 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatchFlow: Leveraging a Flow-Based Model with Patch Features
Feb 05, 2026Die casting plays a crucial role across various industries due to its ability to craft intricate shapes with high precision and smooth surfaces. However, surface defects remain a major issue that impedes die casting quality control. Recently, computer vision techniques have been explored to automate and improve defect detection. In this work, we combine local neighbor-aware patch features with a normalizing flow model and bridge the gap between the generic pretrained feature extractor and industrial product images by introducing an adapter module to increase the efficiency and accuracy of automated anomaly detection. Compared to state-of-the-art methods, our approach reduces the error rate by 20\% on the MVTec AD dataset, achieving an image-level AUROC of 99.28\%. Our approach has also enhanced performance on the VisA dataset , achieving an image-level AUROC of 96.48\%. Compared to the state-of-the-art models, this represents a 28.2\% reduction in error. Additionally, experiments on a proprietary die casting dataset yield an accuracy of 95.77\% for anomaly detection, without requiring any anomalous samples for training. Our method illustrates the potential of leveraging computer vision and deep learning techniques to advance inspection capabilities for the die casting industry
Dynamic Topology Awareness: Breaking the Granularity Rigidity in Vision-Language Navigation
Jan 29, 2026Vision-Language Navigation in Continuous Environments (VLN-CE) presents a core challenge: grounding high-level linguistic instructions into precise, safe, and long-horizon spatial actions. Explicit topological maps have proven to be a vital solution for providing robust spatial memory in such tasks. However, existing topological planning methods suffer from a "Granularity Rigidity" problem. Specifically, these methods typically rely on fixed geometric thresholds to sample nodes, which fails to adapt to varying environmental complexities. This rigidity leads to a critical mismatch: the model tends to over-sample in simple areas, causing computational redundancy, while under-sampling in high-uncertainty regions, increasing collision risks and compromising precision. To address this, we propose DGNav, a framework for Dynamic Topological Navigation, introducing a context-aware mechanism to modulate map density and connectivity on-the-fly. Our approach comprises two core innovations: (1) A Scene-Aware Adaptive Strategy that dynamically modulates graph construction thresholds based on the dispersion of predicted waypoints, enabling "densification on demand" in challenging environments; (2) A Dynamic Graph Transformer that reconstructs graph connectivity by fusing visual, linguistic, and geometric cues into dynamic edge weights, enabling the agent to filter out topological noise and enhancing instruction adherence. Extensive experiments on the R2R-CE and RxR-CE benchmarks demonstrate DGNav exhibits superior navigation performance and strong generalization capabilities. Furthermore, ablation studies confirm that our framework achieves an optimal trade-off between navigation efficiency and safe exploration. The code is available at https://github.com/shannanshouyin/DGNav.
Neural Network-Guided Symbolic Regression for Interpretable Descriptor Discovery in Perovskite Catalysts
Jul 16, 2025Understanding and predicting the activity of oxide perovskite catalysts for the oxygen evolution reaction (OER) requires descriptors that are both accurate and physically interpretable. While symbolic regression (SR) offers a path to discover such formulas, its performance degrades with high-dimensional inputs and small datasets. We present a two-phase framework that combines neural networks (NN), feature importance analysis, and symbolic regression (SR) to discover interpretable descriptors for OER activity in oxide perovskites. In Phase I, using a small dataset and seven structural features, we reproduce and improve the known {\mu}/t descriptor by engineering composite features and applying symbolic regression, achieving training and validation MAEs of 22.8 and 20.8 meV, respectively. In Phase II, we expand to 164 features, reduce dimensionality, and identify LUMO energy as a key electronic descriptor. A final formula using {\mu}/t, {\mu}/RA, and LUMO energy achieves improved accuracy (training and validation MAEs of 22.1 and 20.6 meV) with strong physical interpretability. Our results demonstrate that NN-guided symbolic regression enables accurate, interpretable, and physically meaningful descriptor discovery in data-scarce regimes, indicating interpretability need not sacrifice accuracy for materials informatics.
Deep Rib Fracture Instance Segmentation and Classification from CT on the RibFrac Challenge
Feb 14, 2024Rib fractures are a common and potentially severe injury that can be challenging and labor-intensive to detect in CT scans. While there have been efforts to address this field, the lack of large-scale annotated datasets and evaluation benchmarks has hindered the development and validation of deep learning algorithms. To address this issue, the RibFrac Challenge was introduced, providing a benchmark dataset of over 5,000 rib fractures from 660 CT scans, with voxel-level instance mask annotations and diagnosis labels for four clinical categories (buckle, nondisplaced, displaced, or segmental). The challenge includes two tracks: a detection (instance segmentation) track evaluated by an FROC-style metric and a classification track evaluated by an F1-style metric. During the MICCAI 2020 challenge period, 243 results were evaluated, and seven teams were invited to participate in the challenge summary. The analysis revealed that several top rib fracture detection solutions achieved performance comparable or even better than human experts. Nevertheless, the current rib fracture classification solutions are hardly clinically applicable, which can be an interesting area in the future. As an active benchmark and research resource, the data and online evaluation of the RibFrac Challenge are available at the challenge website. As an independent contribution, we have also extended our previous internal baseline by incorporating recent advancements in large-scale pretrained networks and point-based rib segmentation techniques. The resulting FracNet+ demonstrates competitive performance in rib fracture detection, which lays a foundation for further research and development in AI-assisted rib fracture detection and diagnosis.
Style Generation in Robot Calligraphy with Deep Generative Adversarial Networks
Dec 15, 2023



Robot calligraphy is an emerging exploration of artificial intelligence in the fields of art and education. Traditional calligraphy generation researches mainly focus on methods such as tool-based image processing, generative models, and style transfer. Unlike the English alphabet, the number of Chinese characters is tens of thousands, which leads to difficulties in the generation of a style consistent Chinese calligraphic font with over 6000 characters. Due to the lack of high-quality data sets, formal definitions of calligraphy knowledge, and scientific art evaluation methods, The results generated are frequently of low quality and falls short of professional-level requirements. To address the above problem, this paper proposes an automatic calligraphy generation model based on deep generative adversarial networks (deepGAN) that can generate style calligraphy fonts with professional standards. The key highlights of the proposed method include: (1) The datasets use a high-precision calligraphy synthesis method to ensure its high quality and sufficient quantity; (2) Professional calligraphers are invited to conduct a series of Turing tests to evaluate the gap between model generation results and human artistic level; (3) Experimental results indicate that the proposed model is the state-of-the-art among current calligraphy generation methods. The Turing tests and similarity evaluations validate the effectiveness of the proposed method.
Study of Subjective and Objective Quality Assessment of Mobile Cloud Gaming Videos
May 26, 2023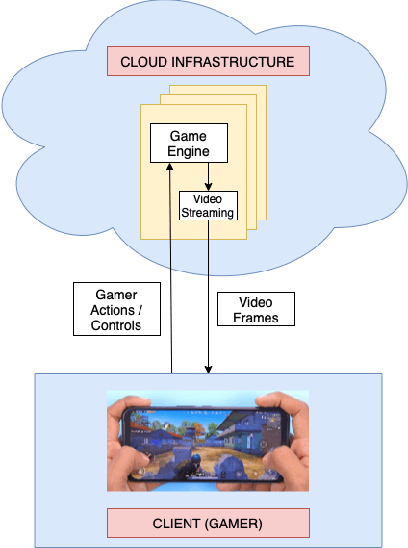
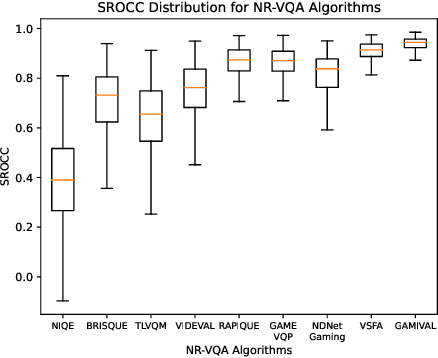
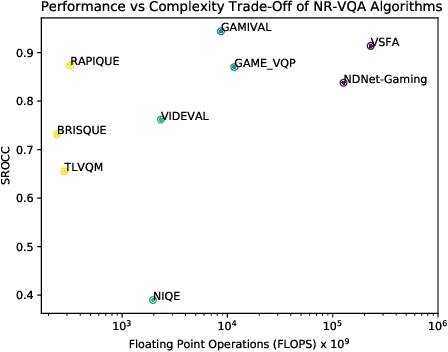
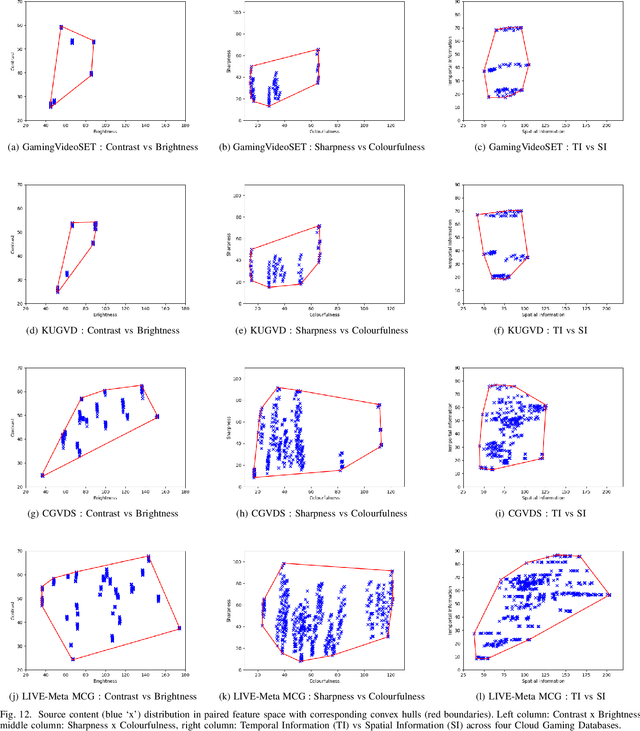
We present the outcomes of a recent large-scale subjective study of Mobile Cloud Gaming Video Quality Assessment (MCG-VQA) on a diverse set of gaming videos. Rapid advancements in cloud services, faster video encoding technologies, and increased access to high-speed, low-latency wireless internet have all contributed to the exponential growth of the Mobile Cloud Gaming industry. Consequently, the development of methods to assess the quality of real-time video feeds to end-users of cloud gaming platforms has become increasingly important. However, due to the lack of a large-scale public Mobile Cloud Gaming Video dataset containing a diverse set of distorted videos with corresponding subjective scores, there has been limited work on the development of MCG-VQA models. Towards accelerating progress towards these goals, we created a new dataset, named the LIVE-Meta Mobile Cloud Gaming (LIVE-Meta-MCG) video quality database, composed of 600 landscape and portrait gaming videos, on which we collected 14,400 subjective quality ratings from an in-lab subjective study. Additionally, to demonstrate the usefulness of the new resource, we benchmarked multiple state-of-the-art VQA algorithms on the database. The new database will be made publicly available on our website: \url{https://live.ece.utexas.edu/research/LIVE-Meta-Mobile-Cloud-Gaming/index.html}
GAMIVAL: Video Quality Prediction on Mobile Cloud Gaming Content
May 12, 2023The mobile cloud gaming industry has been rapidly growing over the last decade. When streaming gaming videos are transmitted to customers' client devices from cloud servers, algorithms that can monitor distorted video quality without having any reference video available are desirable tools. However, creating No-Reference Video Quality Assessment (NR VQA) models that can accurately predict the quality of streaming gaming videos rendered by computer graphics engines is a challenging problem, since gaming content generally differs statistically from naturalistic videos, often lacks detail, and contains many smooth regions. Until recently, the problem has been further complicated by the lack of adequate subjective quality databases of mobile gaming content. We have created a new gaming-specific NR VQA model called the Gaming Video Quality Evaluator (GAMIVAL), which combines and leverages the advantages of spatial and temporal gaming distorted scene statistics models, a neural noise model, and deep semantic features. Using a support vector regression (SVR) as a regressor, GAMIVAL achieves superior performance on the new LIVE-Meta Mobile Cloud Gaming (LIVE-Meta MCG) video quality database.
* Accepted to IEEE SPL 2023. The implementation of GAMIVAL has been made available online: https://github.com/lskdream/GAMIVAL
Golfer: Trajectory Prediction with Masked Goal Conditioning MnM Network
Jul 02, 2022
Transformers have enabled breakthroughs in NLP and computer vision, and have recently began to show promising performance in trajectory prediction for Autonomous Vehicle (AV). How to efficiently model the interactive relationships between the ego agent and other road and dynamic objects remains challenging for the standard attention module. In this work we propose a general Transformer-like architectural module MnM network equipped with novel masked goal conditioning training procedures for AV trajectory prediction. The resulted model, named golfer, achieves state-of-the-art performance, winning the 2nd place in the 2022 Waymo Open Dataset Motion Prediction Challenge and ranked 1st place according to minADE.
Fully Convolutional One-Stage 3D Object Detection on LiDAR Range Images
May 27, 2022



We present a simple yet effective fully convolutional one-stage 3D object detector for LiDAR point clouds of autonomous driving scenes, termed FCOS-LiDAR. Unlike the dominant methods that use the bird-eye view (BEV), our proposed detector detects objects from the range view (RV, a.k.a. range image) of the LiDAR points. Due to the range view's compactness and compatibility with the LiDAR sensors' sampling process on self-driving cars, the range view-based object detector can be realized by solely exploiting the vanilla 2D convolutions, departing from the BEV-based methods which often involve complicated voxelization operations and sparse convolutions. For the first time, we show that an RV-based 3D detector with standard 2D convolutions alone can achieve comparable performance to state-of-the-art BEV-based detectors while being significantly faster and simpler. More importantly, almost all previous range view-based detectors only focus on single-frame point clouds, since it is challenging to fuse multi-frame point clouds into a single range view. In this work, we tackle this challenging issue with a novel range view projection mechanism, and for the first time demonstrate the benefits of fusing multi-frame point clouds for a range-view based detector. Extensive experiments on nuScenes show the superiority of our proposed method and we believe that our work can be strong evidence that an RV-based 3D detector can compare favourably with the current mainstream BEV-based detectors.
Study on Sparse Representation based Classification for Biometric Verification
Feb 27, 2015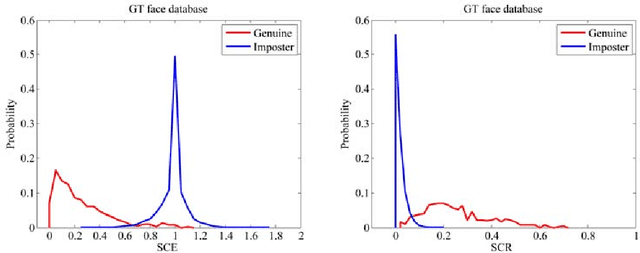

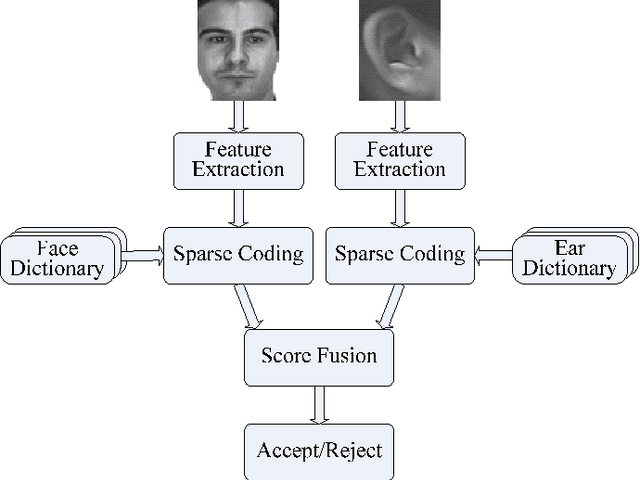
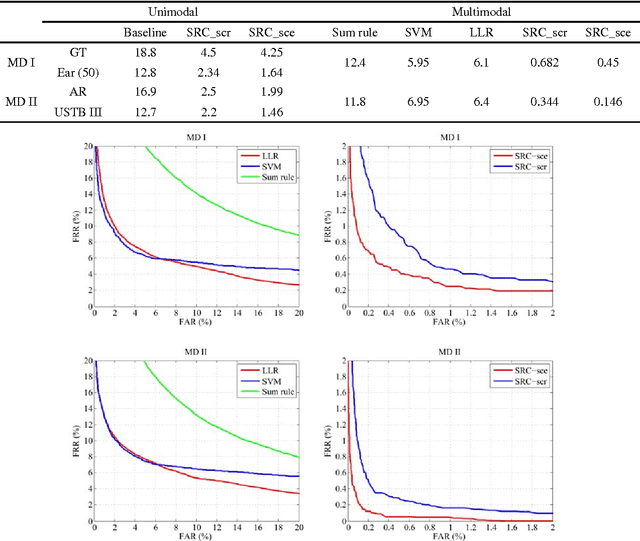
In this paper, we propose a multimodal verification system integrating face and ear based on sparse representation based classification (SRC). The face and ear query samples are first encoded separately to derive sparsity-based match scores, and which are then combined with sum-rule fusion for verification. Apart from validating the encouraging performance of SRC-based multimodal verification, this paper also dedicates to provide a clear understanding about the characteristics of SRC-based biometric verification. To this end, two sparsity-based metrics, i.e. spare coding error (SCE) and sparse contribution rate (SCR), are involved, together with face and ear unimodal SRC-based verification. As for the issue that SRC-based biometric verification may suffer from heavy computational burden and verification accuracy degradation with increase of enrolled subjects, we argue that it could be properly resolved by exploiting small random dictionary for sparsity-based score computation, which consists of training samples from a limited number of randomly selected subjects. Experimental results demonstrate the superiority of SRC-based multimodal verification compared to the state-of-the-art multimodal methods like likelihood ratio (LLR), support vector machine (SVM), and the sum-rule fusion methods using cosine similarity, meanwhile the idea of using small random dictionary is feasible in both effectiveness and efficiency.