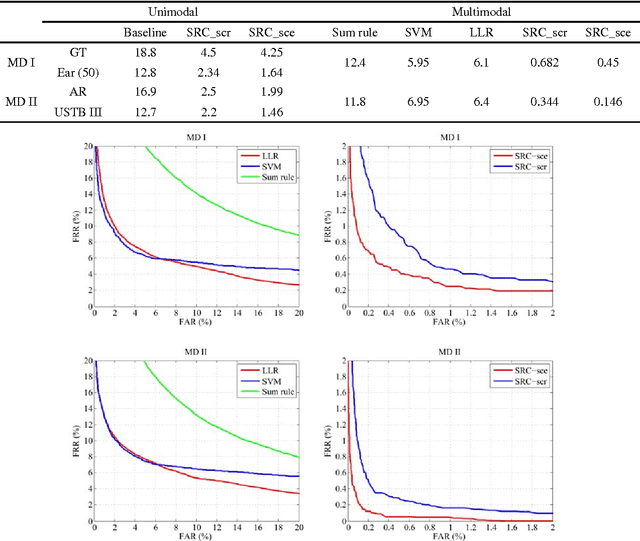
In this paper, we propose a multimodal verification system integrating face and ear based on sparse representation based classification (SRC). The face and ear query samples are first encoded separately to derive sparsity-based match scores, and which are then combined with sum-rule fusion for verification. Apart from validating the encouraging performance of SRC-based multimodal verification, this paper also dedicates to provide a clear understanding about the characteristics of SRC-based biometric verification. To this end, two sparsity-based metrics, i.e. spare coding error (SCE) and sparse contribution rate (SCR), are involved, together with face and ear unimodal SRC-based verification. As for the issue that SRC-based biometric verification may suffer from heavy computational burden and verification accuracy degradation with increase of enrolled subjects, we argue that it could be properly resolved by exploiting small random dictionary for sparsity-based score computation, which consists of training samples from a limited number of randomly selected subjects. Experimental results demonstrate the superiority of SRC-based multimodal verification compared to the state-of-the-art multimodal methods like likelihood ratio (LLR), support vector machine (SVM), and the sum-rule fusion methods using cosine similarity, meanwhile the idea of using small random dictionary is feasible in both effectiveness and efficiency.
A random algorithm for low-rank decomposition of large-scale matrices with missing entries
Nov 04, 2014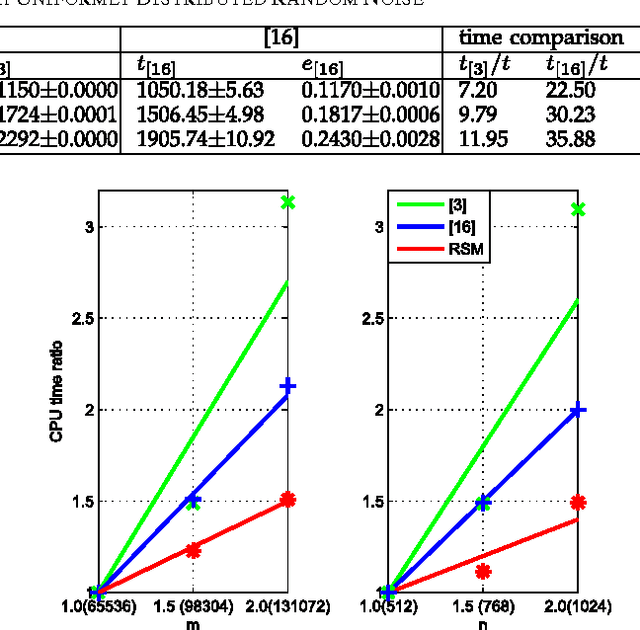

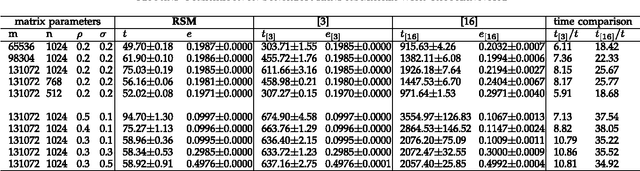
A Random SubMatrix method (RSM) is proposed to calculate the low-rank decomposition of large-scale matrices with known entry percentage \rho. RSM is very fast as the floating-point operations (flops) required are compared favorably with the state-of-the-art algorithms. Meanwhile RSM is very memory-saving. With known entries homogeneously distributed in the given matrix, sub-matrices formed by known entries are randomly selected. According to the just proved theorem that subspace related to smaller singular values is less perturbed by noise, the null vectors or the right singular vectors associated with the minor singular values are calculated for each submatrix. The vectors are the null vectors of the corresponding submatrix in the ground truth of the given large-scale matrix. If enough sub-matrices are randomly chosen, the low-rank decomposition is estimated. The experimental results on random synthetical matrices with sizes such as 131072X1024 and on real data sets indicate that RSM is much faster and memory-saving, and, meanwhile, has considerable high precision achieving or approximating to the best.